JDK1.7-HashMap原理
JDK1.7 HashMap
如何在源码上添加自己的注释
打开jdk下载位置

解压src文件夹,打开idea,ctrl+shift+alt+s打开项目配置
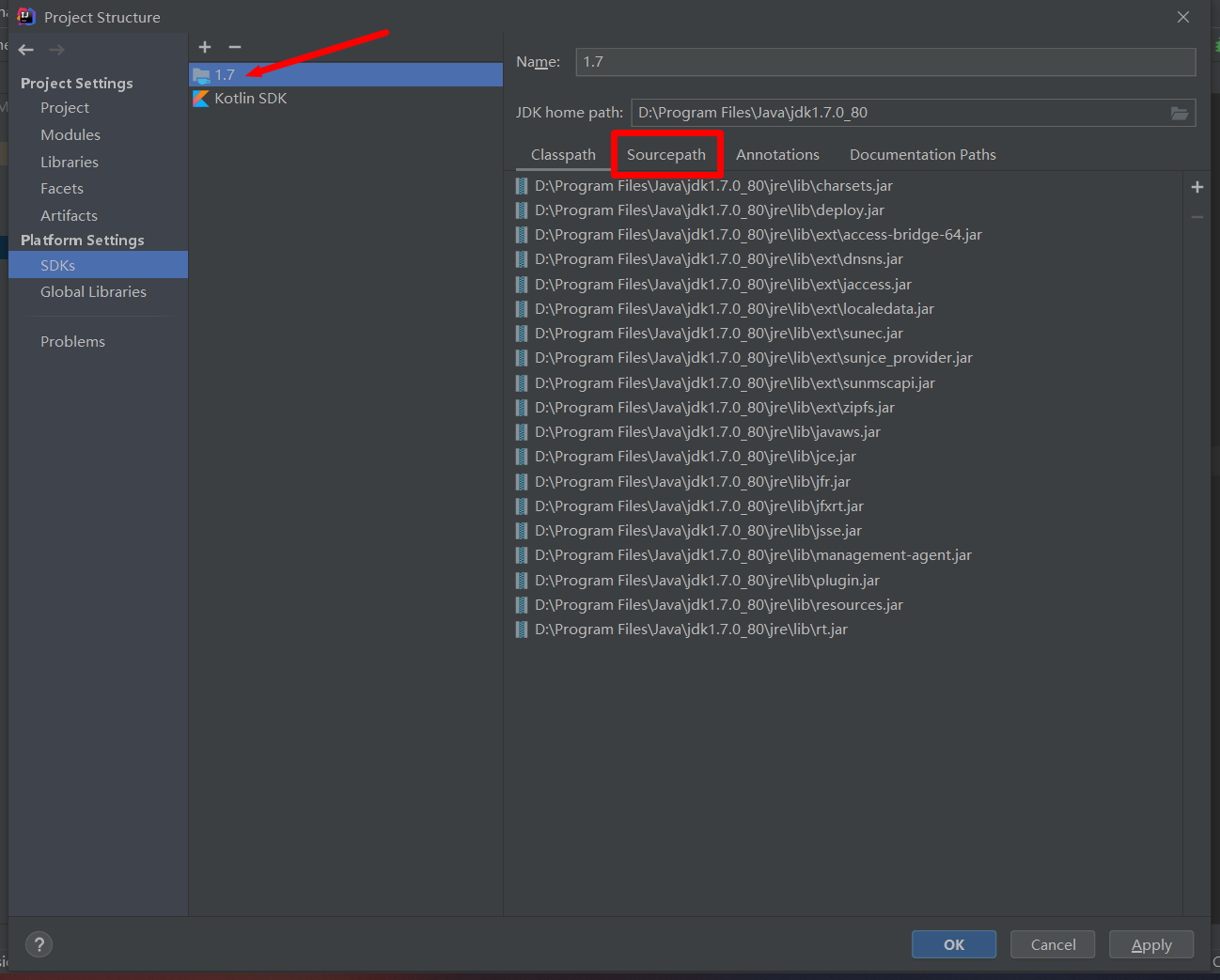
选择jdk版本1.7,然后点击Sourcepath
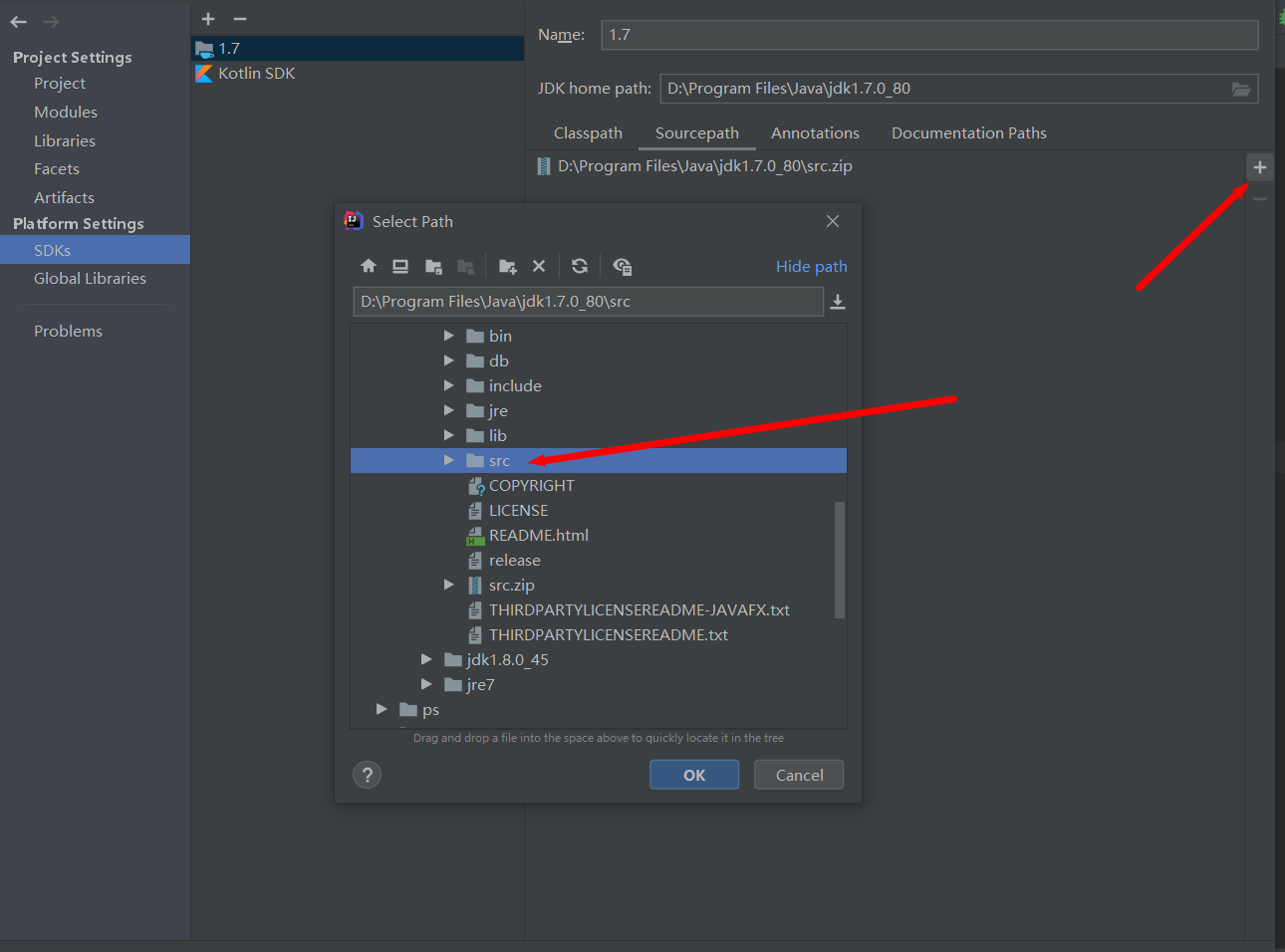
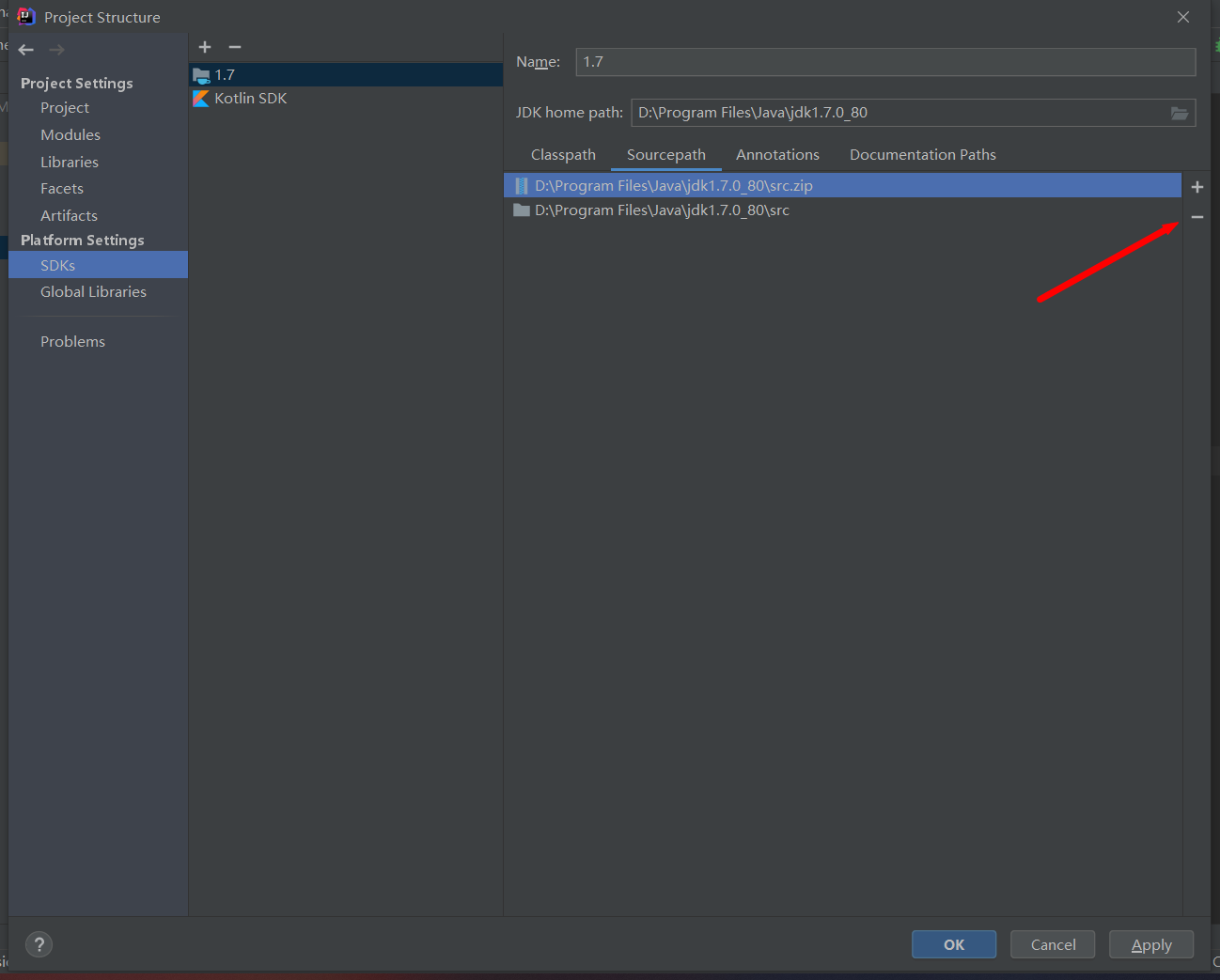
选择刚刚解压的src文件目录,然后选择src.zip的文件点击- 号,项目中只留下刚才解压的src文件即可
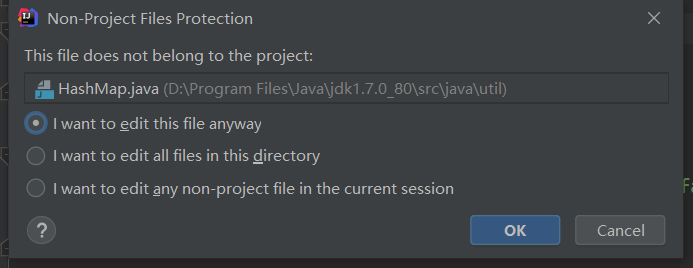
打开源码,输入时会出一个提示框,直接点击ok即可,然后就可以输入自己的注释了
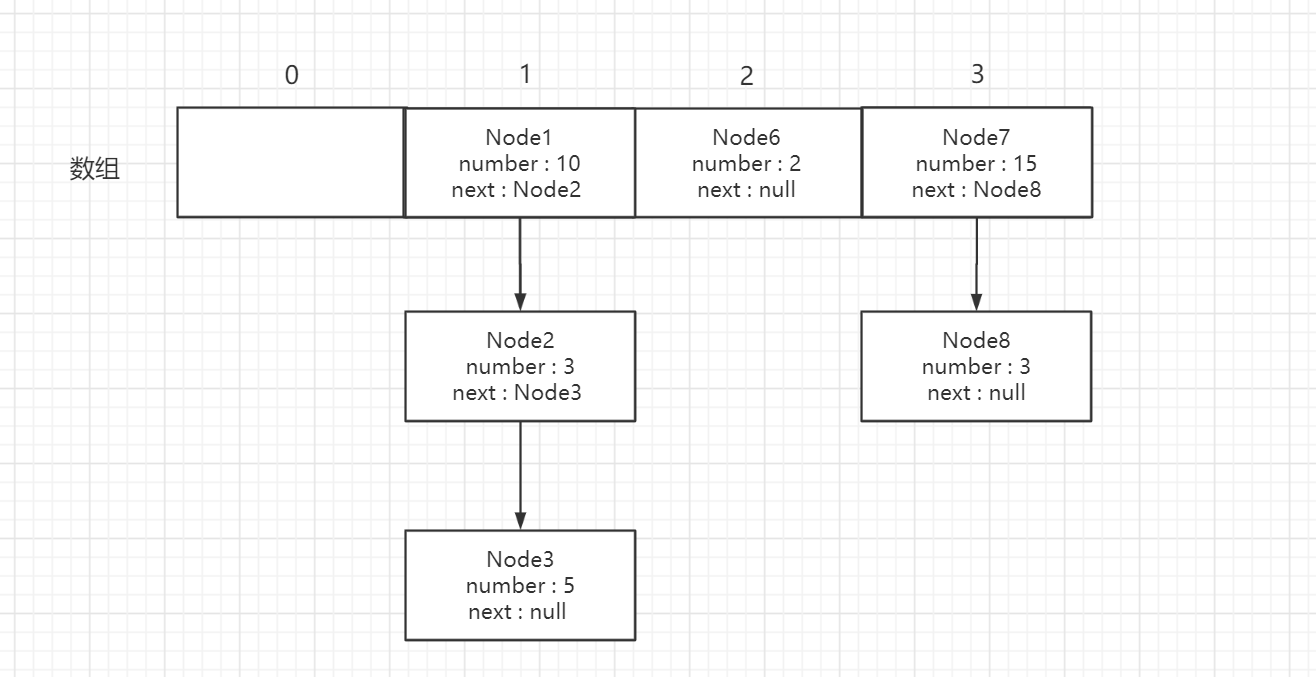
在开始前先了解一下JDK1.7的HashMap的数据结构,就算没有研究过源码也听过JDK1.7中HashMap是数组加链表,1.8中是数组加链表加红黑树,今天我们主要研究1.7,首先数组肯定都知道,链表这个一听以为是很难的东西,其实一点也不难
什么叫链表呢,以java代码形式
假设现在有一个节点,里有具体的值和下一个节点的引用
public class Node{
private int number;
private Node next;
}
当节点的next引用指向下一个Node节点,许多的节点连接起来就叫做链表
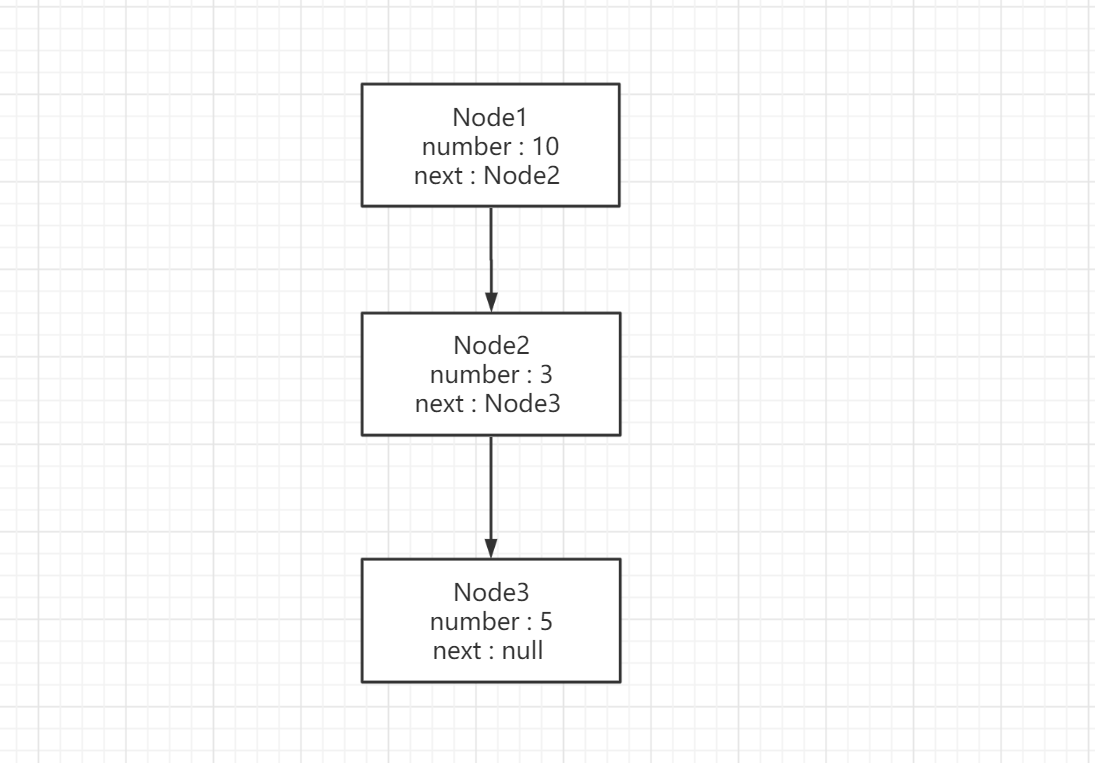
JDK1.7的数据结构就是如下图所示
在开始前建议自己跟着打开对应的类,方法来自己看一看源码,不然很容易就不知道在哪里了
HashMap中的全局变量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final Entry<?, ?>[] EMPTY_TABLE = {};
transient Entry<K, V>[] table = (Entry<K, V>[]) EMPTY_TABLE;
transient int size;
int threshold;
final float loadFactor;
transient int modCount;
我们来看一下全局变量,简单描述一下它们的作用
DEFAULT_INITIAL_CAPACITY
默认的初始容量,而大小使用了一个左移运算符,怎么来看它的值呢?java中所有的位运算都是在二进制的情况下进行的
首先1的二进制是 0000 0001 而<< 4 符号的意思是将所有的数字往左边移动4位,移出来的位置用0替换
也就是 0001 0000 转换为10进制就是16,也就是HashMap的默认容量
MAXIMUM_CAPACITY
最大容量,也是使用位运算符,1<<30 转换为10进制就是1073741824
DEFAULT_LOAD_FACTOR
默认的负载因子,默认为0.75f,现在可能不太清楚先有个印象即可
Entry[] EMPTY_TABLE
初始化的一个空数组
Entry<K, V>[] table = (Entry<K, V>[]) EMPTY_TABLE
真正存储数据的数组
size
存储元素的个数,map.size()方法就是直接返回这个变量
public int size() {
return size;
}
threshold
临界值,当容量到达这个容量是进行判断是否扩容,而这个临界值计算公式就是,容量大小乘以负载因子,如果初始化没有设置map的大小和负载因子的话,默认就是16*0.75=12
loadFactor
如果创建HashMap时设置了负载因子,那么会赋值给这个变量,没有特殊需求的话一般不需要设置这个值,太大导致链表过长,影响get方法,太小会导致经常进行扩容浪费性能
modCount
HashMap的结构被修改的次数,用于迭代器
构造方法
首先来看无参构造
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
调用了重载的构造,传入的就是默认大小(16)和默认的负载因子大小(0.75f)
那么我们来看有参构造
public HashMap(int initialCapacity, float loadFactor) {
//初始容量不能小于0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//初始容量是否大于最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
//如果大于最大容量,则将容量设置为最大容量
initialCapacity = MAXIMUM_CAPACITY;
//如果负载系数小于0或者不是一个数字抛出异常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 设置负载因子,临界值此时为容量大小,后面第一次put时由inflateTable(int toSize)方法计算设置
this.loadFactor = loadFactor;
threshold = initialCapacity;
//空方法,由其他实现类实现
init();
}
put方法
扩容就是在put方法中实现的,来看代码
public V put(K key, V value) {
// 如果table引用指向成员变量EMPTY_TABLE,那么初始化HashMap(设置容量、临界值,新的Entry数组引用)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// HashMap 支持key为null
if (key == null)
//key为null单独调用存储空key的方法
return putForNullKey(value);
//计算key的hash值
int hash = hash(key);
// 根据hash值和表当前的长度,得到一个在数组中的下标,重点关注一下indexFor方法的实现。
// 该算法主要返回一个索引,0 到 table.length-1的数组下标。
int i = indexFor(hash, table.length);
//接下来,找到 table[i]处,以及该处的数据链表,看是否存在相同的key;判断key相同,
// 首先判断hash值是否相等,然后再 判断key的equals方法是否相等
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//首先判断hash,如果对象的hashCode方法没有被重写,那么hash值相等两个对象一定相等
//并且判断如果key相等或者key的值相等那么覆盖并返回旧的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//进行添加操作
addEntry(hash, key, value, i);
return null;
}
我们来一步一步看,首先来看第一个判断
// 如果table引用指向成员变量EMPTY_TABLE,那么初始化HashMap(设置容量、临界值,新的Entry数组引用)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
如果这个判断成立,也就是说这个数组还没有进行过初始化,则调用inflateTable(threshold);方法来进行初始化,传入的参数为临界值,我们来看inflateTable方法
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
// 首先计算容量, toSize 容量为 threshold,在构造方法中,threshold默认等于初始容量,也就是16
int capacity = roundUpToPowerOf2(toSize);
// 然后重新计算 threshold的值,默认为 capacity * loadFactor
//Math.min 方法用于返回两个参数中的最小值
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//初始化数组 容量为 capacity
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
roundUpToPowerOf2方法,简单来看一下这个方法的作用
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
//判断参数的值是否大于最大容量
return number >= MAXIMUM_CAPACITY
//如果大于将返回最大容量
? MAXIMUM_CAPACITY
/**
* 如果小于1返回1
* highestOneBit方法可以简单理解为返回小于等于输入的数字最近的2的次方数
* 例如
* 2的1次方 2
* 2的2次方 4
* 2的3次方 8
* 2的4次方 16
* 2的5次方 32
* 小于15,并且距离15最近的2的次方数 : 8
* 小于16,并且距离15最近的2的次方数 : 16
* 小于17,并且距离15最近的2的次方数 : 16
*/
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
具体方法实现就不继续研究了,不是这篇的主题,继续来看inflateTable方法中内容
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
这一步操作是重新计算threshold的值,也就是临界值,通过计算出的容量大小乘以负载因子大小来算出临界值的大小
Math.min方法是判断两个值大小,返回小的那个,如果参数具有相同的值,则结果为相同的值。如果任一值为NaN,则结果为NaN
之后将初始化一个Entry类型的数组赋值给table
//初始化数组 容量为 capacity
table = new Entry[capacity];
那么我们现在来看一下这个Entry类
static class Entry<K, V> implements Map.Entry<K, V> {
final K key;
V value;
Entry<K, V> next;
int hash;
}
那么和开头举的例子Node基本一样的思路,在类中单独定义一个用来存储下一个节点的变量next
回到put方法,来看下一个判断
// HashMap 支持key为null
if (key == null)
//key为null单独调用存储空key的方法
return putForNullKey(value);
我们来看一下这个putForNullKey方法
private V putForNullKey(V value) {
//获取下标为0的Entry节点
for (Entry<K, V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
//空方法
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
在HashMap中,key为null的entry会存储在下标0的位置,上面进行覆盖操作,来看addEntry方法
void addEntry(int hash, K key, V value, int bucketIndex) {
/* JDK1.7以后的扩容条件;size大于等于threshold,并且新添加元素所在的索引值不等为空
也就是即使当size达到或超过threshold,新增加元素,只要不会引起hash冲突则不扩容;
JDK1.8去掉了为null的判断
*/
if ((size >= threshold) && (null != table[bucketIndex])) {
//将大小扩容到原来的两倍
resize(2 * table.length);
//如果key为null,将放到index为0的位置,否则进行取hash的操作
hash = (null != key) ? hash(key) : 0;
//根据获取的hash值进行获取下标
bucketIndex = indexFor(hash, table.length);
}
//创建entry
createEntry(hash, key, value, bucketIndex);
}
来看扩容resize()方法,传入的是2倍的旧数组的长度
void resize(int newCapacity) {
//将旧table赋值给oldTable
Entry[] oldTable = table;
//获取旧table长度
int oldCapacity = oldTable.length;
//如果长度已经等于最大限制设置为Integer的最大值
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//创建新table,长度为参数为传入的参数newCapacity
Entry[] newTable = new Entry[newCapacity];
//该方法将oldTable的数据复制到了newTable
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//将新扩容的table改为当前hashmap的存储table
table = newTable;
//重新计算阈值
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
在扩容方法中主要关注将数据转移的transfer方法
void transfer(Entry[] newTable, boolean rehash) {
//获取新创建的table长度
int newCapacity = newTable.length;
//遍历旧table
for (Entry<K, V> e : table) {
/*代码第一次判断如果当前下标entry是否为空,
如果为空则切换到下一个Entry节点
如果不为空,第二次就是判断当前下标的entry是否形成链表
如果形成链表将一直判断是否有下一个节点,当把该下标链表遍历完毕后,
然后切换到下一个entry节点进行相同的操作
* */
while (null != e) {
//获取下一个entry
Entry<K, V> next = e.next;
if (rehash) {
/**
* 判断e.key是否为null,如果为null将e.hash赋值为0
* 否则调用hash()方法进行计算hash
*/
e.hash = null == e.key ? 0 : hash(e.key);
}
//通过当前遍历旧表的entry的hash值和新table的长度来获取在新表的下标位置
int i = indexFor(e.hash, newCapacity);
/*
* jdk1.7是进行头插法,也就是不需要知道当前下标位置是否存在Entry
* 只需要将旧表中Entry节点,通过计算出下标位置
* 在新添加的Entry中直接将当前下标元素赋值给next属性,然后新添加的节点赋值给当前下标
*/
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
其中有几个需要关注的方法
//hash()======这个方法简单理解为来通过key来计算hash,在get时通过hash可以确保是同一个entry对象
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded & ~
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//indexFor()===========
/**
这里使用&于运算符,两个相同为1返回1,否则返回0,例如
0010 1101
1010 1011
结果 0010 1001
*/
static int indexFor(int h, int length) {
return h & (length - 1);
}
我们现在回到resize扩容方法,这个方法中最主要的就是这个将旧数组中数据复制到新数组中这个transfer()方法了,其他的操作上面都有注释,对应着看应该可以看懂
这里再主要说一下indexFor方法,在初始化HashMap时为什么在设置初始大小的时候必须为2的倍数
下面以HashMap初始化大小为16为例
首先&运算符两都为1才为1,否则为0
假设hash值为....1010 1010 而现在hashmap的长度为16,即(16-1)=15
hash:1010 1010
15: 0000 1111
因为15的低四位为1,也就是说通过&位运算符能对结果造成影响的只有低四位的四个1,其他高为都为0
这也是hash()方法的用处尽量让其他位参与hash运算,达到更加分散的hash值
假设初始大小为单数,例如15,那么通过(length - 1);,结果为14,14的二进制为
0000 1110
那么和计算出的hash进行&运算能对结果进行影响的位数会减少1位,这还是好的情况,如果传入的初始大小为17那么会怎样?
17通过length-1的操作为16,16的二进制为0001 0000,那么再和hash值进行&的操作
hash: 1010 1010
16: 0001 0000
只有两种情况,0000 0000 和0001 0000 ,那么设置的hashmap的大小将毫无作用,
只会在0000 0000 和0001 0000 的位置进行put操作,而0000 0000 为0下标,用来添加null的key那么添加的数据将会全部添加 到16的位置!
那我们回到addEntry()方法中
void addEntry(int hash, K key, V value, int bucketIndex) {
/* JDK1.7以后的扩容条件;size大于等于threshold,并且新添加元素所在的索引值不等为空
也就是当size达到或超过threshold,新增加元素,只要不会引起hash冲突则不扩容;
JDK1.8去掉了为null的判断
*/
if ((size >= threshold) && (null != table[bucketIndex])) {
//将大小扩容到原来的两倍
resize(2 * table.length);
//如果key为null,将放到index为0的位置,否则进行取hash的操作
hash = (null != key) ? hash(key) : 0;
//根据获取的hash值进行获取下标
bucketIndex = indexFor(hash, table.length);
}
//创建entry
createEntry(hash, key, value, bucketIndex);
}
resize()方法下面取hash操作的hash()方法和获取下标的indexFor方法都已经在上面写过,这里就不再赘述
接下来主要来看createEntry方法
void createEntry(int hash, K key, V value, int bucketIndex) {
//先获取当前下标entry节点,也可能为null
Entry<K, V> e = table[bucketIndex];
//如果有entry节点,那么在添加新的entry时将会形成链表
table[bucketIndex] = new Entry<>(hash, key, value, e);
//将hashmap的大小加1
size++;
}
因为hash值,所在下标位置都已经获取过了,所以方法传入参数直接使用
到这里put方法中putForNullKey()添加null key的方法就完成了,我们返回put方法继续
//put方法,省略一些刚刚写过的方法
int hash = hash(key);
int i = indexFor(hash, table.length);
//接下来,找到 table[i]处,以及该处的数据链表,看是否存在相同的key;判断key相同,
// 首先判断hash值是否相等,然后再 判断key的equals方法是否相等
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//首先判断hash,如果对象的hashCode方法没有被重写,那么hash值相等两个对象一定相等
//并且判断如果key相等或者key的值相等那么覆盖并返回旧的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//进行添加操作
addEntry(hash, key, value, i);
return null;
最上面hash()和indexFor()方法上面写过,不再赘述,中间的判断覆盖参考注释应该可以理解,而下面的addEntry方法上面也写过
get方法
如果理解了put方法后,get方法会相对简单很多
public V get(Object key) {
//判断如果key等于null的话,直接调用得到nullkey的方法
if (key == null)
return getForNullKey();
//通过getEntry方法的到entry节点
Entry<K, V> entry = getEntry(key);
//判断如果为null返回null,否则返回entry的value
return null == entry ? null : entry.getValue();
}
首先来看key为null的情况
private V getForNullKey() {
//如果hashmap的大小为0返回null
if (size == 0) {
return null;
}
/**
开始研究时有个问题困扰着我,写博客时突然明白了,
问题就是既然已知key为null的entry都会被放入下标0的位置,为什么还要循环,直接获取0下标的entry覆盖不行吗
然后我在写indexFor方法时想到,不仅仅null的key下标为0,如果一个hash算法算完后通过indexFor方法
算出的下标正好是0呢,它就必须通过循环来找到那个key为null的entry
*/
for (Entry<K, V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
逻辑比较简单,就不解释了,我们回到get看下一个getEntry方法
final Entry<K, V> getEntry(Object key) {
//如果hashmap的大小为0返回null
if (size == 0) {
return null;
}
//判断key如果为null则返回0,否则将key进行hash
int hash = (key == null) ? 0 : hash(key);
//indexFor方法通过hash值和table的长度获取对应的下标
//遍历该下标下的(如果有)链表
for (Entry<K, V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//判断当前entry的key的hash如果和和参入的key相同返回当前entry节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
到此JDK1.7中HashMap的基本get,put方法就完成了
本文仅个人理解,如果有不对的地方欢迎评论指出或私信,谢谢٩(๑>◡<๑)۶
JDK1.7-HashMap原理的更多相关文章
- JDK1.8 HashMap源码分析
一.HashMap概述 在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时 ...
- Java:HashMap原理与设计缘由
前言 Java中使用最多的数据结构基本就是ArrayList和HashMap,HashMap的原理也常常出现在各种面试题中,本文就HashMap的设计与设计缘由作出一一讲解,并解答面试常见的一些问题. ...
- java中HashMap原理?
参考:https://www.cnblogs.com/yuanblog/p/4441017.html(推荐) https://blog.csdn.net/a745233700/article/deta ...
- ==和equasl、hashmap原理(***)
public class String01 { public static void main(String[] args) { String a="test"; String b ...
- Java基础-hashMap原理剖析
Java基础-hashMap原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是哈希(Hash) 答:Hash就是散列,即把对象打散.举个例子,有100000条数 ...
- JDK1.8 HashMap$TreeNode.balanceInsertion 红黑树平衡插入
红黑树介绍 1.节点是红色或黑色. 2.根节点是黑色. 3.每个叶子节点都是黑色的空节点(NIL节点). 4 每个红色节点的两个子节点都是黑色.(从每个叶子到根的所有路径上不能有两个连续的红色节点) ...
- JDK1.8 HashMap$TreeNode.rotateLeft 红黑树左旋
红黑树介绍 1.节点是红色或黑色. 2.根节点是黑色. 3.每个叶子节点都是黑色的空节点(NIL节点). 4 每个红色节点的两个子节点都是黑色.(从每个叶子到根的所有路径上不能有两个连续的红色节点) ...
- HashMap原理(二) 扩容机制及存取原理
我们在上一个章节<HashMap原理(一) 概念和底层架构>中讲解了HashMap的存储数据结构以及常用的概念及变量,包括capacity容量,threshold变量和loadFactor ...
- jdk1.8 HashMap底层数据结构:深入解析为什么jdk1.8 HashMap的容量一定要是2的n次幂
前言 1.本文根据jdk1.8源码来分析HashMap的容量取值问题: 2.本文有做 jdk1.8 HashMap.resize()扩容方法的源码解析:见下文“一.3.扩容:同样需要保证扩容后的容量是 ...
- JDK1.7 hashMap源码分析
了解HashMap原理之前先了解一下几种数据结构: 1.数组:采用一段连续的内存空间来存储数据.对于指定下标的查找,时间复杂度为O(1),对于给定元素的查找,需要遍历整个数据,时间复杂度为O(n).但 ...
随机推荐
- 第 2 篇 Scrum 冲刺博客
一.站立式会议 1.站立式会议照片 2.昨天已完成的工作 ①大部分同学成功用java连接数据库 ②前端和后台的成员成功讨论并了解具体需求 3.今天计划完成的工作 ①帮助不会的同学连接数据库 ②登录识别 ...
- 七、git学习之——使用GitHub、自定义Git、
原文来自 一.使用GitHub 我们一直用GitHub作为免费的远程仓库,如果是个人的开源项目,放到GitHub上是完全没有问题的.其实GitHub还是一个开源协作社区,通过GitHub,既可以让别人 ...
- 容器编排系统之Kubectl工具的基础使用
前文我们了解了k8s的架构和基本的工作过程以及测试环境的k8s集群部署,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/14126750.html:今天我们主要来 ...
- I/O方式(本章最重要)
目录 程序查询方式 程序查询方式接口结构 例题 本节回顾 程序中断方式 中断的基本概念 工作流程 中断请求 分类 中断请求标记 中断响应 判优实现 优先级设置 中断处理过程 中断隐指令 硬件向量法 中 ...
- beautiful soup 遇到class标签的值中含有空格的处理
用Python写一个爬虫,用BeautifulSoup解析html.其中一个地方需要抓取下面两类标签:<dd class="ab " >blabla1</dd&g ...
- html 04-HTML标签图文详解(一)
04-HTML标签图文详解(一) #一.排版标签 #注释标签 <!-- 注释 --> #段落标签<p> <p>This is a paragraph</p ...
- Python自动化测试入门必读(最新)
入门自动化测试必读 自动化测试概念 自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程.通常,在设计了测试用例并通过评审之后,由测试人员根据测试用例中描述的规程一步步执行测试,得到实际结果与期 ...
- [Python] iupdatable包:获取电脑主板信息(csproduct)
一.说明 使用命令行就可以获取到主板相关的信息 wmic csproduct get /value 输出内容如下: Caption=Computer System Product Descriptio ...
- 7.自定义ViewGroup-下滑抽屉
1.效果 2.思路 分析效果: 1.布局分为两部分,后面部分,前面部分,默认状态后面被挡住: 2.后面不可以滑动,前面可以滑动: 3.如果前面的布局本身是可以滑动的,那么当前面布局滑动到第一个时,后面 ...
- Spring源码深度解析之Spring MVC
Spring源码深度解析之Spring MVC Spring框架提供了构建Web应用程序的全功能MVC模块.通过策略接口,Spring框架是高度可配置的,而且支持多种视图技术,例如JavaServer ...