亚马逊DRKG使用体验
基于文章:探索「老药新用」最短路径:亚马逊AI Lab开源大规模药物重定位知识图谱DRKG,记录了该项目的实际部署与探索过程,供参考。
1. DRKG介绍
大规模药物重定位知识图谱 Drug Repurposing Knowledge Graph (DRKG) 是一种涉及基因、化合物、疾病、生物学过程、副作用和症状的综合性生物知识图。DRKG包括来自六个现有数据库的信息,包括DrugBank、Hetionet、GNBR、String、IntAct 、DGIdb,以及从最近的出版物收集的数据,特别是与Covid19相关的数据。它包括属于13种实体类型的97238个实体,以及分属于107种关系类型的5874261 个三元组数据。还包括一堆关于如何使用DRKG完成探索和分析统计,基于机器学习方法完成知识图嵌入等任务。
2. 开发环境
- python==3.6.1
- torch==1.2.0+cpu
- dgl==0.4.3
- dglke==0.1.1
3. 数据源
DRKG包括Hetionet等 6个生物数据库信息以及最近出版的论文数据集,然而,具体数据获取方式并未公开,以下是部分生物数据库介绍。
3.1 Hetionet

3.2 DrugBank
3.3 String

4. 知识图谱信息
DRKG.tsv:包含了知识图谱的所有三元组,包含13类实体,如下:

17类实体关系

5. 预备知识
基于TransE算法完成实体、关系、边嵌入向量构造。
关于知识图谱嵌入模型可点击以下链接了解:知识图谱嵌入的Translate模型汇总(TransE,TransH,TransR,TransD)
6. DRKG使用
6.1 知识图谱嵌入向量预训练
在亚马逊DRKG中,提供了封装好的脚本实现知识图谱嵌入向量的训练模型:
在原始代码中,执行脚本为:
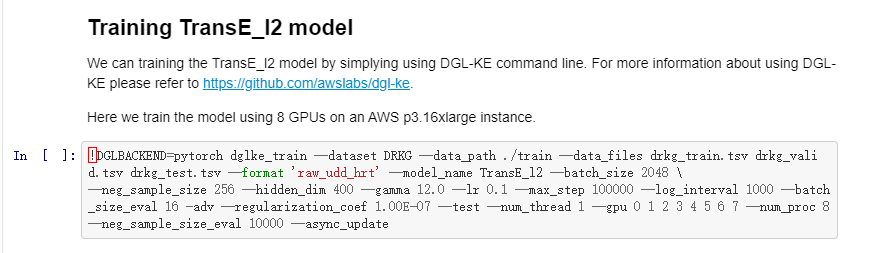
由于我们采用windows环境 ,且没有配置GPU集群,需要修改执行脚本为:
!dglke_train --dataset DRKG --data_files DRKG_train.tsv DRKG_valid.tsv DRKG_test.tsv --format raw_udd_hrt --model_name TransE_l2 --batch_size 2048 \
--neg_sample_size 256 --hidden_dim 400 --gamma 12.0 --lr 0.1 --max_step 100000 --log_interval 1000 --batch_size_eval 16 -adv --regularization_coef 1.00E-07 --test --num_thread 1 --neg_sample_size_eval 10000 --async_update
其中dglke_train 的可选参数有以下:
- --model_name {TransE,TransE_l1,TransE_l2,TransR,RESCAL,DistMult,ComplEx,RotatE}. The models provided by DGL-KE.
- --data_path DATA_PATH. The path of the directory where DGL-KE loads knowledge graph data.
- --dataset DATASET The name of the builtin knowledge graph. Currently,the builtin knowledge graphs include FB15k, FB15k-237,wn18, wn18rr and Freebase. DGL-KE automatically downloads the knowledge graph and keep it under data_path.
- --format FORMAT The format of the dataset. For builtin knowledge graphs,the foramt should be built_in. For users own knowledge graphs,it needs to be raw_udd_{htr} or udd_{htr}.
- --data_files DATA_FILES [DATA_FILES ...]. A list of data file names. This is used if users want to train KGEon their own datasets. If the format is raw_udd_{htr},users need to provide train_file [valid_file] [test_file].If the format is udd_{htr}, users need to provideentity_file relation_file train_file [valid_file] [test_file].In both cases, valid_file and test_file are optional.
- --delimiter DELIMITER. Delimiter used in data files. Note all files should use the same delimiter.
- --save_path SAVE_PATH the path of the directory where models and logs are saved.
- --no_save_emb Disable saving the embeddings under save_path.
- --max_step MAX_STEP The maximal number of steps to train the model.A step trains the model with a batch of data.
- --batch_size BATCH_SIZE. The batch size for training.
- --batch_size_eval BATCH_SIZE_EVAL.The batch size used for validation and test.
- --neg_sample_size NEG_SAMPLE_SIZE. The number of negative samples we use for each positive sample in the training.
- --neg_deg_sample Construct negative samples proportional to vertex degree in the training.When this option is turned on, the number of negative samples per positive edgewill be doubled. Half of the negative samples are generated uniformly whilethe other half are generated proportional to vertex degree.
- --neg_deg_sample_eval. Construct negative samples proportional to vertex degree in the evaluation.
- --neg_sample_size_eval NEG_SAMPLE_SIZE_EVAL. The number of negative samples we use to evaluate a positive sample.
- --eval_percent EVAL_PERCENT. Randomly sample some percentage of edges for evaluation.
- --no_eval_filter Disable filter positive edges from randomly constructed negative edges for evaluation
- --log LOG_INTERVAL, --log_interval LOG_INTERVAL. Print runtime of different components every x steps.
- --eval_interval EVAL_INTERVAL. Print evaluation results on the validation dataset every x stepsif validation is turned on
- --test Evaluate the model on the test set after the model is trained.
- --num_proc NUM_PROC The number of processes to train the model in parallel.In multi-GPU training, the number of processes by default is set to match the number of GPUs.If set explicitly, the number of processes needs to be divisible by the number of GPUs.
- --num_thread NUM_THREAD The number of CPU threads to train the model in each process.This argument is used for multiprocessing training.
- --force_sync_interval FORCE_SYNC_INTERVAL. We force a synchronization between processes every x steps formultiprocessing training. This potentially stablizes the training processto get a better performance. For multiprocessing training, it is set to 1000 by default.
- --hidden_dim HIDDEN_DIM.The embedding size of relation and entity
- --lr LR The learning rate. DGL-KE uses Adagrad to optimize the model parameters.
- -g GAMMA, --gamma GAMMA. The margin value in the score function. It is used by TransX and RotatE.
- -de, --double_ent Double entitiy dim for complex number It is used by RotatE.
- -dr, --double_rel Double relation dim for complex number.
- -adv, --neg_adversarial_sampling Indicate whether to use negative adversarial sampling.It will weight negative samples with higher scores more.
- -a ADVERSARIAL_TEMPERATURE, --adversarial_temperature ADVERSARIAL_TEMPERATURE
- The temperature used for negative adversarial sampling.
- -rc REGULARIZATION_COEF, --regularization_coef REGULARIZATION_COEF
- The coefficient for regularization.
- -rn REGULARIZATION_NORM, --regularization_norm REGULARIZATION_NORM norm used in regularization.
- --gpu GPU [GPU ...] A list of gpu ids, e.g. 0 1 2 4
- --mix_cpu_gpu Training a knowledge graph embedding model with both CPUs and GPUs.The embeddings are stored in CPU memory and the training is performed in GPUs.This is usually used for training a large knowledge graph embeddings.
- --valid Evaluate the model on the validation set in the training.
- --rel_part Enable relation partitioning for multi-GPU training.
- --async_update Allow asynchronous update on node embedding for multi-GPU training.This overlaps CPU and GPU computation to speed up.
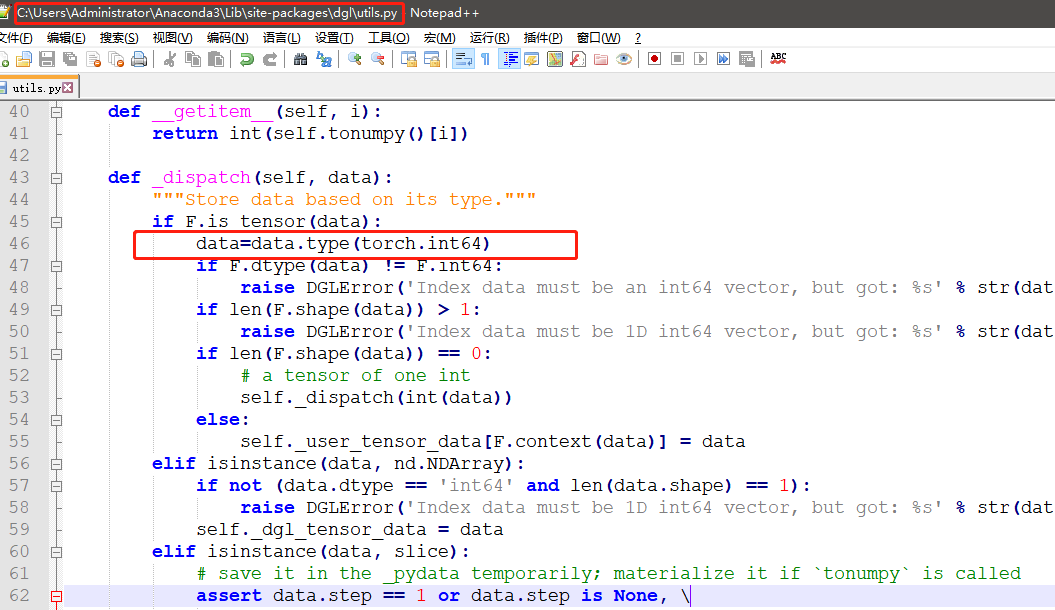
此外,还需要修改以下路径代码,具体需要修改数据类型从int32为int64。
6.2 知识图谱嵌入向量的应用
- 实体相似性分析
- 关系相似性分析
- 实体-关系得分评估
其中实体-关系得分评估可用于链接预测。链接预测是指包括社交网站的好友推荐,预测蛋白质间的相互影响,预测犯罪嫌疑人的关系,商品推荐在内的一系列问题总称。
6.3 链接预测问题
DRKG提供了一个链接预测demo,但需对代码进行小幅修改。
在执行以下代码会报错:IndexError: tensors used as indices must be long, byte or bool tensors

需要转化张量格式,增加:

6.4 老药新用、药物重定向
DRKG提供了covid-19新冠药物筛查demo,主要包括基于两个方向的药物筛选:
1、基于“疾病-化合物”关系的药物筛查
2、基“基因-化合物”关系的药物筛查
6.4.1 基于“疾病-化合物”关系的药物筛查
首先,收集DRKG中所有冠状病毒(COV)疾病,映射到对应的图谱实体(疾病)嵌入向量;
其次,在Drugbank中使用FDA批准的药物作为候选药物,约有8104个,同样映射到对应的图谱实体(药物)嵌入向量;
最后,定义关系为['Hetionet::CtD::Compound:Disease','GNBR::T::Compound:Disease'] 这两类关系,同样映射到对应的图谱关系嵌入向量;
借助于训练图谱嵌入向量的TransE算法,定义以下得分函数,作为衡量所有候选药物在上述两类关系上与所有冠状病毒(COV)疾病的匹配程度,得分越大越好。

统计得分TOP100的药物,并与以开展的32个covid-19临床试验药物比较,观察有多少在TOP100中存在。
6.4.2 基于”基因-化合物“的药物筛查
首先,收集DRKG中所有冠状病毒(COV)相关基因,映射到对应的图谱实体(基因)嵌入向量;
其次,在Drugbank中使用FDA批准的药物作为候选药物,约有8104个,同样映射到对应的图谱实体(药物)嵌入向量;
最后,定义关系为['GNBR::N::Compound:Gene'] 抑制关系,同样映射到对应的图谱关系嵌入向量;
借助于训练图谱嵌入向量的TransE算法,定义以下得分函数,作为e衡量所有候选药物在上述抑制关系上与所有冠状病毒(COV)基因的匹配程度,得分越大越好。
6.4.3 总结
纵观本项目的药物筛查实现方式,采用的方法其实并不复杂,核心还是对预训练知识图谱嵌入模型的使用。至于看到过的基于GNN进行药物分子设计的应用,在本项目所提供的代码中并未体现,因此相关工作仍然需要继续研究。
亚马逊DRKG使用体验的更多相关文章
- (转)来自互联网巨头的46个用户体验面试问题(谷歌,亚马逊,facebook及微软)
原文出处: uxdesign - Eleonora Zucconi 译文出处:UXRen - 邓俊杰 如果你是个正在找工作的用户体验研究员,或是一个招聘经理正急需一些启发性问题来测试你的候选人,这 ...
- 批量删除亚马逊kindle云端文档
首先鄙视亚马逊的不负责任,kindle的云端管理系统犹如一坨狗屎,根本没有考虑的任何用户体验,只能一个一个删除不说,删除后又回到第一页...翻页也没有输入页码的地方,如果在第100页删除文档后,又回到 ...
- 亚马逊副总裁谈Marketplace平台的个性化服务
说到个性化,亚马逊无疑是挖掘与利用数据为消费者打造个性化网购体验的先驱之一.而现在,几乎所有的公司和网站都在利用更加个性化的推荐算法为用户提供更好的购物和浏览体验. 亚马逊近年来尤其重视将其个性化特性 ...
- A亚马逊WS网上系列讲座——怎么样AWS云平台上千万用户的应用建设
用户选择云计算平台构建应用程序的一个重要原因是高弹性的云平台和可扩展性. 面向Internet应用程序通常需要支持用户使用大量,但要建立一个高度可扩展.具有一定的挑战,高度可用的应用程序,只有立足AW ...
- Google、微软、Linkedln、Uber、亚马逊等15+海外技术专家聚首2018TOP100Summit
11月30日-12月3日,由msup主办的第七届全球软件案例研究峰会(以下简称为TOP100Summit)将在北京国家会议中心举办.本届峰会以“释放AI生产力,让组织向智能化演进”作为开幕式主题, 4 ...
- TOP100summit 2017:亚马逊Echo音箱能够语音识人,华人工程师揭秘设计原理
本文编辑:Cynthia 2017年,人工智能的消费产品落地聚焦在了智能音箱上,谷歌.亚马逊纷纷推出智能音箱产品,国内的阿里巴巴推出天猫精灵,小米推出小米AI音箱.智能音箱通过语音可以发出指令,未 ...
- 微软、谷歌、亚马逊、Facebook等硅谷大厂91个开源软件盘点(附下载地址)
开源软件中有大量专家构建的代码,大大节省了开发人员的时间和成本,热衷于开源的大厂们总是能够带给我们新的惊喜.2016年9月GitHub报告显示,GitHub已经有超过 520 万的用户和超 30 万的 ...
- 亚马逊Kindle正式进入中国
6月7日下午消息,亚马逊Kindle今天下午4点正式发售.其中,Kindle电子阅读器和Kindle Fire平板电脑同步销售.Paperwhite售价最低849元,Kindle Fire HD售价最 ...
- 亚马逊CEO贝索斯致股东信:阐述公司未来计划
亚马逊CEO 杰夫·贝索斯(Jeff Bezos)今天发布年度股东信, 详细描述了亚马逊的产品.服务和未来计划,当然,信中并没有任何的硬数据,比如说亚马逊Kindle的销量等等.但这封信也包括一些颇令 ...
随机推荐
- Dubbo系列之 (二)Registry注册中心-注册(1)
引导 dubbo的服务的注册与发现,需要通过第三方注册中心来协助完成,目前dubbo支持的注册中心包括 zookeeper,consul,etcd3,eureka,nacas,redis,sofa.这 ...
- C#LeetCode刷题之#680-验证回文字符串 Ⅱ(Valid Palindrome II)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3961 访问. 给定一个非空字符串 s,最多删除一个字符.判断是否 ...
- ARM 精简指令集与复杂指令集
什么是ARM,CISC RISC 又是什么 最近苹果公司召开了最新发布会,苹果PC将采用自研的ARM芯片,这将使苹果PC.移动端.平板成为同一个硬件下的系统.而ARM使用的就是CISC精简指令集, ...
- 复习 Array,重学 JavaScript
1 数组与对象 在 JavaScript 中,一个对象的键只能有两种类型:string 和 symbol.下文只考虑键为字符串的情况. 1.1 创建对象 在创建对象时,若对象的键为数字,或者由 字母+ ...
- 记录使用Python登录浙江大学统一身份认证
背景 现在每天要进行健康情况上报,但是因为经常睡过头忘记打卡,于是想着写一个程序来自动打卡. 统一身份认证 访问健康情况上报页面(https://healthreport.zju.edu.cn/nco ...
- Jmeter 常用函数(22)- 详解 __intSum
如果你想查看更多 Jmeter 常用函数可以在这篇文章找找哦 https://www.cnblogs.com/poloyy/p/13291704.htm 作用 计算两个或多个整数值的和 语法格式 ${ ...
- MySQL最全存储引擎、索引使用及SQL优化的实践
1 MySQL的体系结构概述 整个MySQL Server由以下组成 :Connection Pool :连接池组件Management Services & Utilities :管理服务和 ...
- golang并发
1.goroutine goroutine是Go并行设计的核心.goroutine说到底其实就是线程,但是它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些 ...
- C++ IO的一些注意点
读入这个坑一直以来都深受其麻烦,把遇到一些注意点记一下吧. 1.getchar读入 以前练线段树的时候做到Acwing#246 Interval GCD(原题在CodeHunter上,人懒就在Acwi ...
- 记一次 gltf 模型的绘制性能提升:从ppt到dove,丝滑感受
转换思路 同样一个模型,分别取如下转换思路: 原始模型fbxgltf 原始模型objgltf 但是我在打开中间格式fbx和obj时,发现这两者虽然顶点数量一致,三角形数量一致,但是使用 Windows ...