elasticSearch(5.3.0)的评分机制的研究
1、 ElasticSearch的评分
在用ElasticSearch作为搜索引擎的时候,如果采用关键字进行查询,ElasticSearch会对每个符合查询条件的文档进行评分,在5.3.0的版本中,默认采用的是BM25的评分函数,关于BM25的评分函数,网络上有较多的讲解,这里就不进行详细说明,贴上几个连接如下:
https://en.wikipedia.org/wiki/Okapi_BM25
https://www.elastic.co/guide/en/elasticsearch/guide/2.x/pluggable-similarites.html#bm25
在ElasticSearch5.3.0中采用的函数计算如下:
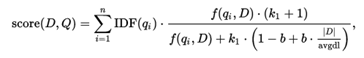
N表示将查询关键字分词后得到的N个term。
IDF=log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))
tfNorm=(freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength))
docCount:查询中满足查询条件的所有文档
docFreq:满足本条term的查询文档数目
IDF反映的是term的影响因子,如果docCount很大,docFreq很小,标示该term在doc之间具有很好的分辨力,当然IDF值也就越大。
freq:查询term在本doc的field中出现的次数
K1:调优参数默认为1.2
b:调优参数,默认为0.75
fieldLength:是满足查询条件的doc的filed的长度
avgFieldLength:是满足查询条件的所有doc的filed的长度.
tfNorm反映的该term在所有满足条件的doc中field中的重要性,一般来说,相同的freq 下,field的长度越短,那么取值就越高。
2、 Lucene中BM25的评分研究
在索引中插入3条数据,采用默认的
Analyzer analyzer = new StandardAnalyzer();
数据如下:
"text", "this hour chiness my book"
"text", "this is chiness chiness japan amc set the right context"
"text", "this book chiness jack1 the right context"
在程序中,用"text": "chiness"进行搜索,并且把把日志输出如下:
查找到的文档总共有:3
---------------
0.16786805 = weight(text:chiness in 1) [BM25Similarity], result of:
0.16786805 = score(doc=1,freq=2.0 = termFreq=2.0
), product of:
0.13353139 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
3.0 = docFreq
3.0 = docCount
1.2571429 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
2.0 = termFreq=2.0
1.2 = parameter k1
0.75 = parameter b
5.3333335 = avgFieldLength
7.111111 = fieldLength
0.16786803
this is chiness chiness japan amc set the right context
---------------
0.14874382 = weight(text:chiness in 0) [BM25Similarity], result of:
0.14874382 = score(doc=0,freq=1.0 = termFreq=1.0
), product of:
0.13353139 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
3.0 = docFreq
3.0 = docCount
1.113924 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
1.0 = termFreq=1.0
1.2 = parameter k1
0.75 = parameter b
5.3333335 = avgFieldLength
4.0 = fieldLength
0.14874382
this hour chiness my book
---------------
0.1346556 = weight(text:chiness in 2) [BM25Similarity], result of:
0.1346556 = score(doc=2,freq=1.0 = termFreq=1.0
), product of:
0.13353139 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
3.0 = docFreq
3.0 = docCount
1.008419 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
1.0 = termFreq=1.0
1.2 = parameter k1
0.75 = parameter b
5.3333335 = avgFieldLength
5.2244897 = fieldLength
0.1346556
this book chiness jack1 the right context
由日志可以知道,评分最高的为文档1,其次为文档0,最低的是文档2,原因是文档1中chiness出现了两次,文档0和2中都只出现了一次,但是由于文档0的text的fieldLength比文档2小,所以文档0的评分比文档2高。
avgFieldLength的长度可以知道是5.3333*3,约等于16,是因为this、is、the是停用词,去除后的短语是"hour chiness my book","chiness chiness japan amc set right context"和"book chiness jack1 right context".terms数量一共是16个,除以3那么就是5.3333。
问题来了:
这边有个问题,就是每个文档的字段长度好像跟我们输入的不一致,分别是
文档1,长度是 7.111111
文档0,长度是 4.0
文档2,长度是 5.2244897

都不是整数,而且跟我们去除停用词后的长度不一致,按道理将应该是6、4、5才对。
在lucene为了降低存储的空间,在存储field的长度时,没有存储实际长度,而是存储了一个byte类型的值(0-255),每个值对应了BM25Similarity有NORM_TABLE中的index,
在BM25Similarity有NORM_TABLE的float数组,实现了一个区间映射的功能。
/** Cache of decoded bytes. */
private static final float[] NORM_TABLE = new float[256];
static {
for (int i = 1; i < 256; i++) {
float f = SmallFloat.byte315ToFloat((byte) i);
NORM_TABLE[i] = 1.0f / (f * f);
}
NORM_TABLE[0] = 1.0f / NORM_TABLE[255]; // otherwise inf
}
输出内容如下:
0 5.6493154E19
1 2.95147899E18
2 2.04963825E18
3 1.50585663E18
4 1.1529215E18
………………….
112 64.0
113 40.96
114 28.444445
115 20.897959
116 16.0
117 10.24
118 7.111111
119 5.2244897
120 4.0
……………………
253 3.469447E-20
254 2.4093382E-20
255 1.770126E-20
反向操作吧,代码如下:
for (int i = 0; i < 100; i++) {
float x = 1.0f / i;
float y = (float) Math.sqrt(x);
System.out.println(i + " " + SmallFloat.floatToByte315(y));
}
0 -1
1 124
2 121
3 120
4 120
5 119
6 118
7 118
8 117
9 117
10 117
11 116
12 116
13 116
14 116
15 116
16 116
17 115
18 115
19 115
如果长度是4,写入值是120,长度是5,写入值是119,长度为6和7,那么在存储的时候写入值是118,取值的时候,文档2的取值就是NORM_TABLE[119],文档1的取值是NORM_TABLE[118],文档0的取值是NORM_TABLE[120]。
3、 ElasticSearch的评分注意点
在使用ElasticSearch提供搜索服务的时候,会发现一个很有意思的现象,在ElasticSearch中新建索引并且插入数据,命令如下
curl -XPUT 'http://127.0.0.1:9200/scoretest'
curl -XPUT 'http://127.0.0.1:9200/scoretest/scoretest/_mapping' -d '{"scoretest":{"properties":{"text":{"type":"text"}}}}'
curl -XPUT 'http://127.0.0.1:9200/scoretest/scoretest/1' -d '{"text":"this hour chiness my book"}'
curl -XPUT 'http://127.0.0.1:9200/scoretest/scoretest/2' -d '{"text":"this is chiness chiness japan amc set the right context"}'
curl -XPUT 'http://127.0.0.1:9200/scoretest/scoretest/3' -d '{"text":"this book chiness jack1 the right context"}'
执行查询命令
curl -XGET 'http://127.0.0.1:9200/scoretest/scoretest/_search' -d '{"query":{"match":{"text":"chiness"}}}'
结果如下:

问题来了:
chines出现两次的排名最靠前,chiness出现一次的,长度长的竟然比长度短的排名靠前,这个与我们想象中的不一致,
这次增加explain字段查看下分析过程。命令如下:
curl -XGET 'http://127.0.0.1:9200/scoretest/scoretest/_search' -d '{ "explain": true, "query":{"match":{"text":"chiness"}}}'
由于信息较多,就截取下主要的分析过程中的几个参数:
|
docFreq |
docCount |
avgFieldLength |
fieldLength |
|
|
1 |
1 |
1 |
5 |
5.2244897 |
|
2 |
1 |
1 |
10 |
10.24 |
|
3 |
1 |
1 |
7 |
7.11111 |
好像这个四个参数的取值与章节2中完全不一致,

原因是,ElasticSearch在建立index的时候,默认自动回建立5个分片,在插入数据的时候,会根据一致性算法将文档分配到某一个shard上,在进行搜索的时候,每个shard上独自进行搜索评分,然后汇总后,根据_score进行排序,然后在返回给前端,我们可以看下上述三个文档的分布,在我的实验中分布如下:
|
1 |
_shard 3 |
|
2 |
_shard 4 |
|
3 |
_shard 2 |
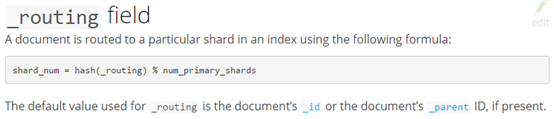
所以对于index下同一个type下面的数据,最好在插入的时候,数据存放到同一个shard上,这个采用系统默认评分的结果才会保持正确。这里就用到了ES的_routing参数,默认情况下ES是根据doc的_id作为hash的key,其官网描述如下:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-routing-field.html
重新测试下,这回指定_routing:
curl -XPUT 'http://127.0.0.1:9200/scoretestrouting'
curl -XPUT 'http://127.0.0.1:9200/scoretestrouting/scoretestrouting/_mapping' -d '{"scoretestrouting":{"_routing":{"required":true},"properties":{"text":{"type":"text"}}}}'
curl -XPUT 'http://127.0.0.1:9200/scoretestrouting/scoretestrouting/1' -d '{"text":"this hour chiness my book"}'
curl -XPUT 'http://127.0.0.1:9200/scoretestrouting/scoretestrouting/1?routing=wang' -d '{"text":"this hour chiness my book"}'
curl -XPUT 'http://127.0.0.1:9200/scoretestrouting/scoretestrouting/2?routing=wang' -d '{"text":"this is chiness chiness japan amc set the right context"}'
curl -XPUT 'http://127.0.0.1:9200/scoretestrouting/scoretestrouting/3?routing=wang' -d '{"text":"this book chiness jack1 the right context"}'
搜索命令如下:
curl -XGET 'http://127.0.0.1:9200/scoretestrouting/scoretestrouting/_search?routing=wang' -d '{ "explain": true, "query":{"match":{"text":"chiness"}}}'
查看结果如下:
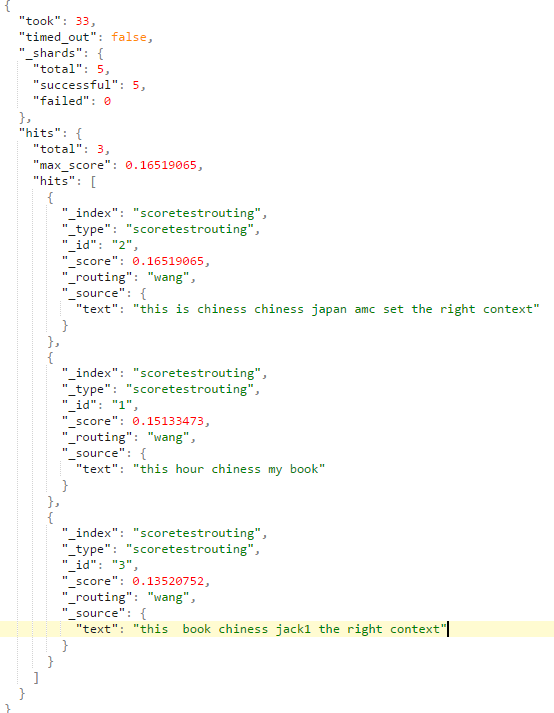
在添加"explain": true,看下详细的评分计算过程:
|
docFreq |
docCount |
avgFieldLength |
fieldLength |
|
|
1 |
3 |
3 |
7.3333335 |
5.2244897 |
|
2 |
3 |
3 |
7.3333335 |
10.24 |
|
3 |
3 |
3 |
7.3333335 |
7.11111 |

在没有指定_routing参数的情况下,使用_id代替或者父级文档的_parent字段代替,
注意点,在使用了指定_routing的情况下,在同一个index的下面,如果使用了不同的_routing,那么有可能存在两个文档具有相同的_id,但是存放在两个不同的shard上。
elasticSearch(5.3.0)的评分机制的研究的更多相关文章
- Android 8.0/9.0 wifi 自动连接评分机制
前言 Android N wifi auto connect流程分析 Android N selectQualifiedNetwork分析 Wifi自动连接时的评分机制 今天了解了一下Wifi自动连接 ...
- lucene 的评分机制
lucene 的评分机制 elasticsearch是基于lucene的,所以他的评分机制也是基于lucene的.评分就是我们搜索的短语和索引中每篇文档的相关度打分. 如果没有干预评分算法的时候,每次 ...
- Elasticseach的评分机制
lucene 的评分机制 elasticsearch是基于lucene的,所以他的评分机制也是基于lucene的.评分就是我们搜索的短语和索引中每篇文档的相关度打分. 如果没有干预评分算法的时候,每次 ...
- Solr In Action 笔记(2) 之 评分机制(相似性计算)
Solr In Action 笔记(2) 之评分机制(相似性计算) 1 简述 我们对搜索引擎进行查询时候,很少会有人进行翻页操作.这就要求我们对索引的内容提取具有高度的匹配性,这就搜索引擎文档的相似性 ...
- Wifi 评分机制分析
从android N开始,引入了wifi评分机制,选择wifi的时候会通过评分来选择. android O源码 frameworks\opt\net\wifi\service\java\com\and ...
- Lucene Scoring 评分机制
原文出处:http://blog.chenlb.com/2009/08/lucene-scoring-architecture.html Lucene 评分体系/机制(lucene scoring)是 ...
- Lucene 的 Scoring 评分机制
转自: http://www.oschina.net/question/5189_7707 Lucene 评分体系/机制(lucene scoring)是 Lucene 出名的一核心部分.它对用户来 ...
- Elasticsearch 7.4.0官方文档操作
官方文档地址 https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html 1.0.0 设置Elasticsea ...
- ELK——安装 logstash 2.2.0、elasticsearch 2.2.0 和 Kibana 3.0
本文内容 Elasticsearch logstash Kibana 参考资料 本文介绍安装 logstash 2.2.0 和 elasticsearch 2.2.0,操作系统环境版本是 CentOS ...
随机推荐
- 关于jstl.jar引用问题及解决方法
在前文SSM说到因为从MyEclipse换成了Eclipse.有些架包自动缺失. 造成:"org.apache.jasper.JasperException: This absolute u ...
- Hadoop 核心架构
Hadoop 由许多元素构成.其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件.HDFS(对于本文)的上一层是Ma ...
- Quartz (一)
1 核心接口 1.1 Scheduler---核心调度器 1.2 Job---任务 1.3 JobDetail---任务描述 1.4 Trigger---触发器 2 触发器 Tigger(CornTr ...
- Docker- 创建支持SSH服务的容器镜像
示例 - CentOS7 [root@CentOS-7 ~]# cat ssh-centos7 FROM centos:centos7 MAINTAINER anliven "anliven ...
- poj2185 Milking Grid
题目链接:http://poj.org/problem?id=2185 这道题我看了好久,最后是通过参考kuangbin的博客才写出来的 感觉next数组的应用自己还是掌握的不够深入 这道题其实就是先 ...
- Gephi安装
Gephi for mac https://gephi.org/users/download/ 在官网上下载gephi-0.9.1-macos.dmg双击拖到Application里面就好了,注意有的 ...
- smarty中的修饰函数
smarty中的修饰函数: 对在模板文件中显示的数据变量进行二次修饰. 格式: {ts:变量|函数名:参数1:参数2:参数3...|函数名:参数1:参数2...} 常见的修饰函数: capitaliz ...
- Item 27: 明白什么时候选择重载,什么时候选择universal引用
本文翻译自<effective modern C++>,由于水平有限,故无法保证翻译完全正确,欢迎指出错误.谢谢! 博客已经迁移到这里啦 Item 26已经解释了,不管是对全局函数还是成员 ...
- Mysql 忘记root密码后修改root密码
1.修改my.cnf: 在mysqld进程配置文件中添加skip-grant-tables,添加完成后记住保存. 2.重新启动MYSQL数据库: service mysqld restart 2.修改 ...
- User-Agent详解
User-Agent : 用户代理 用户在上网的时候会作为http 请求头的一部分传递给服务端 ,用于识别用户当前环境(如浏览器类型及版本号,以及操作系统信息 ) 右键f12可以查看 下面是我的浏 ...