Explain Plan试分析
注:以下是本人对Explain Plan的试分析,有不对的地方希望大家指出。关于如何查看Oracle的解释计划请参考:https://www.cnblogs.com/xiandedanteng/p/12123819.html
例一:
执行的SQL语句:
EXPLAIN plan for
select * from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.empno=1 select * from table(dbms_xplan.display)
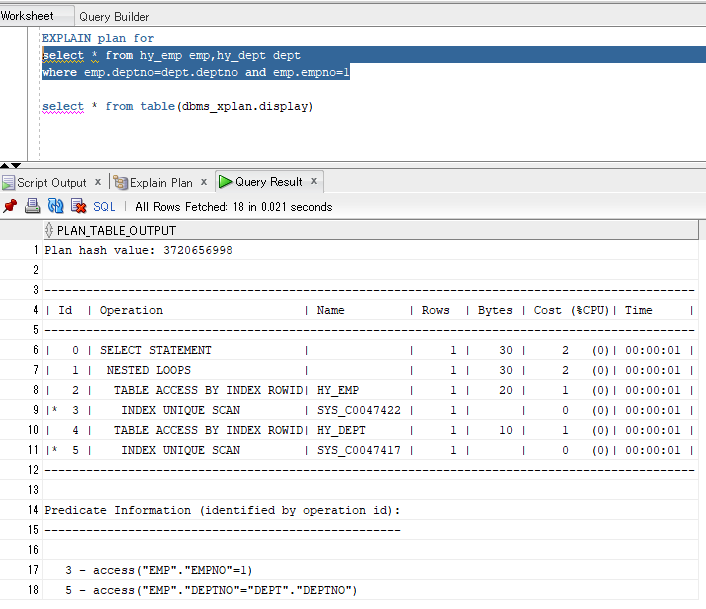
首先执行#3,在HY_EMP表进行empno=1的查找(索引唯一扫描方式);
再执行#5,在HY_DEPT表进行emp.deptno=dept.deptno的连接(索引唯一扫描方式);
然后,把两个结果集进行嵌套循环连接;
最后,把select子句里的字段带上。
例二:
执行的SQL语句:
EXPLAIN plan for select * from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
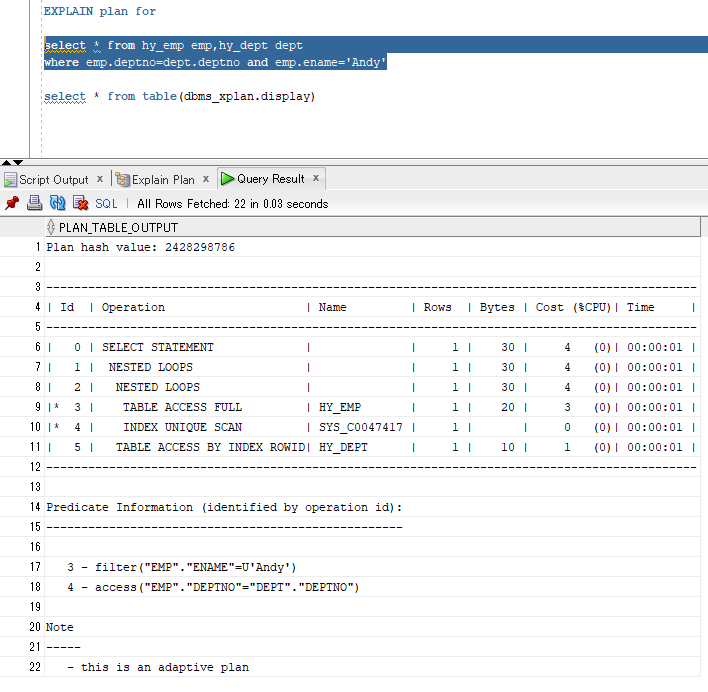
分析:
#9先执行,在emp表进行NAME=Andy的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#10第二执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键);
#8第三执行,将#9,#10两步得到的结果集(两者都是EMP表的子集)进行嵌套循环连接;
接下来,将#8得到的结果集与#11进行嵌套循环连接(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键)
最后执行#6,把select子句都带出来。
例三:
SQL:
EXPLAIN plan for select emp.* from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
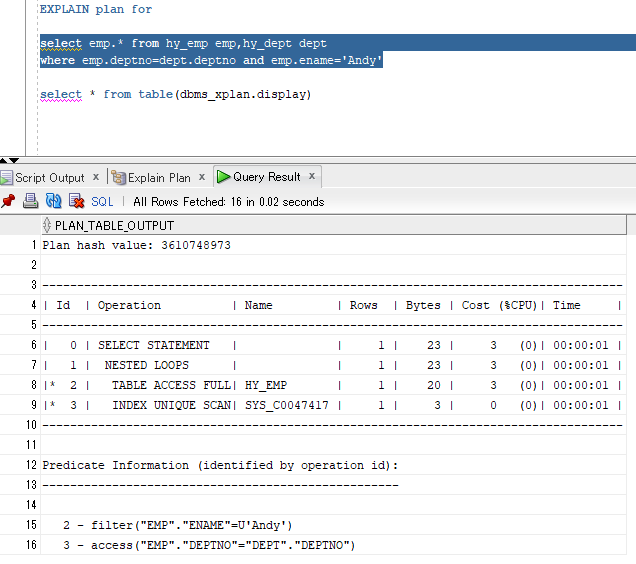
解读:
#8先执行,在emp表进行NAME=Andy的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#9第二执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键)
#7再执行,将#8,#9两步得到的结果集(均为emp的子集)进行嵌套循环连接;
由于select子句中只要emp表的字段,因此#7得到的结果集就是最终结果集;
最后把select子句中字段都带出来。
这一段也印证了前面关于 “#8,#9两步得到的结果集均为emp的子集” 的论断。
例四:
SQL:
EXPLAIN plan for select dept.* from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
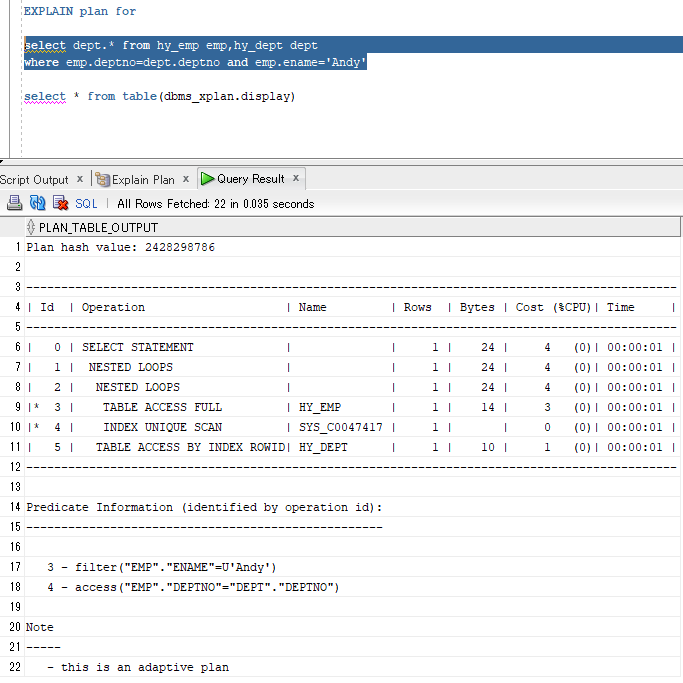
解读:
#9先执行,在emp表进行NAME=Andy的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#10第二执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键)
#8再执行,将#9,#10两步得到的结果集(均为emp的子集)进行嵌套循环连接;
由于select子句中需要dept表的字段,因此#8得到的结果集因为只是emp的子集不足以提供dept表的字段,还需要与dept表做一次连接;
#7执行,将#11得到的结果集(dept表的子集)与#8结果集进行嵌套循环连接;
最后带上select子句的字段。
例五:
SQL:
EXPLAIN plan for select count(*) from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
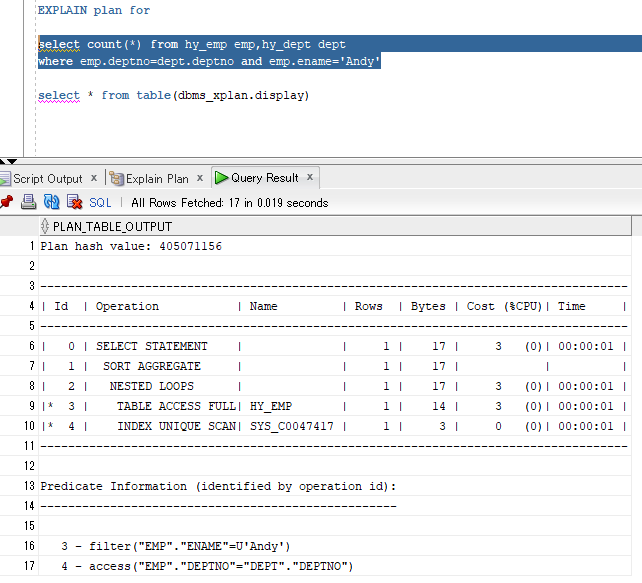
解读:
#9,#10,#8的分析和前面的同类语句类似;
因最终不需要dept表的数据,因此得到#8的结果集就够count(×)的统计了;
#7 的sort aggregate是排序聚合的意思,但这并非动作,而是代表语句类型,从cost看它也未产生消耗;
最后把select子句带出来就够了。
例六:
SQL:
EXPLAIN plan for select * from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename like '%in%'
order by emp.empno select * from table(dbms_xplan.display)
截图:
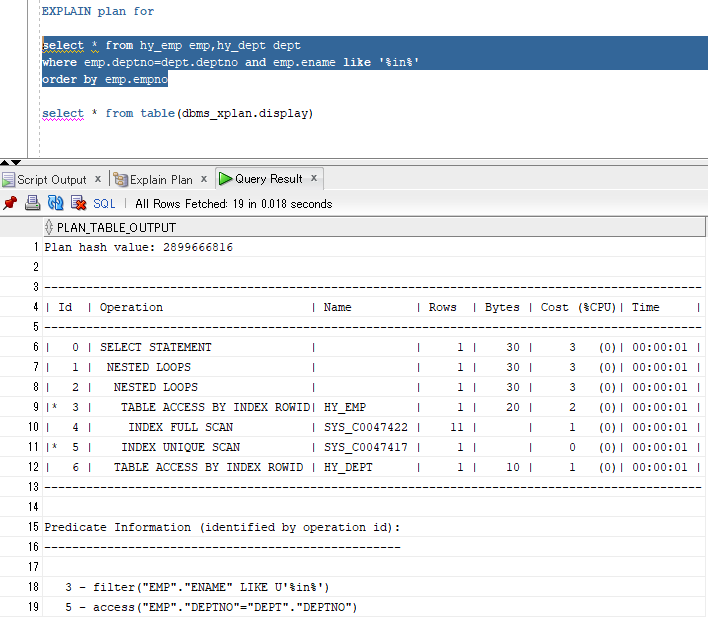
解读:
从缩进层次里来看,#10先执行,这一步走的是emp表的按empno排序(索引全扫描方式) ;
#9之后执行,在emp表进行NAME like ‘%in%’的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#11再执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取数据(ACCESS方式),因为DEPTNO是DEPT表的主键)
#8再执行,将#9,#10两步得到的结果集(均为emp的子集)进行嵌套循环连接;
因为是select *,#8得到的结果集不足以成为最终结果集,它还要与dept表进行连接(从#8结果集找出deptno直接到dept中去找)
最后把select子句带出来。
附:以上SQL涉及到的表及其数据:
CREATE TABLE hy_emp
(
empno NUMBER(8,0) not null primary key,
ename NVARCHAR2(60) not null,
deptno NUMBER(8,0) not null,
sal NUMBER(10,0) DEFAULT 0 not null
) CREATE TABLE hy_dept
(
deptno NUMBER(8,0) not null primary key,
dname NVARCHAR2(60) not null
)
数据:
insert into hy_dept(deptno,dname) values('','Hr');
insert into hy_dept(deptno,dname) values('','Dev');
insert into hy_dept(deptno,dname) values('','Qa');
insert into hy_dept(deptno,dname) values('','Sales');
insert into hy_dept(deptno,dname) values('','Mng');
insert into hy_emp(empno,ename,deptno,sal) values('','Andy','',1000);
insert into hy_emp(empno,ename,deptno,sal) values('','Bill','',2000);
insert into hy_emp(empno,ename,deptno,sal) values('','Cindy','',3000);
insert into hy_emp(empno,ename,deptno,sal) values('','Douglas','',4000);
insert into hy_emp(empno,ename,deptno,sal) values('','Edinburg','',5000);
insert into hy_emp(empno,ename,deptno,sal) values('','Felix','',6000);
insert into hy_emp(empno,ename,deptno,sal) values('','Hellen','',7000);
insert into hy_emp(empno,ename,deptno,sal) values('','Isis','',8000);
insert into hy_emp(empno,ename,deptno,sal) values('','Jean','',9000);
insert into hy_emp(empno,ename,deptno,sal) values('','King','',10000);
insert into hy_emp(empno,ename,deptno,sal) values('','Mac','',11000);
--END-- 2019-12-31 13:47
Explain Plan试分析的更多相关文章
- 分析oracle的执行计划(explain plan)并对对sql进行优化实践
基于oracle的应用系统很多性能问题,是由应用系统sql性能低劣引起的,所以,sql的性能优化很重要,分析与优化sql的性能我们一般通过查看该sql的执行计划,本文就如何看懂执行计划,以及如何通过分 ...
- oracle用EXPLAIN PLAN 分析SQL语句
EXPLAIN PLAN 是一个很好的分析SQL语句的工具,它甚至可以在不执行SQL的情况下分析语句. 通过分析,我们就可以知道ORACLE是怎么样连接表,使用什么方式扫描表(索引扫描或全表扫描)以及 ...
- MySQL慢查询Explain Plan分析
Explain Plan 执行计划,包含了一个SELECT(后续版本支持UPDATE等语句)的执行 主要字段 id 编号,从1开始,执行的时候从大到小,相同编号从上到下依次执行. Select_typ ...
- 【转】Oracle 执行计划(Explain Plan) 说明
转自:http://blog.chinaunix.net/uid-21187846-id-3022916.html 如果要分析某条SQL的性能问题,通常我们要先看SQL的执行计划,看看SQ ...
- PLSQL_性能优化系列15_Oracle Explain Plan解析计划解读
2014-12-19 Created By BaoXinjian
- EXPLAIN PLAN获取SQL语句执行计划
一.获取SQL语句执行计划的方式 1. 使用explain plan 将执行计划加载到表plan_table,然后查询该表来获取预估的执行计划 2. 启用执行计划跟踪功能,即autotrace功能 3 ...
- Oracle 执行计划(Explain Plan)
如果要分析某条SQL的性能问题,通常我们要先看SQL的执行计划,看看SQL的每一步执行是否存在问题. 如果一条SQL平时执行的好好的,却有一天突然性能很差,如果排除了系统资源和阻塞的原因,那么基本可以 ...
- 优化器的使用oracle ---explain plan
如果要分析某条SQL的性能问题,通常我们要先看SQL的执行计划,看看SQL的每一步执行是否存在问题. 如果一条SQL平时执行的好好的,却有一天突然性能很差,如果排除了系统资源和阻塞的原因,那么基本可以 ...
- Oracle执行计划 explain plan
Rowid的概念:rowid是一个伪列,既然是伪列,那么这个列就不是用户定义,而是系统自己给加上的. 对每个表都有一个rowid的伪列,但是表中并不物理存储ROWID列的值.不过你可以像使用其它列那样 ...
随机推荐
- Django 1.8.11 查询数据库返回JSON格式数据
Django 1.8.11 查询数据库返回JSON格式数据 和前端交互全部使用JSON,如何将数据库查询结果转换成JSON格式 环境 Win10 Python2.7 Django 1.8.11 返回多 ...
- Libsvm java工程实践
在上篇文章中对libsvm的流程和简单的java代码测试做了说明,本篇简单对libsvm如何在工程中实践进行简短说明,不当的地方欢迎大家指正. 第一步是对libsvm的预测函数进行调整,我是从svm_ ...
- 我搭的神经网络不work该怎么办!看看这11条新手最容易犯的错误
1. 忘了数据规范化 2. 没有检查结果 3. 忘了数据预处理 4. 忘了正则化 5. 设置了过大的批次大小 6. 使用了不适当的学习率 7. 在最后一层使用了错误的激活函数 8. 网络含有不良梯度 ...
- vue项目发布后带路径打开页面报404问题
环境: 后端,python+uwsgi启动 前端:vue 用nginx运行,指定静态目录 问题 :发布后带路径打开页面报404问题,带路径打开即不是打开的主页 解决方案: https://route ...
- Java并发---并发理论
一.如何理解线程安全 在多线程中稍微不注意就会出现线程安全问题,那么什么是线程安全问题? 我的认识是.在多线程下代码执行的结果和预期的正确的结果不一致,该代码就是线程不安全的,否则就是线程安全的 在深 ...
- ElasticSearch实战系列七: Logstash实战使用-图文讲解
前言 在上一篇中我们介绍了Logstash快速入门,本文主要介绍的是ELK日志系统中的Logstash的实战使用.实战使用我打算从以下的几个场景来进行讲解. 时区问题解决方案 在我们使用logstas ...
- SpringMVC接受表单数据
@ 目录 pojo addProduct.jsp ProductController showProduct.jsp 测试结果 pojo 新建实体类Product package pojo; publ ...
- linux驱动之模块化编程
今天刚开始学习linux驱动的编写.在网上开了许多网友的博客,感觉比较好的摘抄下来,以便以后忘记可以随时查看.下面是摘抄文章的地址,非常感谢他们. http://blog.chinaunix.net/ ...
- 安全可靠国产系统背景下的应用开发应有.NET Core的一席之地
在中美当前背景下的安全可靠国产系统(简称安可),安可产业要实现技术自主可控,需要在四个层面逐步实现:基础硬件设施,如芯片.服务器.存储.交换机.路由器:底层软件,包括操作系统.数据库.中间件等:应用软 ...
- python数据处理工具 -- pandas(序列与数据框的构造)
Pandas模块的核心操作对象就是对序列(Series)和数据框(Dataframe).序列可以理解为数据集中的一个字段,数据框是值包含至少两个字段(或序列) 的数据集. 构造序列 1.通过同质的列表 ...