java.util.HashSet, java.util.LinkedHashMap, java.util.IdentityHashMap 源码阅读 (JDK 1.8)
一、java.util.HashSet
1.1 HashSet集成结构
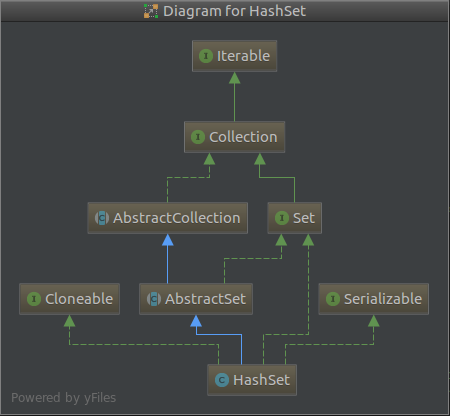
1.2 java.util.HashSet属性
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
HashSet的本质其实就是一个HashMap。Set集合一个重要的特性就是元素不重复,而HashMap本身就是符合这一特性的。
public Iterator<E> iterator() {
return map.keySet().iterator();
}
集合的迭代器就是HashMap中keySet()的迭代器。
HashSet类需要理解的不多,看懂了HashMap这个类就没什么问题了。HashMap源码解析请参考:java.util.HashMap和java.util.HashTable (JDK1.8)
二、java.util.LinkedHashMap
2.1 LinkedHashMap继承结构
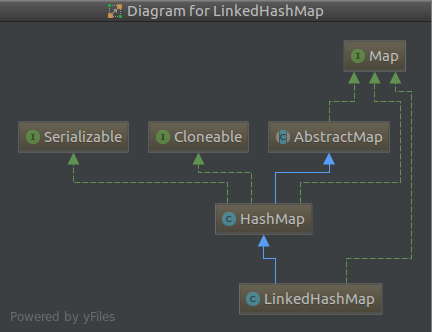
图中蓝色的为继承extend,虚线为implements
HashMap的本质是一个Node的数组,本质是个数组,数组可以根据下标去访问数组内容。HashMap的Map.Entry是无序的。
LinkedHashMap继承自HashMap,因此LinkedHashMap首先它是一个HashMap,其次它具备Node链表的属性。这个Node链表维护了Node插入顺序或者访问顺序。
2.2 LinkedHashMap属性
static class Entry<K,V> extends HashMap.Node<K,V> {
// 包含前一节点和后一节点的引用,是个双向链表
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
// 链表头节点,也是最老的节点
transient LinkedHashMap.Entry<K,V> head;
// 链表尾节点,也是最年轻的节点
transient LinkedHashMap.Entry<K,V> tail;
// 访问顺序,true为访问顺序,false为插入顺序
final boolean accessOrder;
accessOrder默认为false,如果需要设置成true,LinkedhashMap提供了如下构造函数:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
设置为false,则整个双向链表按照插入顺序进行排列;为true则按照访问顺序进行排列,当某个节点被get访问,则将该节点放置到链表最结尾(最结尾是最年轻的节点)。
访问顺序则是采用了LRU(Least recently used,最近最少使用)算法,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
2.3 LinkedHashMap方法
// 将src的相关引用全部复制给dst节点
private void transferLinks(LinkedHashMap.Entry<K,V> src,
LinkedHashMap.Entry<K,V> dst) {
// 修改节点自身的before和after引用
LinkedHashMap.Entry<K,V> b = dst.before = src.before;
LinkedHashMap.Entry<K,V> a = dst.after = src.after;
// 修改前后节点的引用
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
}
这个方法是替换节点的核心,新的节点接替旧的节点的所有引用关系,旧的节点无法被引用最终会被GC回收。
// 删除节点操作
void afterNodeRemoval(Node<K,V> e) { // unlink
// 保存当前节点及其前后节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 从链表中去除掉该节点,主要是去除对该节点的引用
// 将该节点对链表其它节点的引用也去掉
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
} void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 如果按照访问顺序,则需要将被访问节点至于链表最结尾处
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
} void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// removeEldestEntry(first) 默认返回false,如果需要可以继承LinkedHashMap,覆盖该函数。
// removeEldestEntry(first) 如果返回true,则在put的时候会删除链表头结点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
上面三个方法在HashMap中也是存在的,不过方法体为空,LinkedHashMap覆盖了该方法。在HashMap的put、get、remove方法中
LinkedHashMap并没有重新实现put、get、remove、clear方法,仍然是采用HashMap的实现方式,不同的是afterNodeRemoval、afterNodeAccess、afterNodeInsertion已经不再是空的方法体了。
在LinkedHashMap, LinkedKeySet, LinkedValueSet, LinkedEntrySet类中的forEach方法以及都是遍历链表的,因此可以按照插入顺序(或访问顺序)去遍历LinkedHashMap,从而解决了HashMap无序问题。
三、java.util.IndentifyHashMap
3.1 IndentifyHashMap继承结构
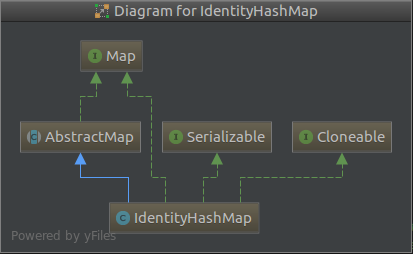
IdentityHashMap虽然冠以HashMap之名,却不是HashMap的子类,它是继承自AbstractHashMap。
IdentityHashMap比较两个key是否相等,并不是采用内容比较,而是直接进行==比较,比较两个key是否为同一个对象。
3.2 IdentityHashMap属性
transient Object[] table; // non-private to simplify nested class access
int size;
transient int modCount;
static final Object NULL_KEY = new Object();
identityHashMap是一个Object数组,size表示当前Map存入的数据总数,modCount表示修改次数。
IdentityHashMap允许使用NULL作为key,如下代码所示,如果key为null,则存入预先定义的NULL_KEY对象。
private static Object maskNull(Object key) {
return (key == null ? NULL_KEY : key);
}
static final Object unmaskNull(Object key) {
return (key == NULL_KEY ? null : key);
}
3.3 IdentityHashMap方法
private static int nextKeyIndex(int i, int len) {
return (i + 2 < len ? i + 2 : 0);
}
这个方法在IdentityHashMap中频繁用到,作用是寻找下一个index以解决hash碰撞问题,下一个index获取也是按照非常简单的(i+2 < len ? i+2 : 0)。
HashMap采用链表和红黑树避免hash碰撞问题,而在IdentityHashMap中则是采用开放定址法,而且采用的是最简单的线性探测法。
我们先来看下最hash算法
private static int hash(Object x, int length) {
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
}
无论x对象所属的类是否重新实现了hashCode()方法,System.identityHashCode(x) 都将返回默认的hashCode()结果,所谓默认的hashCode()就是指Object类中的hashCode()方法。Object类中的hashCode()可以为不同的对象返回不同的结果,根据Java doc中的描述,这是根据对象的内存地址来计算hash结果的。System.identityHashCode(x) 在x为null时返回0。
hash方法在通过System.identityHashCode方法获得hash code之后,再通过移位和与运算计算index。因为采用System.identityHashCode方法获取hash code,因此不同的对象hash code是不同的。
public V put(K key, V value) {
final Object k = maskNull(key);
retryAfterResize: for (;;) {
final Object[] tab = table;
final int len = tab.length;
// 计算下标
int i = hash(k, len);
// 遍历所有可能的位置,直到找到一个空位
for (Object item; (item = tab[i]) != null;
i = nextKeyIndex(i, len)) {
// 待插入的key已经存在,替换value
if (item == k) {
@SuppressWarnings("unchecked")
V oldValue = (V) tab[i + 1];
tab[i + 1] = value;
return oldValue;
}
}
// 新加一个节点如果size > len/3则需要扩容
final int s = size + 1;
// Use optimized form of 3 * s.
// Next capacity is len, 2 * current capacity.
if (s + (s << 1) > len && resize(len))
// 扩容后待插入的节点需要重新查找位置
continue retryAfterResize;
// 修改次数加一
modCount++;
// 在下标i存放key,在i+1下标存放value
tab[i] = k;
tab[i + 1] = value;
size = s;
return null;
}
}
在put方法中,判断两个key是否相等,是直接使用“==”的,也就是说不同对象就会被当做不同的key处理。
其次在存放的时候i存放key,i+1存放value,这也就能解释查找下一个空位方法nextKeyIndex中使用i+2的原因了。
从put方法中还能看出扩容条件为size > len/3,也就是说IdentityHashMap最多只能使用总capacity的1/3。相对于HashMap默认的loadFactor=0.75,IdentityHashMap的使用率还是非常低的。
接下来看下resize方法
private boolean resize(int newCapacity) {
// assert (newCapacity & -newCapacity) == newCapacity; // power of 2
// 直接扩容为之前的2倍
int newLength = newCapacity * 2;
Object[] oldTable = table;
int oldLength = oldTable.length;
if (oldLength == 2 * MAXIMUM_CAPACITY) { // can't expand any further
if (size == MAXIMUM_CAPACITY - 1)
throw new IllegalStateException("Capacity exhausted.");
return false;
}
if (oldLength >= newLength)
return false;
// 重新new一个新的数组出来,简单粗暴!
Object[] newTable = new Object[newLength];
for (int j = 0; j < oldLength; j += 2) {
Object key = oldTable[j];
if (key != null) {
Object value = oldTable[j+1];
// 将原数组上的key value清空,不清空将会导致内存无法被释放
oldTable[j] = null;
oldTable[j+1] = null;
// key重新hash
int i = hash(key, newLength);
while (newTable[i] != null)
// hash冲突了就查找下一个位置
i = nextKeyIndex(i, newLength);
newTable[i] = key;
newTable[i + 1] = value;
}
}
table = newTable;
return true;
}
resize方法真的是简单粗暴,直接double capacity,然后将旧的table中的数据hash到新的table中。
public V get(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
// 根据key计算下标
int i = hash(k, len);
while (true) {
Object item = tab[i];
if (item == k)
return (V) tab[i + 1];
if (item == null)
return null;
// 查找下一个位置
i = nextKeyIndex(i, len);
}
}
get方法和containsKey方法方法体相同,其实现思路也就是遍历数组,如果插到一个空位置,则说明不存在该key。
public V remove(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true) {
Object item = tab[i];
// 查找到该key
if (item == k) {
modCount++;
size--;
@SuppressWarnings("unchecked")
V oldValue = (V) tab[i + 1];
// 相应位置置空
tab[i + 1] = null;
tab[i] = null;
// 直接置空会导致查找出现问题
closeDeletion(i);
return oldValue;
}
// 没有找到该key
if (item == null)
return null;
i = nextKeyIndex(i, len);
}
}
因为IdentityHashMap是以开放定址法解决hash冲突的,直接将数组某个地方设置为null,势必会导致查找出问题。为此需要调用closeDeletion方法来解决这一问题。
private void closeDeletion(int d) {
// Adapted from Knuth Section 6.4 Algorithm R
Object[] tab = table;
int len = tab.length;
Object item;
for (int i = nextKeyIndex(d, len); (item = tab[i]) != null;
i = nextKeyIndex(i, len) ) {
int r = hash(item, len);
// 将后面的因为hash碰撞而存放的元素往前移
if ((i < r && (r <= d || d <= i)) || (r <= d && d <= i)) {
// 将后面的元素往前移位
tab[d] = item;
tab[d + 1] = tab[i + 1];
tab[i] = null;
tab[i + 1] = null;
d = i;
}
}
}
closeDeletion方法其思路就是对空置出来的位置d后面的元素进行hash判断,如果之前是因为hash碰撞存放在d后面的,则直接往前移,将这个空置的d位置给覆盖掉。在这个过程中要注意table数组是个环形的。
整体感觉IdentityHashMap实现非常的简单粗暴,优化较少,可能是因为使用较少的原因。
java.util.HashSet, java.util.LinkedHashMap, java.util.IdentityHashMap 源码阅读 (JDK 1.8)的更多相关文章
- java.util.HashSet, java.util.LinkedHashMap, java.util.IdentityHashMap 源码阅读 (JDK 1.8.0_111)
一.java.util.HashSet 1.1 HashSet集成结构 1.2 java.util.HashSet属性 private transient HashMap<E,Object> ...
- 《java.util.concurrent 包源码阅读》 结束语
<java.util.concurrent 包源码阅读>系列文章已经全部写完了.开始的几篇文章是根据自己的读书笔记整理出来的(当时只阅读了部分的源代码),后面的大部分都是一边读源代码,一边 ...
- 《java.util.concurrent 包源码阅读》13 线程池系列之ThreadPoolExecutor 第三部分
这一部分来说说线程池如何进行状态控制,即线程池的开启和关闭. 先来说说线程池的开启,这部分来看ThreadPoolExecutor构造方法: public ThreadPoolExecutor(int ...
- JDK源码阅读(1)_简介+ java.io
1.简介 针对这一个版块,主要做一个java8的源码阅读笔记.会对一些在javaWeb中应用比较广泛的java包进行精读,附上注释.对于容易混淆的知识点给出相应的对比分析. 精读的源码顺序主要如下: ...
- Java源码阅读顺序
阅读顺序参考链接:https://blog.csdn.net/qq_21033663/article/details/79571506 阅读源码:JDK 8 计划阅读的package: 1.java. ...
- Java源码阅读Stack
Stack(栈)实现了一个后进先出(LIFO)的数据结构.该类继承了Vector类,是通过调用父类Vector的方法实现基本操作的. Stack共有以下五个操作: put:将元素压入栈顶. pop:弹 ...
- 【JDK1.8】Java 8源码阅读汇总
一.前言 万丈高楼平地起,相信要想学好java,仅仅掌握基础的语法是远远不够的,从今天起,笔者将和园友们一起阅读jdk1.8的源码,并将阅读重点放在常见的诸如collection集合以及concu ...
- Java集合源码阅读之HashMap
基于jdk1.8的HashMap源码分析. 引用于:http://blog.stormma.me/2017/05/31/Java%E9%9B%86%E5%90%88%E6%BA%90%E7%A0%81 ...
- Java中的容器(集合)之HashMap源码解析
1.HashMap源码解析(JDK8) 基础原理: 对比上一篇<Java中的容器(集合)之ArrayList源码解析>而言,本篇只解析HashMap常用的核心方法的源码. HashMap是 ...
随机推荐
- Ionic3 组件懒加载
使用懒加载能够减少程序启动时间,减少打包后的体积,而且可以很方便的使用路由的功能. 使用懒加载: 右侧红色区域可以省略掉(引用.声明也删掉) 若使用ionic命令新建page,则无需进行下面的操作,否 ...
- C++ 设计模式 开放封闭原则 简单示例
C++ 设计模式 开放封闭原则 简单示例 开放封闭原则(Open Closed Principle)描述 符合开放封闭原则的模块都有两个主要特性: 1. 它们 "面向扩展开放(Open Fo ...
- 349B - Color the Fence
Color the Fence Time Limit:2000MS Memory Limit:262144KB 64bit IO Format:%I64d & %I64u Su ...
- Linux学习(十七)压缩与打包
一.关于打包和压缩 打包和压缩的最大意义在于减少文件传输中需要的流量.打包的方式大概有tar命令,zip命令.压缩的方式有gzip,bzip2,xz.tar命令可以通过参数将压缩和打包在一起执行. 二 ...
- 项目实战1—LNMP的搭建、nginx反向代理和缓存等的实现
实战一:搭建lnmp及类小米等商业网站的实现 环境:关闭防火墙,selinux 1.安装包,开启服务 yum -y install nginx mariadb-server php-fpm php-m ...
- NoSQL:redis缓存数据库
一 Redis介绍 Redis和Memcached类似,也属于key-value nosql 数据库 Redis官网redis.io, 当前最新稳定版4.0.1 和Memcached类似,它支持存储的 ...
- mysql 运维常见操作
初始安装并赋予密码: [root@Alinx html]# yum install -y mysql mysql-server #安装mysql可与 ...
- js中的break,continue和return到底怎么用?
为什么要说个?好像很简单,但是我也会迷糊,不懂有时候为什么要用return,然而break和continue也经常和他放在一起. 所以就一起来说一说,这三个看起来很简单,却常常会出错的关键词的具体用法 ...
- 【分享】纯jQuery实现星巴克官网导航栏效果
前言 大冬天的没得玩,只能和代码玩. 所以就无聊研究了一下星巴克官网,在我看来应该是基本还原吧~ 请各位大神指教! 官网效果图 要写的就是最上方的会闪现的白色条条 效果分析 1.在滚动条往下拉到一定距 ...
- 启用 Brotli 压缩算法,对比 Gzip 压缩 CDN 流量再减少 20%
Google 认为互联网用户的时间是宝贵的,他们的时间不应该消耗在漫长的网页加载中,因此在 2015 年 9 月 Google 推出了无损压缩算法 Brotli.Brotli 通过变种的 LZ77 算 ...