hadoop以及相关组件介绍以及个人理解
前言
本人是由java后端转型大数据方向,目前也有近一年半时间了,不过我平时的开发平台是阿里云的Maxcompute,通过这么长时间的开发,对数据仓库也有了一定的理解,ETL这些经验还算比较丰富。但是由于Maxcompute是一个更简单的大数据开发平台,导致个人在分布式计算的底层一些知识比较薄弱,所以这次决定花几个月时间好好学习一下hadoop,后续当然也会开始spark的学习。个人感觉这块学习的东西还是比较多,同时也要不断的实践的,所以这趟学习之旅,希望能够记录自己的一些心得体会,供自己参考,同时也希望能够和跟我一样刚入门的同学一起分享探讨。
注:我目前学习主要是参考官网文档,《Hadoop实战》,《Hadoop权威指南》
注2:本人主要是学习Hadoop的相关生态系统,去了解分布式计算大数据计算平台的底层的一些东西,所以期间我会抛弃一些运维相关的学习包括详细的部署,hadoop集群的安全策略等。
初始Hadoop
google的三篇论文(GFS,MapReduce,BigTable)很快促进了hadoop的面世,hadoop实际上起源于Nutch项目,于2006年2月正式启动,2008年开始hadoop正式火起来了。
Apache Hadoop和Hadoop 生态系统
- Common:一系列组件和接口,用于分布式文件系统和通用I/O
- Avro : 一种序列化系统,用于支持高效,跨语言的RPC和持久化数据存储
- MapReduce : 分布式数据处理模型和习性环境,也就是计算框架
- HDFS : 分布式文件系统
- Pig :数据流语言和运行环境,用以探究非常庞大的数据集。pig运行在MapReduce和HDFS之上
- Hive : 一种分布式呢的 、按列存储的数据仓库。HIVE管理HDFS中存储的数据,并提供基于SQL的查询语言
- HBase:一种分布式的、按列存储的数据库。HBase使用HDFS作为底层存储,同时支持MapReduce的批量式计算和点查询,类似BigTable
- ZooKeeper:一种分布式的、可用性高的协调服务。ZooKeeper提供分布式锁之类的基本服务用户构建分布式应用,对于java后端的 ,rpc相关的都是使用到ZooKeeper
- Sqoop:该工具用于在结构化数据存储和HDFS之间高效批量传输数据,也就是数据同步的工具
- Oozie:该服务用于运行和调度Hadoop作业,可以理解为一个工作流调度系统
HDFS和MapReduct体系结构
HDFS和MapReduce时Hadoop的两大核心,整个Hadoop的体系结构主要是通过HDFS俩实现分布式存储的底层支持的,并且会通过MapReduce来实现分布式并行任务处理的程序支持。
首先我们先来看一下HDFS的体系结构,HDFS采用了主从结构模型,HDFS集群是由一个NameNode(主)和若干个DataNode组成的,NameNode管理文件系统的命名空间和客户端对文件的访问操作;DataNode管理存储的数据;如下图:

接下来介绍一下MapReduce的体系结构,MapReduce框架是由一个单独运行在主节点的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。JobTracker负责调度构成一个作业的所有任务,从节点仅负责由主节点指派的任务。当一个job被提交时,JobTracker接收到提交作业和其配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
浅谈一下HDFS,HBase和Hive
刚开始接触这些概念的时候,感觉稀里糊涂,不清楚这几个之间到底是什么区别,之所以会产生混淆,因为这几个都是跟Hadoop的数据管理有关,下面我们就简单分析一下。
HDFS的数据管理
我们知道操作系统都有自己的文件管理系统,而HDFS就是hadoop的分布式文件管理系统,举个例子,我们有个100GB的文件,用HDFS可能是放到100台机器上存储的,而我们不需要关心它是怎么存储以及怎么读取的。我们从NameNode,client,DataNode来简单介绍一下HDFS对数据的管理。
文件写入:
client向NameNode发起文件写入的请求 -----> NameNode根据文件大小和文件块配置,返回给client相关的DataNode的信息----->client将文件划分多个block,写入DataNode
文件读取:
client向NameNode发起文件读取请求--->NameNode返回DataNode信息----->client读取文件
文件块block复制
NameNode发现部分文件的block有问题或者DataNode失效--->通知DataNode相互复制block------>DataNode开始直接相互复制
HBase的数据管理
HBase时一个类似Bigtable的分布式数据库,它的大部分特性和Bigtable一样,是一个稀疏的、长期存储的、多维度的排序映射表,这张表的索引时行关键字,列关键字和时间戳。
HBase的一些特性可以参考这篇文章http://blog.csdn.net/macyang/article/details/6066622,说实话,我现在对HBase的理解还是很模糊的,因为也没有场景遇到过。暂且先在此记一下相关概念。
Hbase体系结构三大重要组成部分:HRegion HBaseMaster HBase Client
Hive的数据管理
毫无疑问,Hive将是我们使用最多的工具,包括我在Maxcompute上开发,其实主要工作也是类似Hive QL,Hive的定义很简单,它是建立在Hadoop上的数据仓库基础框架,它提供了一系列的工具,来进行数据的ETL。Hive定义了简单的类SQL的查询语言,简称Hive QL。因为Hive是一个数据仓库框架,所以按照使用层次我们可以从元数据存储、数据存储和数据交换三个方面来介绍。
1.元数据存储
元数据其实就是数据仓库中表名称,表的列,表的分区,表分区的属性等,Hive将元数据存储在RDMS中。
2.数据存储
Hive咩有专门的数据存储格式,也没有未数据建立索引,用户在创建表的时候只需要告诉Hive数据中的列分隔符和行分隔符,它就能解析数据了。
其次,Hive中所有的数据都存储在HDFS中(因为Hive其实只是一个数仓的框架,它是不包括存储的,我们可以简单的理解为通过列和行的分隔符,将文件中的每行数据映射成表的一条记录)
3.数据交换
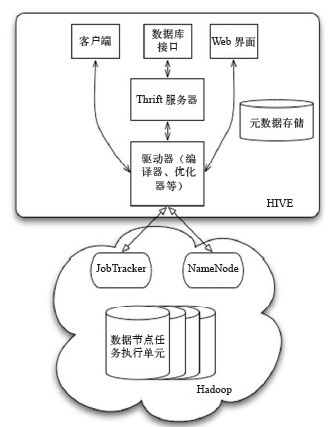
我们通常使用Hive客户端链接HiveServer,当然也可以通过web界面去写sql,Hive的大部分查询实际上都是利用MapReduce进行计算的
另外,下图是Hive的数据交换图,我们可以简单的看一下
hadoop以及相关组件介绍以及个人理解的更多相关文章
- Hadoop及其相关组件简介
一.大数据介绍 1.大数据指的是所涉及的数据量规模巨大到无法通过人工,在合理时间内达到截取.管理.处理.并整理成为人类所能解读的形式的信息. 2.大数据,可帮助我们能察觉商业趋势.判断研究质量.避免疾 ...
- Golden Gate 相关组件介绍:
OGG组件: Manager: 启动其它进程 Collector Extract Data Pump:可选进程,建议使用 Replicat Trails: 可以压缩,加密 Checkpoint OGG ...
- Hadoop以及组件介绍
一.背景介绍 在接触过大数据相关项目的时候常常都会听到Hadoop这个东西,简单来说,他是一个用分布式计算来处理大数据的开源软件,下面包含了许多的组件和子项目,这篇文章将会介绍Hadoop的原理以及一 ...
- 深入理解NIO(一)—— NIO的简单使用及其三大组件介绍
深入理解NIO(一)—— NIO的简单使用及其三大组件介绍 深入理解NIO系列分为四个部分 第一个部分也就是本节为NIO的简单使用(我很少写这种新手教程,所以如果你是复习还好,应该不难理解这篇,但如果 ...
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
RAC 工作原理和相关组件(三) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总.然后形成体 ...
- 从零自学Hadoop(19):HBase介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一篇, ...
- Android四大基本组件介绍与生命周期
Android四大基本组件介绍与生命周期 Android四大基本组件分别是Activity,Service服务,Content Provider内容提供者,BroadcastReceiver广播接收器 ...
- Shiro(一):shiro架构和组件介绍
简介 Apache Shiro是一个强大且易用的Java安全框架,执行身份认证.授权.加密和会话管理.使用Shiro的易于理解的API,可以快速.轻松地获得任何应用程序,从最小的移动应用程序到最大的网 ...
- 【转】【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
原文地址:http://www.cnblogs.com/baiboy/p/orc3.html 阅读目录 目录 RAC 工作原理和相关组件 ClusterWare 架构 RAC 软件结构 集群注册(OC ...
随机推荐
- ASP.NET MVC开发学习过程中遇到的细节问题以及注意事项
1.datagrid中JS函数传值问题: columns: { field: 'TypeName', title: '分类名称', width: 120, sortable: true, format ...
- 跨域CORS
一.跨域CORS是什么 当一个资源从与该资源本身所在的服务器的域或端口不同的域或不同的端口请求一个资源时,浏览器会发起一个跨域 HTTP 请求.出于安全考虑,浏览器会限制从脚本内发起的跨域HTTP请求 ...
- flask 扩展之 -- flask-sqlalchemy
flask-sqlalchemy.md 一. 安装 $ pip install flask-sqlalchemy 二. 配置 配置选项列表 : 选项 说明 SQLALCHEMY_DATABASE_UR ...
- Spring boot 1: 使用IDEA创建Spring boot项目
项目用到的环境: Windows 10 JDK8 IntelliJ IDEA 2017.1.3 Apache Tomcat 8 Maven 3.3.3 使用IDEA新建spring boot项目 新建 ...
- JS添加类似C# string.Format方法
String.prototype.format=function() { if(arguments.length==0) return this; for(var s=this, ...
- redhat 6.8 配置centos6的yum源
1. 检查是否安装yum包[root@node1 rpms]# rpm -qa|grep yum 2. 删除自带的yum包[root@node1 rpms]# rpm -qa|grep yum|xar ...
- DataFrame操作方式
DataFrame/DataSet 操作 Databricks 不止一次提到过希望未来在编写 Spark 应用程序过程中,对于结构化/半结构化数据,使用 Datasets(DataFrame 的扩展) ...
- 很好的复习资料: SQL语句到底怎么写 ?
本文用到的数据库如下: CREATE DATABASE exam; /*创建部门表*/ CREATE TABLE dept( deptno INT PRIMARY KEY, dname VARCHAR ...
- ajax数据请求3(数组json格式)
ajax数据请求3(数组json格式) <!doctype html> <html> <head> <meta charset="utf-8&quo ...
- 巧用五招提升Discuz!X运行速度
Discuz!X使用的是数据库应用程序,所以,当数据库的大小.帖子的数目.会员的数目,这些因素都会影响到程序的检索速度,尤其是当论坛的影响力大了,这个问题就更为突出了,虽然,康盛对Discuz进行了更 ...