Hadoop框架:DataNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里
一、工作机制
1、基础描述
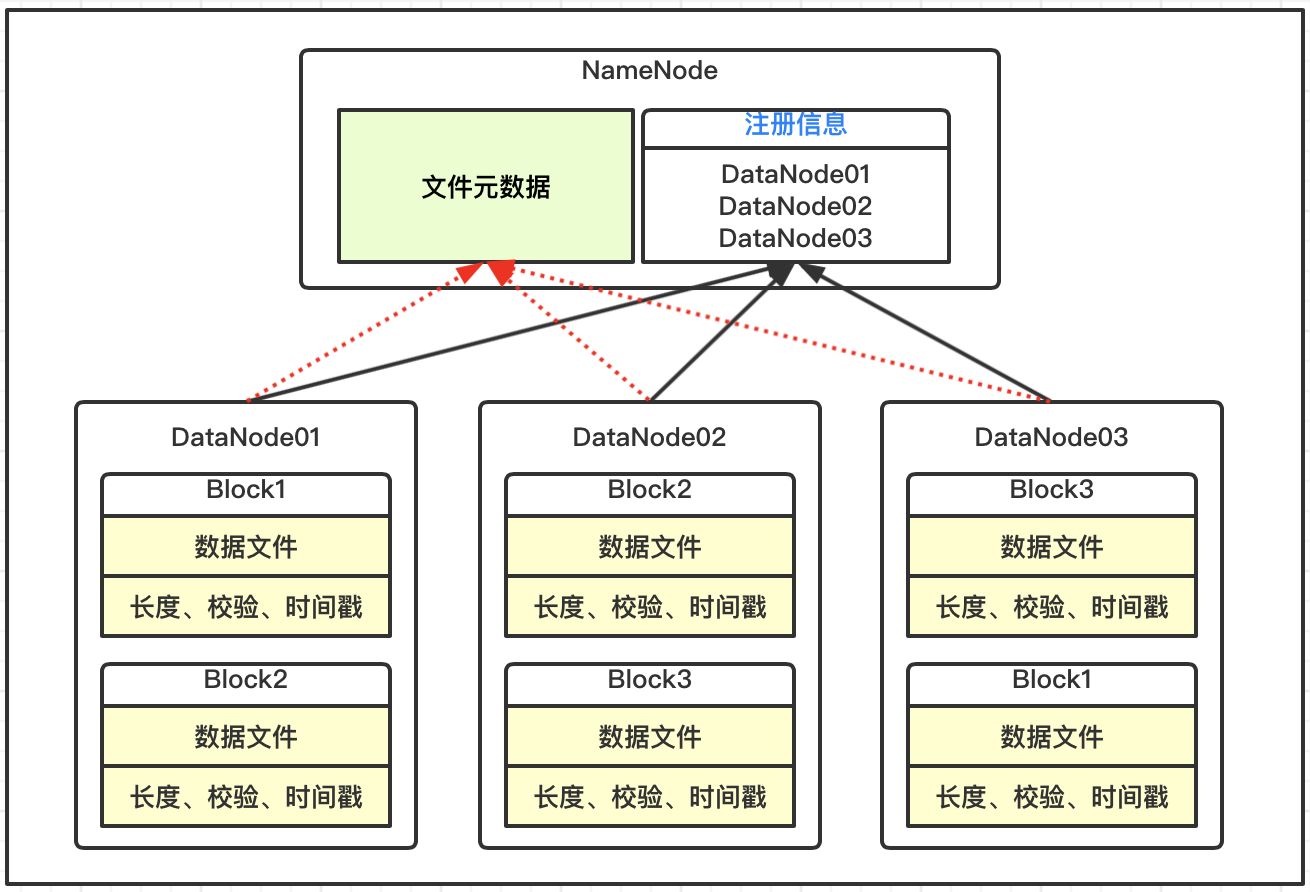
DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度、校验、时间戳;
DataNode启动后向NameNode服务注册,并周期性的向NameNode上报所有的数据块元数据信息;
DataNode与NameNode之间存在心跳机制,每3秒一次,返回结果带有NameNode给该DataNode的执行命令,例如数据复制删除等,如果超过10分钟没有收到DataNode的心跳,则认为该节点不可用。
2、自定义时长
通过hdfs-site.xml配置文件,修改超时时长和心跳,其中中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>600000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>6</value>
</property>
3、新节点上线
当前机器的节点为hop01、hop02、hop03,在此基础上新增节点hop04。
基本步骤
基于当前一个服务节点克隆得到hop04环境;
修改Centos7相关基础配置,并删除data和log文件;
启动DataNode,即可关联到集群;
4、多目录配置
该配置同步集群下服务,格式化启动hdfs及yarn,上传文件测试。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data01,file:///${hadoop.tmp.dir}/dfs/data02</value>
</property>
二、黑白名单配置
1、白名单设置
配置白名单,该配置分发到集群服务下;
[root@hop01 hadoop]# pwd
/opt/hadoop2.7/etc/hadoop
[root@hop01 hadoop]# vim dfs.hosts
hop01
hop02
hop03
配置hdfs-site.xml,该配置分发到集群服务下;
<property>
<name>dfs.hosts</name>
<value>/opt/hadoop2.7/etc/hadoop/dfs.hosts</value>
</property>
刷新NameNode
[root@hop01 hadoop2.7]# hdfs dfsadmin -refreshNodes
刷新ResourceManager
[root@hop01 hadoop2.7]# yarn rmadmin -refreshNodes
2、黑名单设置
配置黑名单,该配置分发到集群服务下;
[root@hop01 hadoop]# pwd
/opt/hadoop2.7/etc/hadoop
[root@hop01 hadoop]# vim dfs.hosts.exclude
hop04
配置hdfs-site.xml,该配置分发到集群服务下;
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/hadoop2.7/etc/hadoop/dfs.hosts.exclude</value>
</property>
刷新NameNode
[root@hop01 hadoop2.7]# hdfs dfsadmin -refreshNodes
刷新ResourceManager
[root@hop01 hadoop2.7]# yarn rmadmin -refreshNodes
三、文件存档
1、基础描述
HDFS存储的特点,适合海量数据的大文件,如果每个文件都很小,会产生大量的元数据信息,占用过多的内存,并且在NaemNode和DataNode交互的时候变的缓慢。
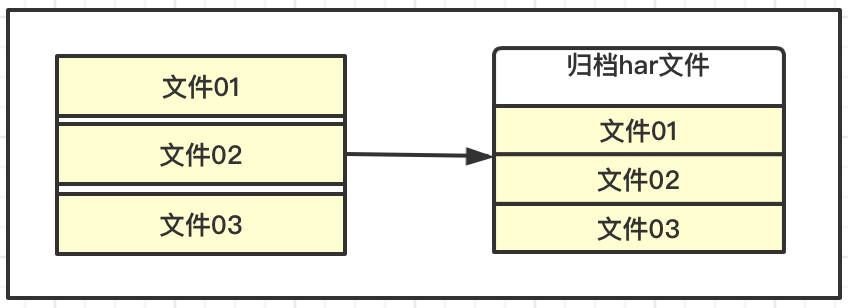
HDFS可以对一些小的文件进行归档存储,这里可以理解为压缩存储,即减少NameNode的消耗,也较少交互的负担,同时还允许对归档的小文件访问,提高整体的效率。
2、操作流程
创建两个目录
# 存放小文件
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/harinput
# 存放归档文件
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/haroutput
上传测试文件
[root@hop01 hadoop2.7]# hadoop fs -moveFromLocal LICENSE.txt /hopdir/harinput
[root@hop01 hadoop2.7]# hadoop fs -moveFromLocal README.txt /hopdir/harinput
归档操作
[root@hop01 hadoop2.7]# bin/hadoop archive -archiveName output.har -p /hopdir/harinput /hopdir/haroutput
查看归档文件
[root@hop01 hadoop2.7]# hadoop fs -lsr har:///hopdir/haroutput/output.har

这样就可以把原来的那些小文件块删除即可。
解除归档文件
# 执行解除
[root@hop01 hadoop2.7]# hadoop fs -cp har:///hopdir/haroutput/output.har/* /hopdir/haroutput
# 查看文件
[root@hop01 hadoop2.7]# hadoop fs -ls /hopdir/haroutput
四、回收站机制
1、基础描述
如果开启回收站功能,被删除的文件在指定的时间内,可以执行恢复操作,防止数据被误删除情况。HDFS内部的具体实现就是在NameNode中启动一个后台线程Emptier,这个线程专门管理和监控系统回收站下面的文件,对于放进回收站的文件且超过生命周期,就会自动删除。
2、开启配置
该配置需要同步到集群下的所有服务;
[root@hop01 hadoop]# vim /opt/hadoop2.7/etc/hadoop/core-site.xml
# 添加内容
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
fs.trash.interval=0,表示禁用回收站机制,=1表示开启。
五、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
推荐阅读:编程体系整理
| 序号 | 项目名称 | GitHub地址 | GitEE地址 | 推荐指数 |
|---|---|---|---|---|
| 01 | Java描述设计模式,算法,数据结构 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 02 | Java基础、并发、面向对象、Web开发 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆ |
| 03 | SpringCloud微服务基础组件案例详解 | GitHub·点这里 | GitEE·点这里 | ☆☆☆ |
| 04 | SpringCloud微服务架构实战综合案例 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 05 | SpringBoot框架基础应用入门到进阶 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆ |
| 06 | SpringBoot框架整合开发常用中间件 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 07 | 数据管理、分布式、架构设计基础案例 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 08 | 大数据系列、存储、组件、计算等框架 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
Hadoop框架:DataNode工作机制详解的更多相关文章
- Hadoop框架:NameNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.存储机制 1.基础描述 NameNode运行时元数据需要存放在内存中,同时在磁盘中备份元数据的fsImage,当元数据有更新或者添加元数据 ...
- Session的工作机制详解和安全性问题(PHP实例讲解)
我们先简单的了解一些http的知识,从而理解该协议的无状态特性.然后,学习一些关于cookie的基本操作.最后,我会一步步阐述如何使用一些简单,高效的方法来提高你的php应用程序的安全性以及稳定行. ...
- JVM结构、GC工作机制详解
JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JVM结构 根据<java虚拟机规范>规定,JVM的基本结构一般如下图所示: 从左图可知,JVM主要包括四个部分 ...
- JVM结构、GC工作机制详解(转)
原文地址:http://blog.csdn.NET/tonytfjing/article/details/44278233 JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JV ...
- 【转载】JVM结构、GC工作机制详解
文章主要分为以下四个部分 JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JVM结构 根据<java虚拟机规范>规定,JVM的基本结构一般如下图所示: 从左图可知, ...
- 【系统之音】WindowManager工作机制详解
前言 目光所及,皆有Window!Window,顾名思义,窗口,它是应用与用户交互的一个窗口,我们所见到视图,都对应着一个Window.比如屏幕上方的状态栏.下方的导航栏.按音量键调出来音量控制栏.充 ...
- NIO组件Selector工作机制详解(下)
转自:http://blog.csdn.net/haoel/article/details/2224069 五. 迷惑不解 : 为什么要自己消耗资源? 令人不解的是为什么我们的Java的New I/ ...
- NIO组件Selector工作机制详解(上)
转自:http://blog.csdn.net/haoel/article/details/2224055 一. 前言 自从J2SE 1.4版本以来,JDK发布了全新的I/O类库,简称NIO,其不但 ...
- JVM、Gc工作机制详解
JVM主要包括四个部分: 类加载器(ClassLoad) 执行引擎 内存区: 本地方法接口:类似于jni调本地native方法 内存区包括四个部分: 1.方法区:包含了静态变量.常量池.构造函数等 2 ...
随机推荐
- charles常用功能 request和response(简单的操作)
先介绍一个修改request请求参数值的方法吧 第一步: 拷贝完成后还需要配置一下: 先添加一个: 然后下一步: 最后点击OK,就可以开始操作request和response数据了 先修改reques ...
- openstack共享组件——Memcache 缓存系统(4)
云计算openstack共享组件——Memcache 缓存系统(4) 一.缓存系统 一.静态web页面: 1.在静态Web程序中,客户端使用Web浏览器(IE.FireFox等)经过网络(Netw ...
- Anaconda使用及管理
接下来均是以命令行模式进行介绍,Windows用户请打开"Anaconda Prompt":macOS和Linux用户请打开"Terminal"("终 ...
- 12.扩展:向量空间模型算法(Vector Space Model)
- Win10使用VMWare15安装Ubuntu-18.04.2-desktop-amd64
本文在Win10系统中使用VMWare Workstation Pro 15.1.0虚拟机安装Ubuntu-18.04.2-desktop-amd64.iso系统,同时安装VMWare Tools(实 ...
- 趣图:这是拿offer极高的面试经验
扩展阅读 趣图:面试谈薪资就要这种底气 趣图:IT培训出来找工作 趣图:这是招聘超神级别的程序员?
- O、Θ、Ω
1.这些是时间复杂度的.(e.g. O(n).Θ(n).Ω(n)) 主要为主定理(坏东西) 2.本质 O <= Θ = Ω >=
- Linux服务器内存监控—每小时检查&超出发送邮件&重启占用最高的Java程式
简介与优点 使用该脚本能自行判断系统内存使用情况是否超出设定百分比 能在超出预警值时执行重启程式的操作 能记录重启过程,并将具体LOG邮件发送给指定收信人 可以设定Crontab排程,达成每隔一段时间 ...
- Python-统计序列中元素
问题1: 随机数列[12,5,8,7,8,9,4,8,5,...] 中出现次数最高的3个元素,他们出现的次数 问题2: 对某英文文章的单词,进行词频统计,找出出现次数最搞得10个单词,他们出现的次数是 ...
- Book of Shaders 03 - 学习随机与噪声生成算法
0x00 随机 我们不能预测天空中乌云的样子,因为它的纹理总是具有不可预测性.这种不可预测性叫做随机 (random). 在计算机图形学中,我们通常使用随机来模拟自然界中的噪声.如何获得一个随机值呢, ...