RandomForest 随机森林算法与模型参数的调优
公号:码农充电站pro
主页:https://codeshellme.github.io
本篇文章来介绍随机森林(RandomForest)算法。
1,集成算法之 bagging 算法
在前边的文章《AdaBoost 算法-分析波士顿房价数据集》中,我们介绍过集成算法。集成算法中有一类算法叫做 bagging 算法。
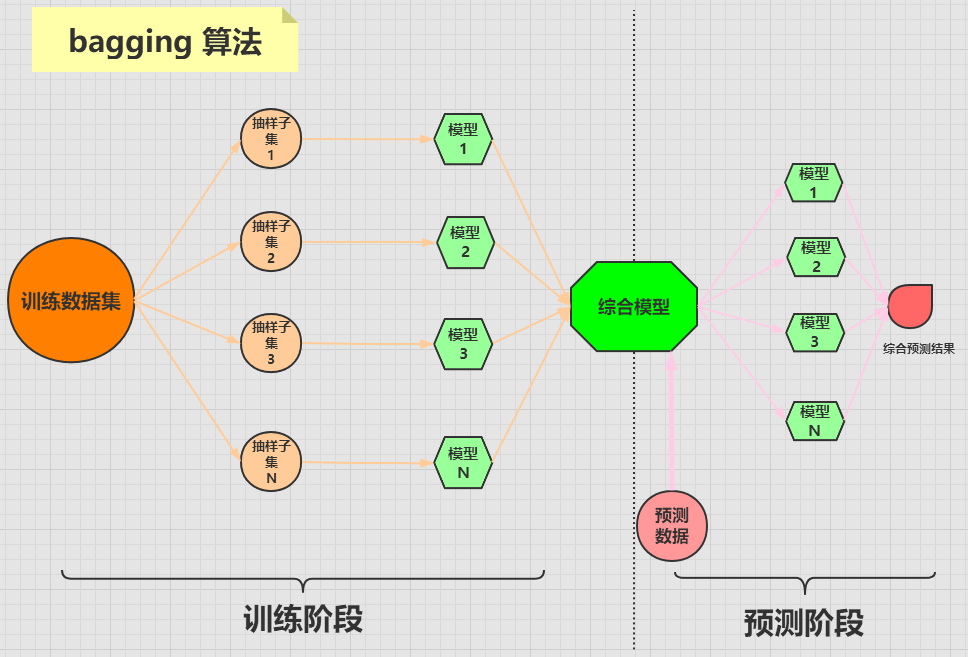
bagging 算法是将一个原始数据集随机抽样成 N 个新的数据集。然后将这 N 个新的数据集作用于同一个机器学习算法,从而得到 N 个模型,最终集成一个综合模型。
在对新的数据进行预测时,需要经过这 N 个模型(每个模型互不依赖干扰)的预测(投票),最终综合 N 个投票结果,来形成最后的预测结果。
bagging 算法的流程可用下图来表示:
2,随机森林算法
随机森林算法是 bagging 算法中比较出名的一种。
随机森林算法由多个决策树分类器组成,每一个子分类器都是一棵 CART 分类回归树,所以随机森林既可以做分类,又可以做回归。
当随机森林算法处理分类问题的时候,分类的最终结果是由所有的子分类器投票而成,投票最多的那个结果就是最终的分类结果。
当随机森林算法处理回归问题的时候,最终的结果是每棵 CART 树的回归结果的平均值。
3,随机森林算法的实现
sklearn 库即实现了随机森林分类树,又实现了随机森林回归树:
RandomForestClassifier 类的原型如下:
RandomForestClassifier(n_estimators=100,
criterion='gini', max_depth=None,
min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True, oob_score=False,
n_jobs=None, random_state=None,
verbose=0, warm_start=False,
class_weight=None, ccp_alpha=0.0,
max_samples=None)
可以看到分类树的参数特别多,我们来介绍几个重要的参数:
- n_estimators:随机森林中决策树的个数,默认为 100。
- criterion:随机森林中决策树的算法,可选的有两种:
- gini:基尼系数,也就是 CART 算法,为默认值。
- entropy:信息熵,也就是 ID3 算法。
- max_depth:决策树的最大深度。
RandomForestRegressor 类的原型如下:
RandomForestRegressor(n_estimators=100,
criterion='mse', max_depth=None,
min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True, oob_score=False,
n_jobs=None, random_state=None,
verbose=0, warm_start=False,
ccp_alpha=0.0, max_samples=None)
回归树中的参数与分类树中的参数基本相同,但 criterion 参数的取值不同。
在回归树中,criterion 参数有下面两种取值:
- mse:表示均方误差算法,为默认值。
- mae:表示平均误差算法。
4,随机森林算法的使用
下面使用随机森林分类树来处理鸢尾花数据集,该数据集在《决策树算法-实战篇》中介绍过,这里不再介绍,我们直接使用它。
首先加载数据集:
from sklearn.datasets import load_iris
iris = load_iris() # 准备数据集
features = iris.data # 获取特征集
labels = iris.target # 获取目标集
将数据分成训练集和测试集:
from sklearn.model_selection import train_test_split
train_features, test_features, train_labels, test_labels =
train_test_split(features, labels, test_size=0.33, random_state=0)
接下来构造随机森林分类树:
from sklearn.ensemble import RandomForestClassifier
# 这里均使用默认参数
rfc = RandomForestClassifier()
# 训练模型
rfc.fit(train_features, train_labels)
estimators_ 属性中存储了训练出来的所有的子分类器,来看下子分类器的个数:
>>> len(rfc.estimators_)
100
预测数据:
test_predict = rfc.predict(test_features)
测试准确率:
>>> from sklearn.metrics import accuracy_score
>>> accuracy_score(test_labels, test_predict)
0.96
5,模型参数调优
在机器学习算法模型中,一般都有很多参数,每个参数都有不同的取值。如何才能让模型达到最好的效果呢?这就需要参数调优。
sklearn 库中有一个 GridSearchCV 类,可以帮助我们进行参数调优。
我们只要告诉它想要调优的参数有哪些,以及参数的取值范围,它就会把所有的情况都跑一遍,然后告诉我们参数的最优取值。
先来看下 GridSearchCV 类的原型:
GridSearchCV(estimator,
param_grid, scoring=None,
n_jobs=None, refit=True,
cv=None, verbose=0,
pre_dispatch='2*n_jobs',
error_score=nan,
return_train_score=False)
其中有几个重要的参数:
- estimator:表示为哪种机器学习算法进行调优,比如随机森林,决策树,SVM 等。
- param_grid:要优化的参数及取值,输入的形式是字典或列表。
- scoring:准确度的评价标准。
- cv:交叉验证的折数,默认是三折交叉验证。
下面我们对随机森林分类树进行参数调优,还是使用鸢尾花数据集。
首先载入数据:
from sklearn.datasets import load_iris
iris = load_iris()
构造分类树:
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
如果我们要对分类树的 n_estimators 参数进行调优,调优的范围是 [1, 10],则准备变量:
param = {"n_estimators": range(1,11)}
创建 GridSearchCV 对象,并调优:
from sklearn.model_selection import GridSearchCV
gs = GridSearchCV(estimator=rfc, param_grid=param)
# 对iris数据集进行分类
gs.fit(iris.data, iris.target)
输出最优准确率和最优参数:
>>> gs.best_score_
0.9666666666666668
>>> gs.best_params_
{'n_estimators': 7}
可以看到,最优的结果是 n_estimators 取 7,也就是随机森林的子决策树的个数是 7 时,随机森林的准确度最高,为 0.9667。
6,总结
本篇文章主要介绍了随机森林算法的原理及应用,并展示了如何使用 GridSearchCV 进行参数调优。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。

RandomForest 随机森林算法与模型参数的调优的更多相关文章
- R语言︱机器学习模型评估方案(以随机森林算法为例)
笔者寄语:本文中大多内容来自<数据挖掘之道>,本文为读书笔记.在刚刚接触机器学习的时候,觉得在监督学习之后,做一个混淆矩阵就已经足够,但是完整的机器学习解决方案并不会如此草率.需要完整的评 ...
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- Python机器学习笔记——随机森林算法
随机森林算法的理论知识 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代 ...
- 用Python实现随机森林算法,深度学习
用Python实现随机森林算法,深度学习 拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩 ...
- 随机森林算法demo python spark
关键参数 最重要的,常常需要调试以提高算法效果的有两个参数:numTrees,maxDepth. numTrees(决策树的个数):增加决策树的个数会降低预测结果的方差,这样在测试时会有更高的accu ...
- H2O中的随机森林算法介绍及其项目实战(python实现)
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator ...
- 随机森林算法-Deep Dive
0-写在前面 随机森林,指的是利用多棵树对样本进行训练并预测的一种分类器.该分类器最早由Leo Breiman和Adele Cutler提出.简单来说,是一种bagging的思想,采用bootstra ...
- spark 随机森林算法案例实战
随机森林算法 由多个决策树构成的森林,算法分类结果由这些决策树投票得到,决策树在生成的过程当中分别在行方向和列方向上添加随机过程,行方向上构建决策树时采用放回抽样(bootstraping)得到训练数 ...
- 随机森林算法OOB_SCORE最佳特征选择
RandomForest算法(有监督学习),可以根据输入数据,选择最佳特征组合,减少特征冗余:原理:由于随机决策树生成过程采用的Boostrap,所以在一棵树的生成过程并不会使用所有的样本,未使用的样 ...
随机推荐
- CIBN手机电视8.3.2永久VIP
一款互联网电视的手机客户端.可以观看最新的电影和电视剧,还会为你推荐人气热门电影,让你不会错过每一部精彩的大片,以去除app内的所有可见广告,解锁VIP特权,无需登录直接使用! 下载地址:https: ...
- 一文入门Redis
一文入门Redis 目录 一文入门Redis 一.Redis简介 二.常用数据类型 1.String(字符串) 2.Hash(哈希) 3.List(列表) 4.Set(集合) 5.Zset(有序集合) ...
- Docker部署Portainer搭建轻量级可视化管理UI
1. 简介 Portainer是一个轻量级的可视化的管理UI,其本身也是运行在Docker上的单个容器,提供用户更加简单的管理和监控宿主机上的Docker资源. 2. 安装Docker Doc ...
- SpringBoot瘦身部署(15.9 MB - 92.3 KB)
1. 简介 SpringBoot项目部署虽然简单,但是经常因为修改了少量代码而需要重新打包上传服务器重新部署,而公网服务器的网速受限,可能整个项目的代码文件仅仅只有1-2MB甚至更少,但是需要上传 ...
- 自顶向下redis4.0(2)文件事件与客户端
redis4.0的文件事件与客户端 目录 redis4.0的文件事件与客户端 简介 正文 准备阶段 接受客户端连接 处理数据 返回数据结果 参考文献 简介 文件事件的流程大概如下: 在服务器初始化时生 ...
- Spring MVC或Spring Boot配置默认访问页面不生效?
相信在开发项目过程中,设置默认访问页面应该都用过.但是有时候设置了却不起作用.你知道是什么原因吗?今天就来说说我遇到的问题. 首先说说配置默认访问页面有哪几种方式. 1.tomcat配置默认访问页面 ...
- js上 二.JavaScript基本语法
1.JavaScript词法结构 所谓词法结构是指一套基础性规则,用来描述如何使用这门语言来编写程序,包括如下几项: ü 字符集unicode ü 区分大小写 (true和TRUE) ü 忽略空白字符 ...
- Eureka系列(一)Eureka功能介绍
Eureka核心功能点 服务注册(register): Client会发送一次Rest请求给Server端来实现注册,Server接受到请求会将服务信息存储起来,并将注册信息给同集群其他Serve ...
- 【软件测试 Python自动化】全网最全大厂面试题,看完以后你就是面试官!
前言 为了让大家更好的理解和学习投入到Python自动化来找到一份好的资料也是学习过程中,非常重要的一个点.你的检索能力越强,你就会越容易找到最合适你的资料. 有需要的小伙伴可以复制群号 313782 ...
- 百测学习之postman-接口测试
一.postman的请求 1.url与uri的区别 url与uri的区别 http://doc.nnzhp.cn/ http+host(域名)+path路径(uri) 2.g ...