Learning to Rank简介
Learning to Rank是采用机器学习算法,通过训练模型来解决排序问题,在Information Retrieval,Natural Language Processing,Data Mining等领域有着很多应用。
1. 排序问题
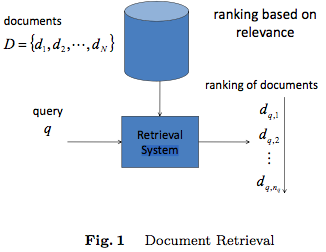
如图 Fig.1 所示,在信息检索中,给定一个query,搜索引擎会召回一系列相关的Documents(通过term匹配,keyword匹配,或者semantic匹配的方法),然后便需要对这些召回的Documents进行排序,最后将Top N的Documents输出。而排序问题就是使用一个模型 f(q,d)来对该query下的documents进行排序,这个模型可以是人工设定一些参数的模型,也可以是用机器学习算法自动训练出来的模型。现在第二种方法越来越流行,尤其在Web Search领域,因为在Web Search 中,有很多信息可以用来确定query-doc pair的相关性,而另一方面,由于大量的搜索日志的存在,可以将用户的点击行为日志作为training data,使得通过机器学习自动得到排序模型成为可能。
需要注意的是,排序问题最关注的是各个Documents之间的相对顺序关系,而不是各个Documents的预测分最准确。
Learning to Rank是监督学习方法,所以会分为training阶段和testing阶段,如图 Fig.2 所示。
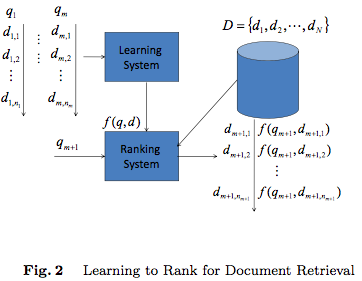
1.1 Training data的生成
对于Learning to Rank,training data是必须的,而feature vector通常都是可以得到的,关键就在于label的获取,而这个label实际上反映了query-doc pair的真实相关程度。通常我们有两种方式可以进行label的获取:
第一种方式是人工标注,这种方法被各大搜索引擎公司广为应用。人工标注即对抽样出来作为training data的query-doc pair人为地进行相关程度的判断和标注。一般标注的相关程度分为5档:perfect,excellent,good,fair,bad。例如,query=“Microsoft”,这时候,Microsoft的官网是perfect;介绍Microsoft的wikipedia则是excellent;一篇将Microsoft作为其主要话题的网页则是good;一篇只是提到了Microsoft这个词的网页则是fair,而一篇跟Microsoft毫不相关的网页则是bad。人工标注的方法可以通过多人同时进行,最后以类似投票表决的方式决定一个query-doc pair的相关程度,这样可以相对减少各个人的观点不同带来的误差。
第二种方式是通过搜索日志获取。搜索日志记录了人们在实际生活中的搜索行为和相应的点击行为,点击行为实际上隐含了query-doc pair的相关性,所以可以被用来作为query-doc pair的相关程度的判断。一种最简单的方法就是利用同一个query下,不同doc的点击数的多少来作为它们相关程度的大小。
不过需要注意的是,这里存在着一个很大的陷阱,就是用户的点击行为实际上是存在“position bias”的,即用户偏向于点击位置靠前的doc,即便这个doc并不相关或者相关性不高。有很多 tricky的和 general 的方法可以用来去除这个“position bias”,例如,
1. 当位置靠后的doc的点击数都比位置靠前的doc的点击数要高了,那么靠后的doc的相关性肯定要比靠前的doc的相关性大。
2. Joachims等人则提出了一系列去除bias的方法,例如 Click > Skip Above, Last Click > Skip Above, Click > Earlier Click, Click > Skip Previous, Click > No Click Next等。
3. 有个很tricky但是效果很不错的方法,之前我们说一个doc的点击数比另一个doc的点击数多,并不一定说明前者比后者更相关。但如果两者的差距大到一定程度了,即使前者比后者位置靠前,但是两者的点击数相差5-10倍,这时候我们还是愿意相信前者更加相关。当然这个差距的大小需要根据每个场景具体的调整。
4. position bias 存在的原因是,永远无法保证在一次搜索行为中,用户能够看到所有的结果,往往只看到前几位的结果。这时候就到了 Click Model大显身手的时候了,一系列的 Click Model 根据用户的点击信息对用户真正看到的doc进行“筛选”,进而能更准确地看出用户到底看到了哪些doc,没有看到哪些doc,一旦这些信息知道了,那么我们就可以根据相对更准确的 点击数/展示数(即展现CTR)来确定各个doc的相关性大小。
上述讲到的两种label获取方法各有利弊。人工标注受限于标注的人的观点,不同的人有不同的看法,而且毕竟标注的人不是真实搜索该query的用户,无法得知其搜索时候的真实意图;另一方面人工标注的方法代价较高且非常耗时。而从搜索日志中获取的方法则受限于用户点击行为的噪声,这在长尾query中更是如此,且有用户点击的query毕竟只是总体query的一个子集,无法获取全部的query下doc的label。
1.2 Feature的生成
这里只是简单介绍下,后续博客会有更纤细的讲解。
一般Learning to Rank的模型的feature分为两大类:relevance 和 importance(hotness),即query-doc pair 的相关性feature,和doc本身的热门程度的feature。两者中具有代表性的分别是 BM25 和 PageRank。
1.3 Evaluation
怎么判断一个排序模型的好坏呢?我们需要有验证的方法和指标。方法简单来说就是,比较模型的输出结果,和真实结果(ground truth)之间的差异大小。用于Information Retrieval的排序衡量指标通常有:NDCG,MAP等。
NDCG(Normalized Discounted Cumulative Gain):
NDCG表示了从第1位doc到第k位doc的“归一化累积折扣信息增益值”。其基本思想是:
1) 每条结果的相关性分等级来衡量
2) 考虑结果所在的位置,位置越靠前的则重要程度越高
3) 等级高(即好结果)的结果位置越靠前则值应该越高,否则给予惩罚
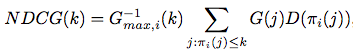
其中G表示了这个doc得信息增益大小,一般与该doc的相关程度正相关:
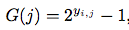
D则表示了该doc所在排序位置的折扣大小,一般与位置负相关:
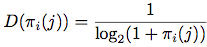
而Gmax则表示了归一化系数,是最理想情况下排序的“累积折扣信息增益值”。
最后,将每个query下的NDCG值平均后,便可以得到排序模型的总体NDCG大小。
MAP(Mean Average Precision):
其定义是求每个相关文档检索出后的准确率的平均值(即Average Precision)的算术平均值(Mean)。这里对准确率求了两次平均,因此称为Mean Average Precision。
在MAP中,对query-doc pair的相关性判断只有两档:1和0。
对于一个query,其AP值为:
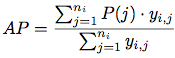
yij即每个doc的label(1和0),而每个query-doc pair的P值代表了到dij这个doc所在的位置为止的precision:
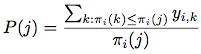
其中,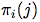 是dij在排序中的位置。
是dij在排序中的位置。
2. Formulation
用通用的公式来表示Learning to Rank算法,loss function为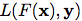 ,从而risk function(loss function在X,Y联合分布下的期望值)为:
,从而risk function(loss function在X,Y联合分布下的期望值)为:
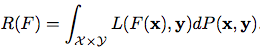
有了training data后,进一步得到empirical risk function:
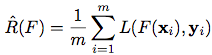
于是,学习问题变成了如何最小化这个empirical risk function。而这个优化问题很难解决,因为loss function不连续。于是可以使用一个方便求解的surrogate function来替换原始loss function,转而优化这个替换函数:
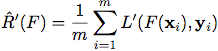
替换函数的选择有很多种,根据Learning to Rank的类型不同而有不同的选择:
1)pointwise loss:例如squared loss等。
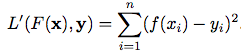
2)pairwise loss:例如hinge loss,exponential loss,logistic loss等。
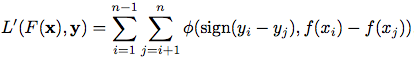
3)listwise loss:
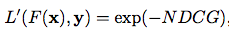
3. Learning to Rank Methods
Learning to Rank 方法可以分为三种类型:pointwise,pairwise,和listwise。
pointwise和pairwise方法将排序问题转化为classification,regression,ordinal classification等问题,优点是可以直接利用已有的classificatin和regression算法,缺点是group structure其实是被忽略的,即不会考虑每个query下所有doc之间的序关系。导致其学习目标和真实的衡量排序的目标并不一定是一致的(很多排序衡量指标,例如NDCG都是衡量每个query下的整体list的序关系的)。而listwise方法则将一个ranking list作为一个instance来进行训练,其实会考虑每个query下所有doc之间的序关系的。
这三种类型的Learning to Rank方法的具体算法一般有:
针对各个具体的算法介绍,后续的博客会进一步给出,这里就不再多加详述了。
版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。
Learning to Rank简介的更多相关文章
- 【机器学习】Learning to Rank 简介
Learning to Rank 简介 去年实习时,因为项目需要,接触了一下Learning to Rank(以下简称L2R),感觉很有意思,也有很大的应用价值.L2R将机器学习的技术很好的应用到了排 ...
- Learning to Rank 简介
转自:http://www.cnblogs.com/kemaswill/archive/2013/06/01/3109497.html,感谢分享! 本文将对L2R做一个比较深入的介绍,主要参考了刘铁岩 ...
- 搜索排序-learning to Rank简介
Learning to Rank pointwise \[ L\left(f ; x_{j}, y_{j}\right)=\left(y_{j}-f\left(x_{j}\right)\right)^ ...
- [Machine Learning] Learning to rank算法简介
声明:以下内容根据潘的博客和crackcell's dustbin进行整理,尊重原著,向两位作者致谢! 1 现有的排序模型 排序(Ranking)一直是信息检索的核心研究问题,有大量的成熟的方法,主要 ...
- Learning to Rank之Ranking SVM 简介
排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank简 ...
- Learning to Rank之RankNet算法简介
排序一直是信息检索的核心问题之一, Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank ...
- 【机器学习】Learning to Rank之Ranking SVM 简介
Learning to Rank之Ranking SVM 简介 排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning t ...
- 芝麻HTTP: Learning to Rank概述
Learning to Rank,即排序学习,简称为 L2R,它是构建排序模型的机器学习方法,在信息检索.自然语言处理.数据挖掘等场景中具有重要的作用.其达到的效果是:给定一组文档,对任意查询请求给出 ...
- Learning To Rank之LambdaMART前世今生
1. 前言 我们知道排序在非常多应用场景中属于一个非常核心的模块.最直接的应用就是搜索引擎.当用户提交一个query.搜索引擎会召回非常多文档,然后依据文档与query以及用户的相关程度对 ...
随机推荐
- 转:常用的iOS开源库和第三方组件
1.通过CocoaPods安装:
- lxc.conf解析&lxc容器能力
lxd启动容器实际是生成lxc.conf.剩下的就是LXC对容器进行控制了.所以可认为lxc.conf就是lxd和lxc之间主要的接口.lxc.conf详细属性参考: http://manpages. ...
- javascript作用域和闭包之我见
javascript作用域和闭包之我见 看了<你不知道的JavaScript(上卷)>的第一部分--作用域和闭包,感受颇深,遂写一篇读书笔记加深印象.路过的大牛欢迎指点,对这方面不懂的同学 ...
- php回滚
$m=D('YourModel');//或者是M();$m2=D('YouModel2');$m->startTrans();//在第一个模型里启用就可以了,或者第二个也行$result=$m- ...
- 百度地图API新手入门
最近,共享单车着实火了一把,市场竞争也是异常的激烈,百花争艳,百家争鸣,群雄逐鹿,最后鹿死谁手,现在还不得而知,不过可以肯定的是细节决定成败,更重要的还在于用户的体验. 用过的同学们都会知道,打开共享 ...
- Struts2框架(8)---Struts2的输入校验
Struts2的输入校验 在我们项目实际开发中在数据校验时,分为两种,一种是前端校验,一种是服务器校验: 客户端校验:主要是通过jsp写js脚本,它的优点很明显,就是输入错误的话提醒比较及时,能够减轻 ...
- SQL一次查出相关类容避免长时间占用表(下)
/* server: db: EDI */ -- 以下案例多次查询同一张表,仅有Name条件不同 --可以使用一次查出相关类容避免长时间占用表 USE EDI GO DECLARE @FileType ...
- 有关rip路由协议相关知识以及实例配置【第1部分】
有关rip路由协议相关知识以及实例配置[第一部分] RIP呢,这是一个比较重要的知识点,所以它的知识覆盖面很广泛:但是呢,我将会对碰到的问题进行一些分析解刨(主要是为了帮助自己理清思维):也希望能够从 ...
- 关于VS2013的编码的UI测试。
1. 打开VS2013,选择文件→新建→项目 2. 弹出的选项左侧选择visual C#中的测试,中间选择框选择编码的UI测试项目,确定后就产生的测试项目. 3. 弹出框选择默认的录制操作巴拉巴 ...
- C#基础笔记---浅谈XML读取以及简单的ORM实现
背景: 在开发ASP.NETMVC4 项目中,虽然web.config配置满足了大部分需求,不过对于某些特定业务,我们有时候需要添加新的配置文件来记录配置信息,那么XML文件配置无疑是我们选择的一个方 ...