MySQL InnoDB技术内幕:内存管理、事务和锁
前面有多篇文章介绍过MySQL InnoDB的相关知识,今天我们要更深入一些,看看它们的内部原理和机制是如何实现的。
一、内存管理
我们知道,MySQl是一个存储系统,数据最后都写在磁盘上。我们以前也提到过,磁盘的速度特别是大容量的磁盘受磁头臂的影响,速度相对内存慢很多。所以Innodb实现了自己的缓存机制。
首先我们先看下Innodb对内存是如何使用和划分的,然后我们再看看它是如何保存热数据的。
1、主要模块和组成
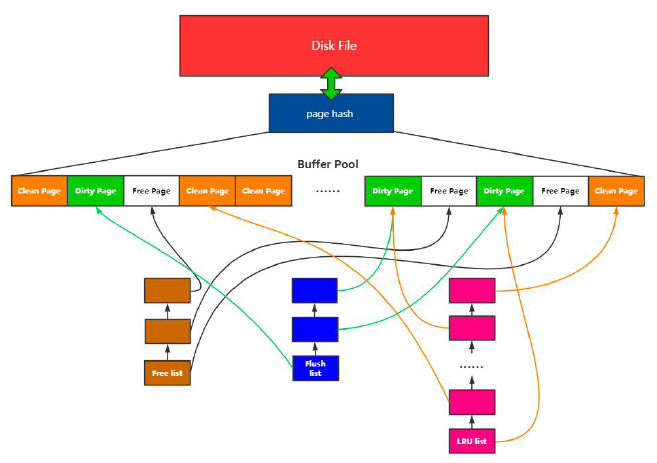
(1) Buffer Pool
预分配的内存池
(2) Page
Buffer Pool的最小单位
(3) Free list
空闲Page组成的链表
(4) Flush list
脏页链表
(5) Page hash 表
维护内存Page和文件Page的映射关系
(6) LRU
内存淘汰算法
以上三种链表LRU list、Free list、Flush list 和内存池、Page hash 以及磁盘文件之间的映射关系如下图所示:
2、LRU算法
LRU,Least Recent Used,最近最少使用。每次将刚使用过的页面插到LRU队列的最前端,那么最少使用的排在尾端,当缓存不够时,淘汰尾端的页。
很多文件系统和开源库的内存淘汰算法都用到了LRU,以前有不少文章都提到过。
但是LRU的缺陷是,有时会无法淘汰真正的冷数据,尾端的数据可能暂时没使用而已,不代表不使用频繁,不代表不是热数据。所以很多系统对LRU进行了优化。
比如Redis加了LFU(least frequently used最不经常使用)配合LRU一起使用。
那么InnoDB存储引擎是如何改进的呢?如下图,它将LRU分成两部分,中间的分割点叫做midpoint,新读取的页不再是加入到最头部,而是midpoint后面的位置,即后半截的头部。
那么midpoint的位置是如何计算的呢,在默认配置下,离LRU整个头部的5/8处。当然这个比例是可以根据实际业务进行设置的。但总之,可以真正将冷热数据分离,热数据在前,冷数据在后。
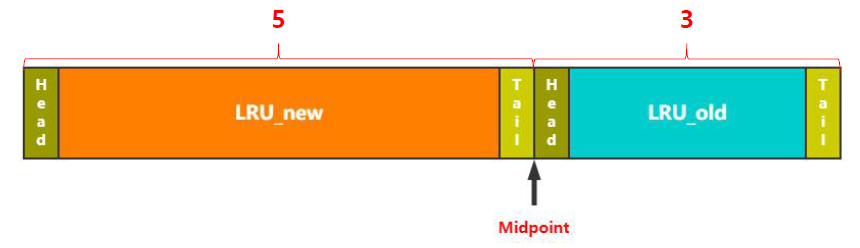
那么这两个区的数据如何移动的呢,即冷热数据如何切换的呢?
上面我们提到了,刚插入的页放在old区的头部,那么如果该页确实访问频繁,不能一直呆在该位置吧。
InnoDB引入了参数innodb_old_blocks_time,如果old区的数据在该时间范围内没有被淘汰出去,就可以移到new区,加入到new区的头部。这也叫做made young。
而如果在old呆的时间不够innodb_old_blocks_time,而且缓存不够时,就会面临直接淘汰,这就叫做made not young。这种情况,可以发生在全表扫描的时候,保证了new区的数据才是真正的热数据!
当然数据也有可能从new区移动到old区,只是相对比较简单了,直接移动midpoint指向的位置即可。即new区的尾巴变成了old区的头部。
二、事务
1、MySQL事务基本概念
事务特性
A(Atomicity原子性):全部成功或全部失败
I(Isolation隔离性):并行事务之间互不干扰
D(Durability持久性):事务提交后,永久生效
C(Consistency一致性):通过AID保证
并发问题
脏读(Drity Read):读取到未提交的数据。中间所有变化的值都可能读到。
不可重复读(Non-repeatable read):两次读取结果不同。读取已提交的(不一样的值),读到的值变化数量比脏读要少。
幻读(Phantom Read):select 操作得到的结果所表征的数据状态影响(无法支撑)后续的业务操作。
网上有人这样区分,脏读是读取修改的数据,幻读是读取新提交的数据。我认为也可以,或许phantom表示虚幻的新数据(所以无法支撑后续操作),而drity代表了修改的意思呢?
所以,不可重复读重点在于update和delete,而幻读的重点在于insert。
隔离级别
Read Uncommitted(读取未提交内容):最低隔离级别,会读取到其他事务未提交的数据;存在脏读的问题。
Read Committed(读取提交内容):事务过程中可以读取到其他事务已提交的数据;存在不可重复读的问题。
Repeatable Read(可重复读):每次读取相同结果集,不管其他事务是否提交;存在幻读的问题。
Serializable(串行化):事务排队,隔离级别最高,性能最差。
2、MySQL事务实现原理
从上我们可以看出事务有ACID四大特性,而“I”隔离性是通过锁来实现的,我们下一节讲述。那么其他三个特性主要通过undo/redo日志的机制来实现,这个知识点在前面有一篇文章中介绍和对比过。现在我们站在事务实现的角度再来看看。
(1)undo log
回滚日志,顾名思义,是对事物rollback时使用。这是它核心的功能之一,但是它还有另一个非常重要的功能,MVCC。所以今天这里主要介绍它是如何在事务中发挥作用的。
MVCC
Multiversion concurrency control,多版本并发控制。当用户读取一行时,如果该记录已经被其他事务占用,当前事务可以通过undo读取之前的行版本信息(快照数据),以此实现非锁定读。所以实现了非阻塞的读操作,写操作也只锁定必要的行。即解决读-写冲突。
快照数据就是当前行数据的历史版本,每行记录可能含有多个版本。那该读取哪个版本呢?
首先,InnoDB的每行记录或者说每条数据,除了记录用户定义的列之外,还有两个隐藏的列:事务ID列DB_TRX_ID和回滚指针DB_ROLL_PTR。如果该表没有定义主键,每行还会增加一个rowid列。DB_TRX_ID是当时执行这条sql的事务id,DB_ROLL_PTR指向的就是undo log中修改前的行DB_ROW_ID。所以对同一条数据的修改,通过roll_pointer就形成了undo log版本链。
然后我们再来介绍下Read View快照读。
一般情况下读取数据时会生成一个Read View,对当前该行的可能正在进行的事务进行一个快照。
Read View中主要包含4个比较重要的内容:
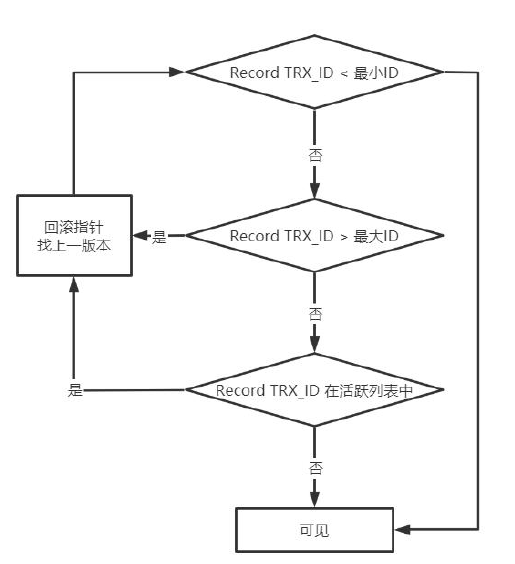
m_ids:表示在生成Read View时当前系统中活跃的读写事务的事务id列表,简称活跃列表。
min_trx_id:表示在生成Read View时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。
max_trx_id:表示生成Read View时系统中应该分配给下一个事务的id值,,也就是m_ids中的最大值。
creator_trx_id:表示生成该Read View的事务的事务id。

有了这些信息,这样在访问某条记录时,只需要依次判断undo log版本链中节点的事务ID是否可见,如果可见即找到了所需要的行记录。
最后,READ COMMITTED和REPEATABLE READ两种隔离级别对于快照数据生成的时机不一样。
对于RC,在每次查询语句执行的过程中,都关闭Read View, 再创建当前的一份Read View。这样就会产生不可重复读现象。
对于RR,创建事务trx结构的时候,就生成了当前的global Read View,一直维持到事务结束。在事务结束这段时间内每一次查询都不会重新重建Read View,从而实现了可重复读。
undo log分为两种格式,处理不一样。
insert undo log:用于回滚,提交即清理;不需要进行purge操作。
update undo log:用于回滚,同时实现快照读,不能随便删除,所以需要等待purge线程来判断何时删除。它记录的是对delete和update的操作产生的undo log。
注:以上来自书上的说法,网上有人把第一种说成delete undo log,包括insert和delete操作,供参考。
还需要补充一点的是,update undo log怎样去清理,应该是根据系统活跃的Read view中最小的活跃事务ID之前的即可清除。
(2)redo log
redo日志其实在《MySQL的undo/redo日志和binlog日志,以及2PC》文章中介绍比较多,也提到了XA事务的2PC。我们这里简单介绍下普通事务的流程。

写入流程仍然可以分为两步,类似二阶段提交:
记录页的修改,状态为prepare
事务提交,讲事务记录为commit状态
三、锁
1、InnoDB锁种类
(1) 类型
共享锁(S)
读锁,可以同时被多个事务获取,阻止其他事务对记录的修改。
排他锁(X)
写锁,只能被一个事务获取,允许获得锁的事务修改数据。
而读其实又可以分为当前读(锁定读)和快照读(非锁定读),而快照读通过上一节描述的MVCC来实现。
当前读, 读取的是最新版本,所以需要对读取的记录加锁,阻塞其他事务改动该记录。当前读又分为两种方式:
select...for update,对读取的行加X锁;
select...lock in share mode,对读取的行加S锁。
(2)锁粒度
行级锁
Record Lock,单个记录上的锁。
锁直接加在索引记录上面,锁住的是key,所以必须是聚簇索引或者二级索引是唯一索引。
间隙锁
Gap Lock,间隙锁,锁定一个范围,单不包含记录本身。
InnoDB存储引擎的隔离级别默认是Repeatable Read,所以引入了间隙锁解决可重复读模式下的幻读问题。
GAP锁不是加在记录上,锁住的位置是两条记录之间的GAP;保证两次当前读返回一致的记录。
所以两次当前读之前,其他的事务不会插入新的满足条件的记录。
我们来整理下着两者的关系和区别。
Record Lock针对的是索引必须具备唯一性;而GAP锁针对的是索引不具备唯一性但需要保证可重复读,也就是说如果发现数据有被其他事务修改的可能,那就把前后间隙都加上锁。
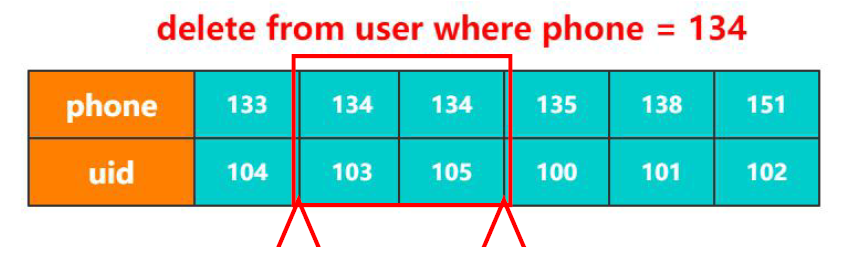
比如说如下图,有个用户表,uid为主键,那么就只需要103这条记录加上行锁即可。

但是如果我们变化下查询条件(phone列上建立了二级索引),则除了对于这两条记录加锁外,对前后的间隙也需要加锁。当然这种情况是针对RR的隔离级别,如果隔离级别是RC或者更低,安全性就没有这么高,系统会自动降级到行锁。
Next-Key Lock,是Record Lock与Gap Lock的一个结合。理解了上述两种锁的原理,对于它而言就很容易了。
表级锁
Table Lock,锁定整张表。
主要用在运维的时候,对表格进行操作比如MDL或者元数据的操作(meta data lock)等等。
当然有些情况下会触发锁升级:全表扫描。全表扫描的触发一般情况下是当前被查询的字段没有建立任何索引。
而表级锁事实上是对所有记录和所有的间隙都加上锁。
所以全表扫描的效率非常低,要尽量避免。
2、InnoDB加锁过程
如下图,当我们更新多条数据时,是一行一行的加锁。
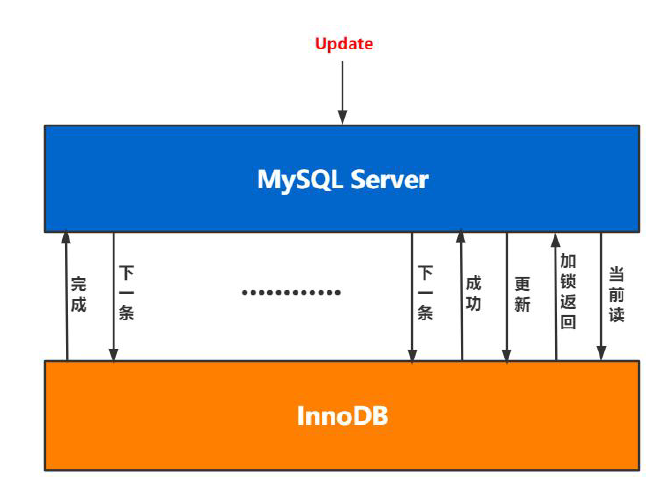
所以当同时出现对多条记录交叉查询时,很容易出现AB-BA死锁,如下图操作。

附录
分库分表的建议:
是否分表
建议单表不超过1KW
分表方式
取模:存储均匀&访问均匀
按时间:冷热库
分库
按业务垂直分
水平查分多个库
参考:
《MySQL技术内幕InnoDB存储引擎》
内部培训资料
MySQL InnoDB技术内幕:内存管理、事务和锁的更多相关文章
- Mysql Innodb 引擎优化-内存、日志、IO、其他相关参数
介绍: InnoDB给MySQL提供了具有提交,回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎.InnoDB锁定在行级并且也在SELECT语句提供一个Oracle风格一致的非锁定读.这些特色增加 ...
- MySQL Innodb如何找出阻塞事务源头SQL
在MySQL数据库中出现了阻塞问题,如何快速查找定位问题根源?在实验开始前,我们先梳理一下有什么工具或命令查看MySQL的阻塞,另外,我们也要一一对比其优劣,因为有些命令可能在实际环境下可能并不适用. ...
- SQL SERVER技术内幕之10 事务并发
1.事务 1.1事务的定义 事务是作为单个工作单元而执行的一系列操作.定义事务边界有显式和隐式两种.显式事务的定义以BEGIN TRAN作为开始,以COMMIT TRAN提交事务,以ROLLBACK ...
- MySQL系列:innodb源代码分析之内存管理
在innodb中实现了自己的内存池系统和内存堆分配系统,在innodb的内存管理系统中,大致分为三个部分:基础的内存块分配管理.内存伙伴分配器和内存堆分配器.innodb定义和实现内存池的主要目的是提 ...
- mysql内存管理
1 内存管理结构 mysql有自己的内存申请和释放机制 mysql层有mem_root innodb层有mem_heap,mem_pool,buf_pool 它们的结构图如下 2 mem_root m ...
- Linux 内核开发 - 内存管理
1.1什么是内存管理 内存管理是对计算机内存进行分配和使用的技术.内存管理主要存在于多任务的操作系统中,因为内存资源极其有限.须要在不同的任务之间共享内存,内存管理的存在就是要高效.高速的非配内存,并 ...
- 事务特性,事务的隔离级别,并发事务可能出现的问题,spring事务 数据库锁
1.0 事务特性(ACID) Atomicity:原子性,一个事务不可以被拆分 Consistency:一致性,在事务执行前数据库的数据处于正确的状态,而事务执行完成后数据库的数据还是处于正确的状态, ...
- MySQL技术内幕InnoDB存储引擎(七)——事务
什么是数据库的事务? 事务是访问并更新数据库中各种数据的一个程序执行单元.事务也是数据库区别于文件系统的一个重要特性. 事务需要满足的特性 1.原子性 原子性就是指数据库中的一个完整的事务是不可分割的 ...
- (转)Mysql技术内幕InnoDB存储引擎-事务&备份&性能调优
事务 原文:http://yingminxing.com/mysql%E6%8A%80%E6%9C%AF%E5%86%85%E5%B9%95innodb%E5%AD%98%E5%82%A8%E5%BC ...
随机推荐
- JSOI2016 病毒感染(动态规划)
题目传送门:洛谷P5774 思路来源:郭大佬(我就是凑不要脸的白嫖党 : P) 题目分析: 我们一点点来分析这道题: 起点固定为1号,所有村庄是按线性排列的,而不是图,所以我们应该用线性DP(废话 ) ...
- 一文搞定 Spring Data JPA
Spring Data JPA 是在 JPA 规范的基础上进行进一步封装的产物,和之前的 JDBC.slf4j 这些一样,只定义了一系列的接口.具体在使用的过程中,一般接入的是 Hibernate 的 ...
- Redis哨兵集群创建脚本--v1
基础环境 操作系统版本 CentOS Linux release 7.6.1810 (Core) Docker 版本 19.03.11, build 42e35e61f3 Redis 版本 3 ...
- Django---进阶11
目录 django中间件 如何自定义中间件 csrf跨站请求伪造 如何符合校验 csrf相关装饰器 补充知识点 重要思想 作业 django中间件 """ django中 ...
- 仿Neo4j里的知识图谱,利用d3+vue开发的一个网络拓扑图
项目需要画一个类似知识图谱的节点关系图. 一开始用的是echart画的. 根据https://gallery.echartsjs.com/editor.html?c=xH1Rkt3hkb,成功画出简单 ...
- 521我发誓读完本文,再也不会担心Spring配置类问题了
当大潮退去,才知道谁在裸泳.关注公众号[BAT的乌托邦]开启专栏式学习,拒绝浅尝辄止.本文 https://www.yourbatman.cn 已收录,里面一并有Spring技术栈.MyBatis.中 ...
- Python 字符串改变
在Python中,字符串是不可变类型,即无法直接修改字符串的某一位字符. 因此改变一个字符串的元素需要新建一个新的字符串. 常见的修改方法有以下4种. 方法1:将字符串转换成列表后修改值,然后用joi ...
- CTF_show平台 web题解 part3
web13 题目显示文件上传,各类型上传均提示错误,在使用ctf-scan扫描的时候,发现upload.php.bak. 查看源码: <?php header("content-typ ...
- 输入Javac提示不是内部或外部命令怎么办
首先,我们在电脑上面找到此电脑, 然后右键点击,选择属性. 在属性中,我们找到高级系统设置,点击打开,如图示. 然后在系统设置中,我们可以找到启动和鼓掌恢复,然后点击环境变量,点击打开. ...
- 深入理解JVM(③)再谈线程安全
前言 我们在编写程序的时候,一般是有个顺序的,就是先实现再优化,并不是所有的牛P程序都是一次就写出来的,肯定都是不断的优化完善来持续实现的.因此我们在考虑实现高并发程序的时候,要先保证并发的正确性,然 ...