python实现查有道词典
因为要考英语四级,所以我今天一大早就起来被英语单词,但是作为英语渣渣的我,只能是在网页上挨个查单词的意思。查的多了,心生厌倦,便想着如何才能在终端下查单词,那样速度不就很快了?
NOW,我仔细观察每次查询时,浏览器地址栏中URL的变化,发现每次浏览器提交的URL都是"http://www.youdao.com/w/eng/"xxxxx"/#keyfrom=dict2.index"(其中的xxxxx代表要查的单词),有了这个发现,那我们将URL指向的网页下载下来,然后提取我们需要的信息不就得了?
这个工作交给Python来做是最合适不过的了
因为要英汉互译,所以我写了两段代码,第一个是汉译英,第二个是英译汉。(最后将两段代码合起来实现自动识别英语或汉语,但是正确性和效率比分开写差那么一点点,不过大多数时间我还是查英语的汉语意思)
源代码
汉译英:
import requests,re
def download(): word=input("请输入您要翻译的中文词语:\n") url="http://dict.youdao.com/w/eng/"+word+"/#keyfrom=dict2.index" #合并URL地址 html=requests.get(url).content.decode('utf-8') #得到服务器的相应信息后将其转码为UTF-8 return html def analysis(): list1=re.findall("详细释义.+<p class=\"collapse-content\">",download(),re.S) #这里对html字符串进行第一步加工,截取大概的信息 list2=re.findall(" [a-zA-Z ]+",str(list1)) #将上面加工后的字符串进一步加工,直接提取到所有翻译后的单词信息 print("翻译结果:\n") for i in list2: i=i.strip() #因为第二步加工后的信息并不干净,得到的单词前面会有空格,这里将空格删去 print(i) if __name__ == '__main__': while(1):
analysis()
英译汉:
import requests,re
def download():
word=input("请输入您要翻译的英文单词:\n")
url="http://dict.youdao.com/w/eng/"+word+"/#keyfrom=dict2.index"
html=requests.get(url).content.decode('utf-8')
return html
def analysis():
list1=re.findall("详细释义.+<p class=\"collapse-content\">",download(),re.S)
list2=re.findall(" \w+",str(list1)) #只有此处代码与汉译英代码不同,因为是提取汉字,所以这里要用\w来匹配汉字
print("翻译结果:\n")
for i in list2:
i=i.strip()
print(i)
if __name__ == '__main__':
while(1):
analysis()
合并后:
import requests,re
def analysis():
word=input("请输入您要翻译的内容: ")
url="http://dict.youdao.com/w/eng/"+word+"/#keyfrom=dict2.index"
html=requests.get(url).content.decode('utf-8')
print("翻译结果:")
if ord(word[0].lower()) in range(97,123): #将输入的第一个字节转换为数字,如果数字的值在97到123之间输入的一定是英语,否则输入的是汉语
result=re.findall(r"(?<= )\w+(?=</span>)",html) #匹配翻译后的汉语
for i in result:
print(i)
else:
result=re.findall(r"(?<= )[a-zA-Z ]+(?=</span>)",html) #匹配翻译后的英语
for i in result:
if ord(i[0].lower()) in range(97,123): #上一步提取到的信息列表中有无用项(正则表达式中的空格造成的),这里过滤一下
print(i)
if __name__ == '__main__':
while(1):
analysis()
OK,来看看效果吧:
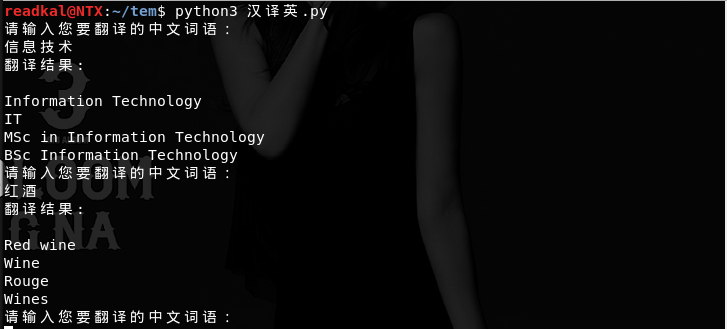

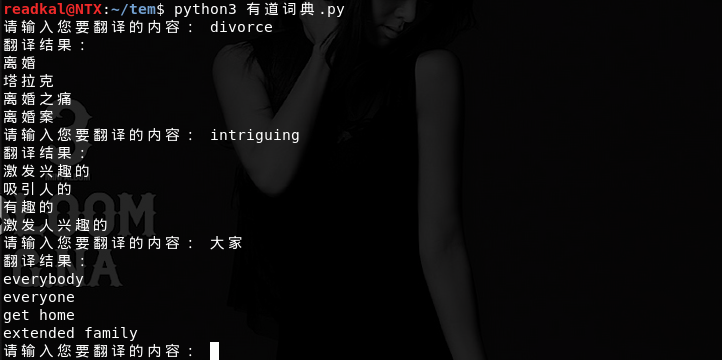
emmmm,OK,发完博客还要继续背单词【伤心】【伤心】【伤心】
python实现查有道词典的更多相关文章
- python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
1.有道的翻译 网页:www.youdao.com Fig1 Fig2 Fig3 Fig4 再次点击"自动翻译"->选中'Network'->选中'第一项',如下: F ...
- python:爬虫1——实战(下载一张图片、用Python模拟浏览器,通过在线的有道词典来对文本翻译)
一.下载一只猫 import urllib.request response = urllib.request.urlopen("http://cdn.duitang.com/uploads ...
- Python下载一张图片与有道词典
1.下载一张图片代码1 import urllib.request response = urllib.request.urlopen('http://photocdn.sohu.com/201009 ...
- python "爬虫+有道词典"实现一个简单翻译程序
抓包软件使用的是Fiddler4 新版的查询接口 比较负责,引入了salt和sign http://fanyi.youdao.com/translate?smartresult=dict&sm ...
- 基于pygtk的linux有道词典
基于pygtk的linux有道词典 一.桌面词典设计 想把Linux用作桌面系统,其中一部分障碍就是Linux上没有像有道一样简单易用的词典.其实我们完全可以自己开发一款桌面词典, 而且开发一款桌面词 ...
- mac 10.9开启有道词典取词功能
取词时候,有道词典给出提示,说要去开启辅助功能,但提示的是在mac 10.8上面怎么操作,在10.9的话,就是以下位置去改了. 补充以下: 在mac机器上,实际上大多数的单词都能从自带的词典中查找到. ...
- 爬虫破解js加密(一) 有道词典js加密参数 sign破解
在爬虫过程中,经常给服务器造成压力(比如耗尽CPU,内存,带宽等),为了减少不必要的访问(比如爬虫),网页开发者就发明了反爬虫技术. 常见的反爬虫技术有封ip,user_agent,字体库,js加密, ...
- 必应词典手机版(IOS版)与有道词典(IOS版)之软件分析【功能篇】【用户体验篇】
1.序言: 随着手机功能的不断更新和推广,手机应用市场的竞争变得愈发激烈.这次我们选择必应词典和有道词典的苹果客户端作对比,进一步分析这两款词典的客户端在功能和用户体验方面的利弊.这次测评的主要评测人 ...
- 调用网易有道词典api
# -*- coding: utf-8 -*- #python 27 #xiaodeng #调用网易有道词典api import urllib import json class Youdao(): ...
随机推荐
- AES加解密算法Qt实现
[声明] (1) 本文源码 在一位未署名网友源码基础上,利用Qt编程,实现了AES加解密算法,并添加了文件加解密功能.在此表示感谢!该源码仅供学习交流,请勿用于商业目的. (2) 图片及描述 除图1外 ...
- SpringBoot文档翻译系列——26.日志logging
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/7613854.html 这是SpringBoot的日志内容 26 日志 Spring使用Co ...
- MYSQL解压版安装说明
一. zip格式,解压缩之后要进行配置.解压之后可以将该文件夹改名,放到合适的位置,比如把文件夹改名为MySQL(文件夹 MySQL下面就是 bin, data,my-default.ini 等) 二 ...
- UWP brush
---some words---- 1.Alpha:透明度 2.Argb :Alpha red green blue 3.brush: [brʌʃ] 刷子,笔画,笔刷 4.fore 前头 5.F ...
- 手动添加 Git bash 到鼠标右键
由于不知原因,右键没有了Git Bash Here,没有这个右键菜单导致获取Git仓库中的代码很不方便,所以决定通过注册表的方式将这个菜单加出来. 1.win + R,输入"regedit& ...
- util包里的一些类的使用
好几天没有更新我的博客了 .国庆放假出去玩了一趟,这回来应该收心回到我的事业上了,哈哈哈!废话不多说,开始学习吧!首先今天来学习一些例子,这些例子可以回顾假期遗忘的知识,还能提高自己的能力.程序也会相 ...
- 【转载】jQuery全屏滚动插件fullPage.js
文章转载自dowebok http://www.dowebok.com/ 原文链接:http://www.dowebok.com/77.html 简介 如今我们经常能见到全屏网站,尤其是国外网站.这些 ...
- 笨鸟先飞之ASP.NET MVC系列之过滤器(04认证过滤器过滤器)
概念介绍 认证过滤器是MVC5的新特性,它有一个相对复杂的生命周期,它在其他所有过滤器之前运行,我们可以在认证过滤器中创建一个我们定义的认证方法,也可以结合授权过滤器做一个复杂的认证方法,这个方法可以 ...
- VMware Tools安装方法及共享文件夹设置方法
正确安装好VMware Tools后,可以实现主机与虚拟机之间的文件共享, 可以设置共享文件夹,以及在主机与虚拟机之间直接进行复制黏贴的操作. 安装方法: 选择"虚拟机"-> ...
- MVC(一)-MVC的基础认知
MVC是一种编程模式和设计思想,MVC大致切割为三个主要单元:Model(实体模型),View(视图),Contrller(控制器),MVC主要目在于简化软件开发的复杂度,让程序代码形成一个松耦合. ...