MySQL必知必会详细总结
一.检索数据
1.检索单个列:SELECT prod_name FROM products;
2.检索多个列:SELECT prod_id,prod_name,prod_price FROM products;
3.检索所有列:SELECT * FROM products;
4.检索不同的行:SELECT DISTINCT vend_id FROM products;
5.限制结果:SELECT prod_nameFROM products LIMIT 5,5;
6.使用完全限定的表名:SELECT products.prod_name FROM products;
二.排序检索数据
1.排序数据:SELECT prod_name FROM products ORDER BY prod_name;
2.按多个列排序:SELECT prod_id,prod_price,prod_name FROM products ORDER BY prod_price,prod_name;
3.指定排序方向
降序:SELECT prod_id,prod_price,prod_name FROM products ORDER BY prod_price DESC;
升序:SELECT prod_id,prod_price,prod_name FROM products ORDER BY prod_price ASC;
三.过滤数据
1.使用WHERE子句:SELECT prod_name,prod_price FROM products WHERE prod_price = 2.50;
2.WHERE子句操作符

SELECT prod_name,prod_price FROM products WHERE prod_price < 10;
SELECT prod_name,prod_price FROM products WHERE prod_price <= 10;
SELECT vend_id,prod_name FROM products WHERE vend_id 1003;
SELECT vend_id,prod_name FROM products WHERE vend_id != 1003;
SELECT prod_name,prod_price FROM products WHERE prod_price BETWEEN 5 AND 10;
SELECT prod_name FROM products WHERE prod_price IS NULL;
四.数据过滤
1.组合WHERE子句
(1)AND操作符:SELECT prod_id,prod_price,prod_name FROM products WHERE vend id = 1003 AND prod_price <= 10;
(2)OR操作符:SELECT prod_name,prod_price FROM products WHERE vend_id = 1002 OR vend_id = 1003;
(3)计算次序:例如SELECT prod_name,prod_price FROM products WHERE vend_id = 1002 OR vend_id = 1003 AND prod_price >= 10;先执行AND再执行OR
2.IN操作符:SELECT prod_name,prod_price FROM products WHERE vend_id IN (1002,1003)ORDER BY prod_name;
3.NOT操作符:SELECT prod_name,prod_price FROM products WHERE vend_id NOT IN (1002,1003)ORDER BY prod_name;
五.用通配符进行过滤
1.LIKE操作符
(1).百分号(%)通配符:SELECT prod_id,prod_name FROM products WHERE prod_name LIKE 'jet%' ;
(2).下划线(_)通配符(匹配单个字符):SELECT prod_id,prod_name FROM products WHERE prod_name LIKE '_ ton anvil ';
2.使用通配符的技巧
不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
六.用正则表达式进行搜索
1.基本字符匹配(包含文本1000):SELECT prod_name FROM products WHERE prod_name REGEXP '1000'ORDER BY prod_name;
2.进行OR匹配:SELECT prod_name FROM products WHERE prod_name REGEXP '1000| 2000' ORDER BY prod_name;
3.匹配几个字符之一:SELECT prod_name FROM products WHERE prod_name REGEXP '[123] Ton' ORDER BY prod_name;
4.匹配范围:SELECT prod_name FROM products WHERE prod_name REGEXP '[1-5]Ton' ORDER BY prod_name;
5.匹配特殊字符:SELECT vend_name FROM vendors WHERE vend_name REGEXP '\ \.' ORDER BY vend_name;
6.匹配字符类:

7.匹配多个实例

例:SELECT prod_name FROM products WHERE prod_name REGEXP '\\([0-9] sticks?\ \)' ORDER BY prod_name;
8.定位符

例:SELECT prod_name FROM products WHERE prod_name REGEXP '^[0-9\\.]' ORDER BY prod_name;
七.创建计算字段
1.拼接字段Concat(显示vend_name(vend_country)格式):SELECT Concat(vend_name,' ( ', vend_country,') ') FROM vendors ORDER BY vend_name;
2.执行算术计算:SELECT prod_id,quantity,item_price,quantity*item_price As expanded_price FROM orderitems WHERE order_num = 20005;
八.使用数据处理函数
1.文本处理函数


2.日期和时间处理函数

例如查询order_date为2005-09-01的数据:SELECT cust_id,order_num FROM orders WHERE Date(order_date) = '2005-09-01';
3.数值处理函数
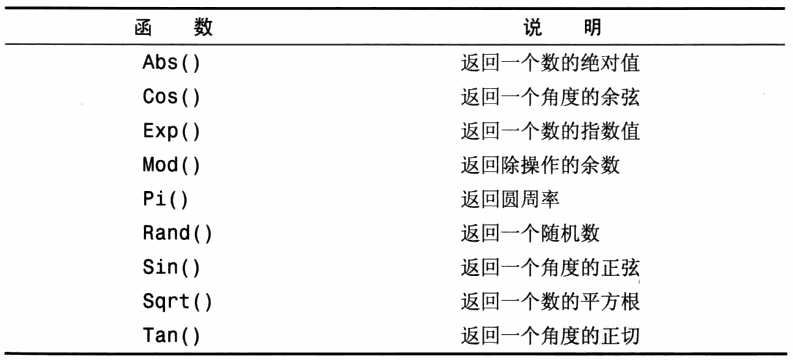
九.汇总数据
1.聚集函数

(1).AVG()函数:SELECT AVG(prod_price) AS avg _price FROM products;
(2).COUNT()函数:SELECT COUNT(*) AS num__cust FROM customers;
使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。
使用COUNT ( column)对特定列中具有值的行进行计数,忽略NULL值。
(3).MAX函数:SELECT MAX(prod_price) AS max_price FROM products;
(4).MIN函数:SELECT MIN(prod_price) AS min_price FROM products;
(5).SUM函数:SELECT SUM(quantity) AS items_ordered FROM orderitems WHERE order_num = 20005;
2.聚集不同值DISTINCT(计算不同价格的平均数):SELECT AVG(DISTINCT prod_price) As avg_price FROM products WHERE vend_id = 1003;
3.组合聚集函数:SELECT COUNT(*) AS num_items, MIN(prod_price) AS price_min,MAX(prod_price) AS price_max,AVG(prod_price) AS price_avg FROM products;
十.分组数据
1.创建分组:SELECT vend_id,COUNT(*) AS num_prods FROM products GROUP BY vend_id;
2.过滤分组:SELECT cust_id,COUNT(*) AS orders FROM orders GROUP BY cust_id HAVING COUNT(*) >= 2;
3.分组和排序:SELECT order_num,SUM(quantity*item_price) AS ordertotal FROM orderitems GROUP BY order_num HAVING SUM(quantity*i tem_price) >= 50 ORDER BY ordertotal;
十一.使用子查询
1.利用子查询进行过滤
SELECT cust_name,cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id = 'TNT2'));
2.作为计算字段使用子查询:SELECT cust_name,cust_state, (SELECT COUNT(*) FROM orders WHERE orders.cust_id = customers.cust_id) AS orders FROM customers ORDER BY cust_name;
十二.联结表
1.创建联结:SELECT vend_name,prod_name,prod_price FROM vendors,products WHERE vendors.vend_id = products.vend_id ORDER BY vend_name,prod_name;
十三.创建高级索引
1.外部联结(LEFT OUTER J0IN)
SELECT customers.cust_id,orders.order_num FROM customers LEFT OUTER J0IN orders ON customers.cust_id = orders.cust_id;
SELECT customers.cust_id,orders.order_num FROM customers RIGHT OUTER JOIN orders ON orders.cust_id = customers.cust_id;
2.使用带聚集函数的联结
SELECT customers.cust_name, customers.cust_id, COUNT(orders.order_num) AS num_ord FROM customers INNER J0IN orders ON customers.cust_id = orders.cust_id GROUP BY customers.cust_id;
十四.组合查询
1.使用UNION(去除重复行)
SELECT vend_id,prod_id,prod_price FROM products WHERE prod_price <= 5
UNION
SELECT vend_id,prod_id,prod_price FROM products WHERE vend_id IN (1001,1002);
2.使用UNION ALL(可以重复)
SELECT vend_id,prod_id,prod_price FROM products WHERE prod_price <= 5
UNION ALL
SELECT vend_id,prod_id,prod_price FROM products WHERE vend_id IN (1001,1002);
3.对组合查询结果排序:在用UNION组合查询时,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后。
SELECT vend_id,prod_id,prod_price FROM products
WHERE prod_price <= 5UNION
SELECT vend_id,prod_id,prod_price FROM products
WHERE vend_id IN (1001,1002) ORDER BY vend_id,prod_price;
十五.全文本搜索
1.启用全文本搜索支持(FULLTEXT)
CREATE TABLE productnotes(
note_id int NOT NULL AUTO_INCREMENT ,
prod_id char(10) NOT NULL,
note_date datetime NOT NULL,
note_text text NULL ,
PRIMARY KEY(note_id),
FULLTEXT(note_text))
ENGINE=MyISAM;
2.进行全文本搜索(Match()指定被搜索的列,Against()指定要使用的搜索表达式)
SELECT note_text FROM productnotes WHERE Match(note_text) Against( ' rabbit');
3.使用查询扩展
SELECT note_text FROM productnotes WHERE Match(note_text) Against( 'anvils' WITH QUERY EXPANSION);
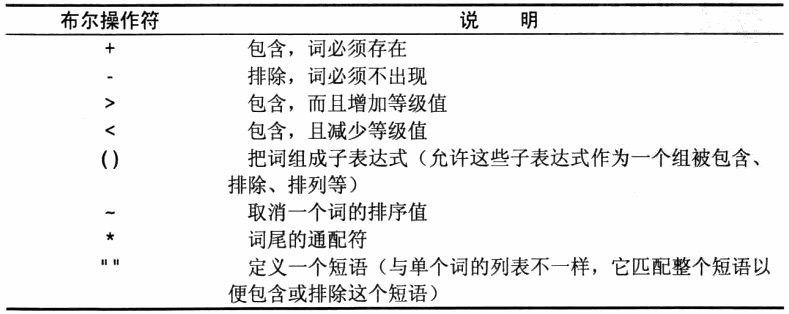
4.布尔文本搜索
匹配包含heavy:SELECT note_text FROM productnotes WHERE Match(note_text) Against( 'heavy' IN BOOLEAN MODE);
匹配包含heavy但不包含任意以rope开始的词的行:SELECT note_text FROM productnotes WHERE Match(note_text) Against( 'heavy -rope*' IN BOOLEAN MODE);
全文本布尔操作符:
十六.插入数据
1.插入完整的行:INSERT INTO customers (cust__name,cust_address,cust_city,cust_state,cust_zip,cust_country ,cust_contact,cust_emai1) VALUES( 'Pep E. LaPew ' ,'100 Main Street','Los Angeles','CA','90046','USA' ,NULL,NULL);
2.插入多个行
INSERT INTO customers(cust_name,cust_address,cust_city,cust_state,cust_zip,cust_country)
VALUES('Pep E. LaPew ' ,'100 Main Street' ,'Los Angeles','CA','90046','USA'),
('M. Martian ' ,'42 Galaxy way ' ,'New York ' ,'NY','11213','USA');
3.插入检索出的数据
INSERT INTO customers(cust_id,cust_contact,cust__emai1,cust_name,cust_address,cust_city,cust_state,cust_zip,cust__country)
SELECT cust_id,cust_contact,cust_emai1,cust_name,cust_address,cust_city,cust_state,cust_zip,cust_countryFROM custnew;
十七.更新和删除数据
1.更新数据:UPDATE customers SET cust_email = 'e1mer@fudd. com' WHERE cust_id = 10005;
2.删除数据:DELETE FROM customersWHERE cust_id = 10006;
十八.创建和操作表
1.创建表基础
CREATE TABLE customers(
cust_id int NOT NULL AUTO_INCREMENT,
cust_namechar(50)NOT NULL ,
cust_address char(50) NULL ,
cust_citychar(50) NULL ,cust_statechar(5) NULL ,cust_zip
char(10) NULL ,
cust_country char(50) NULL ,
cust_contact char(50) NULL ,
cust_emai1char(255) NULL ,
PRIMARY KEY (cust_id)
) ENGINE=InnoDB;
2.使用AUTO_INCREMENT:cust_id int NOT NULL AUTO_INCREMENT ,
3.添加一列:ALTER TABLE vendors ADD vend_phone CHAR(20);
4.删除一列:ALTER TABLE VendorsDROP COLUMN vend_phone;
5.删除表:DROP TABLE customers2 ;
6.重命名表:RENAME TABLE customers2 TO customers;
十八.使用视图
理解视图的最好方法是看一个例子:
SELECT cust_name,cust_contact FROM customers,orders,orderitems
WHERE customers.cust_id = orders.cust_id
AND orderitems.order_num = orders.order_num AND prod_id = 'TNT2 ';
此查询用来检索订购了某个特定产品的客户。任何需要这个数据的人都必须理解相关表的结构,并且知道如何创建查询和对表进行联结。为了检索其他产品(或多个产品)的相同数据,必须修改最后的WHERE子句。
现在,假如可以把整个查询包装成一个名为productcustomers的虚拟表,则可以如下轻松地检索出相同的数据:
SELECT cust_name,cust_contact FROM productcustomers WHERE prod_id = 'TNT2';
1.创建视图
CREATE VIEW productcustomers AS
SELECT cust_name,cust_contact,prod_id FROM customers,orders,orderitems
WHERE customers.cust_id = orders.cust_id
AND orderitems.order_num = orders.order_num;
十九.使用存储过程
存储过程简单来说,就是为以后的使用而保存的一条或多条MySQL语句的集合。
1.执行存储过程:CALL productpricing(@pricelow,@pricehigh,@priceaverage);
其中,执行名为productpricing的存储过程,它计算并返回产品的最低、最高和平均价格。
2.创建存储过程
CREATE PROCEDURE productpricing()
BEGIN
SELECT Avg(prod_price) AS priceaverage FROM products;
END;
我此存储过程名为productpricing,用CREATE PROCEDURE productpricing( )语句定义。如果存储过程接受参数,它们将在()中列举出来。此存储过程没有参数,但后跟的()仍然需要。BEGIN和END语句用来限定存储过程体,过程体本身仅是一个简单的SELECT语句。
使用:CALL productpricing();
3.删除存储过程:DROP PROCEDURE productpricing;
4.使用参数
一般,存储过程并不显示结果,而是把结果返回给你指定的变量。
CREATE PROCEDURE productpricing(
OUT pl DECIMAL(8,2),
OUT ph DECIMAL(8,2),
OUT pa DECIMAL(8,2)
)
BEGIN
SELECT Min(prod_price) INTO pl
FROM products;
SELECT Max(prod_price) INTO ph
FROM products;
SELECT Avg(prod_price) INTO pa
FROM products;
END;
此存储过程接受3个参数:pl存储产品最低价格,ph存储产品最高价格,pa存储产品平均价格。每个参数必须具有指定的类型,这里使用十进制值。关键字OUT指出相应的参数用来从存储过程传出一个值(返回给调用者)。MySQL支持IN(传递给存储过程)、OUT(从存储过程传出,如这里所用)和INOUT(对存储过程传入和传出)类型的参数。存储过程的代码位于BEGIN和END语句内,如前所见,它们是一系列SELECT语句,用来检索值,然后保存到相应的变量(通过指定INTO关键字)。
调用:CALL productpricing(@pricelow,@pricehigh,@priceaverage);
SELECT @pricehigh,@pricelow,@priceaverage;
5.建立智能存储过程
CREATE PROCEDURE ordertotal(
IN onumber INT,
IN taxable BOOLEAN,
OUT otota1 DECIMAL(8,2)
) COMMENT ‘0btain order total, optiona1ly adding tax'
BEGIN
-- Declare variable for total
DECLARE total DECIMAL(8,2);
-- Declare tax percentage
DECLARE taxrate INT DEFAULT 6;
-- Get the order total
SELECT Sum(item_price*quantity)
FROM orderitems
WHERE order_num = onumber
INTO total;
-- Is this taxab1e?
IF taxable THEN
-- Yes,so add taxrate to the total
SELECT total+(total/100*taxrate) INTO total;
END IF;
-- And final1y,save to out variable
SELECT total INTO ototal;
END;
此存储过程有很大的变动。首先,增加了注释(前面放置--)。在存储过程复杂性增加时,这样做特别重要。添加了另外一个参数taxable,它是一个布尔值(如果要增加税则为真,否则为假)。在存储过程体中,用DECLARE语句定义了两个局部变量。DECLARE要求指定变量名和数据类型,它也支持可选的默认值(这个例子中的taxrate的默认被设置为6%)。SELECT语句已经改变,因此其结果存储到total(局部变量)而不是ototal。IF语句检查taxable是否为真,如果为真,则用另一SELECT语句增加营业税到局部变量total。最后,用另一SELECT语句将total (它增加或许不增加营业税)保存到ototal。
调用:CALL ordertotal(20005,o,@total);
6.检查存储过程:SHOW CREATE PROCEDURE ordertotal;
十九.使用游标
游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。
1.创建游标
CREATE PROCEDURE processorders()
BEGIN
DECLARE ordernumbers CURSOR
FOR
SELECT order_num FROM orders;
END;
2.打开和关闭游标
OPEN ordernumbers;
CLOSE ordernumbers;
3.例子


在这个例子中,我们增加了另一个名为t的变量(存储每个订单的合计)。此存储过程还在运行中创建了一个新表(如果它不存在的话),名为ordertotals。这个表将保存存储过程生成的结果。FETCH像以前一样取每个order_num,然后用CALL执行另一个存储过程来计算每个订单的带税的合计(结果存储到t)。最后,用INSERT保存每个订单的订单号和合计。
二十.使用触发器
1.创建触发器:CREATE TRIGGER newproduct AFTER INSERT ON products FOR EACH ROw SELECT 'Product added ' ;

2.删除触发器:DROP TRIGGER newproduct;
MySQL必知必会详细总结的更多相关文章
- 《MySQL必知必会》整理
目录 第1章 了解数据库 1.1 数据库基础 1.1.1 什么是数据库 1.1.2 表 1.1.3 列和数据类型 1.1.4 行 1.1.5 主键 1.2 什么是SQL 第2章 MySQL简介 2.1 ...
- 读《MySql必知必会》笔记
MySql必知必会 2017-12-21 意义:记录个人不注意的,或不明确的,或不知道的细节方法技巧,此书250页 登陆: mysql -u root-p -h myserver -P 9999 SH ...
- 《MySQL必知必会》学习笔记——前言
前言 MySQL已经成为世界上最受欢迎的数据库管理系统之一.无论是用在小型开发项目上,还是用来构建那些声名显赫的网站,MySQL都证明了自己是个稳定.可靠.快速.可信的系统,足以胜任任何数据存储业务的 ...
- MySQL必知必会:组合查询(Union)
MySQL必知必会:组合查询(Union) php mysqlsql 阅读约 8 分钟 本篇文章主要介绍使用Union操作符将多个SELECT查询组合成一个结果集.本文参考<Mysql ...
- MySQL必知必会(第4版)整理笔记
参考书籍: BookName:<SQL必知必会(第4版)> BookName:<Mysql必知必会(第4版)> Author: Ben Forta 说明:本书学习笔记 1.了解 ...
- 《mysql 必知必会》 速查指南
目录 增 添加一整行 插入多行 删 删除指定行 删除所有行 改 查 简单检索 结果筛选 结果排序 结果过滤 创建字段 处理函数 数据分组 其他高级用法 文章内容均出自 <MySQL 必知必会&g ...
- 《MySQL必知必会》过滤数据,数据过滤(where ,in ,null ,not)
<MySQL必知必会>过滤数据,数据过滤 1.过滤数据 1.1 使用 where 子句 在SEL ECT语句中,数据根据WHERE子句中指定的搜索条件进行过滤. WHERE子句在表名(FR ...
- 【MySQL 基础】MySQL必知必会
MySQL必知必会 简介 <MySQL必知必会>的学习笔记和总结. 书籍链接 了解SQL 数据库基础 什么是数据库 数据库(database):保存有组织的数据的容器(通常是一个文 件或一 ...
- 《MySQL 必知必会》读书总结
这是 <MySQL 必知必会> 的读书总结.也是自己整理的常用操作的参考手册. 使用 MySQL 连接到 MySQL shell>mysql -u root -p Enter pas ...
- mysql学习--mysql必知必会1
例如以下为mysql必知必会第九章開始: 正則表達式用于匹配特殊的字符集合.mysql通过where子句对正則表達式提供初步的支持. keywordregexp用来表示后面跟的东西作为正則表達式 ...
随机推荐
- TIP/Collision-Free Video Synopsis Incorporating Object Speed and Size Changes Code
代码地址 https://github.com/scutlzk/Collision-Free-Video-Synopsis-Incorporating-Object-Speed-and-Size-C ...
- Spring源码之Bean生命周期
https://www.jianshu.com/p/1dec08d290c1 https://www.cnblogs.com/zrtqsk/p/3735273.html 总结 将class文件加载成B ...
- Spring源码之@Lazy和预实例化
https://www.cnblogs.com/yanze/p/10243348.html 懒加载优缺点 优点:懒加载,对象使用的时候才去创建:启动速度快,节省资源 缺点:不利于提前发现错误:初次请求 ...
- Python_scrapyRedis零散
1. # Redis 1.解压,配环境变量 2.win上设置自启动 redis-server --service-install D:\redis\redis.windows.conf --logle ...
- Python_网络编程_socket()
什么是 Socket? Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯. 详细资 ...
- Python_教程_使用Visual Studio Code开发Django项目
如何获得 Visual Studio Code 访问 http://code.visualstudio.com 下载并安装. 前提条件 安装Python 2.7 及 Python 3.5,Window ...
- DP中环形处理 +(POJ 1179 题解)
DP中环形处理 对于DP中存在环的情况,大致有两种处理的方法: 对于很多的区间DP来说,很常见的方法就是把原来的环从任意两点断开(注意并不是直接删掉这条边),在复制一条一模一样的链在这条链的后方,当做 ...
- 不要再说不会Spring了!Spring第一天,学会进大厂!
工作及面试的过程中,作为Java开发,Spring环绕在我们的身边,很多人都是一知半解,本次将用14天时间,针对容器中注解.组件.源码进行解读,AOP概念进行全方面360°无死角介绍,SpringMV ...
- 从 Webpack 到 Snowpack, 编译速度提升十倍以上——TRPG Engine迁移小记
动机 TRPG Engine经过长久以来的迭代,项目已经显得非常臃肿了.数分钟的全量编译, 每次按下保存都会触发一次10s到1m不等的增量编译让我苦不堪言, 庞大的依赖使其每一次编译都会涉及很多文件和 ...
- [head first 设计模式] 第一章 策略模式
[head first 设计模式] 第一章 策略模式 让我们先从一个简单的鸭子模拟器开始讲起. 假设有个简单的鸭子模拟器,游戏中会出现各种鸭子,此系统的原始设计如下,设计了一个鸭子超类,并让各种鸭子继 ...