Postgres的tuple的组装
1.相关的数据类型
我们先看相关的数据类型:
HeapTupleData(src/include/access/htup.h)
typedef struct HeapTupleData
{
uint32 t_len; /* length of *t_data */
ItemPointerData t_self; /* SelfItemPointer */
Oid t_tableOid; /* table the tuple came from */
HeapTupleHeader t_data; /* -> tuple header and data */
} HeapTupleData;
HeapTupleHeaderData(src/include/access/htup_details.h)
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
t_choice具有2个成员的联合类型:
1.t_heap 用于记录对元组执行插入/删除操作事物ID和命令ID,这些信息主要用于并发控制是检查元组对事物的可见性
2.t_datum一个新的元组在内存中形成的时候,我们不关心事物的可见性,因此在t_choice中需要用DatumTupleFields结构来记录元组的长度等信息,把内存的数据写入到表文件的时候,需要在元组中记录事物和命令ID,因此会把t_choice所占的内存转换成HeapTupleFields结构并且填充响应数据后再进行元组的插入。
t_ctid用于记录当前元组或者新元组的物理位置,块号和块内偏移量,例如(0,1)第一个块内的第一个linp,若tuple被跟新,那么就记录新版本的物理位置。
t_infomask2使用其低11位标识当前tuple的attribute的个数,其他位用于HOT以及tuple可见性的标志位
t_infomask用于标识tuple当前的状态,比如是否有OID,是否空的字段,t_infomask每一位代表一种状态,总共16种。
2.Tuple的构造
构造tuple的函数(src/backend/access/common/heaptuple.c)
HeapTuple
heap_form_tuple(TupleDesc tupleDescriptor,
Datum *values,
bool *isnull)
该函数使用给定的values数组和isnull数组来组装生成一个tuple。
该函数的主要流程是先计算整个tuple所需要的长度(这个长度是指tuple中除掉HeapTupleData结构以外的长度。事实上,该长度存储在HeapTupleData的t_len的属性中。)然后以此申请内存,最后根据values和isnull来填充tuple数据。
我们稍微说一下这个t_len的计算。
len = offsetof(HeapTupleHeaderData, t_bits);
首先计算heaptupleheaderdata的长度,这个offsetof计算了从HeapTupleHeaderData的首址到它的成员变量t_bit的偏移量。
所以为什么不直接sizeof(HeapTupleHeaderData)呢?
原因是t_bits描述了NULL的bitmap关系,它的实际长度与列(属性)个数有关,是一个可变的值,
因此,在计算完HeapTupleHeaderData长度的时候,我们便根据是否存在着null列,来计算相应的数据(如下)。
if (hasnull)
len += BITMAPLEN(numberOfAttributes);
以及是否有oid:
if (tupleDescriptor->tdhasoid)
len += sizeof(Oid);
再加上padding大小(涉及到C语言的数据对齐):
hoff = len = MAXALIGN(len); /* align user data safely */
最后再获取data的长度:
data_len = heap_compute_data_size(tupleDescriptor, values, isnull);
len += data_len;
获取了tuple的长度申请好内存后,向里面添加数据,就获得了如下的tuple(结构):
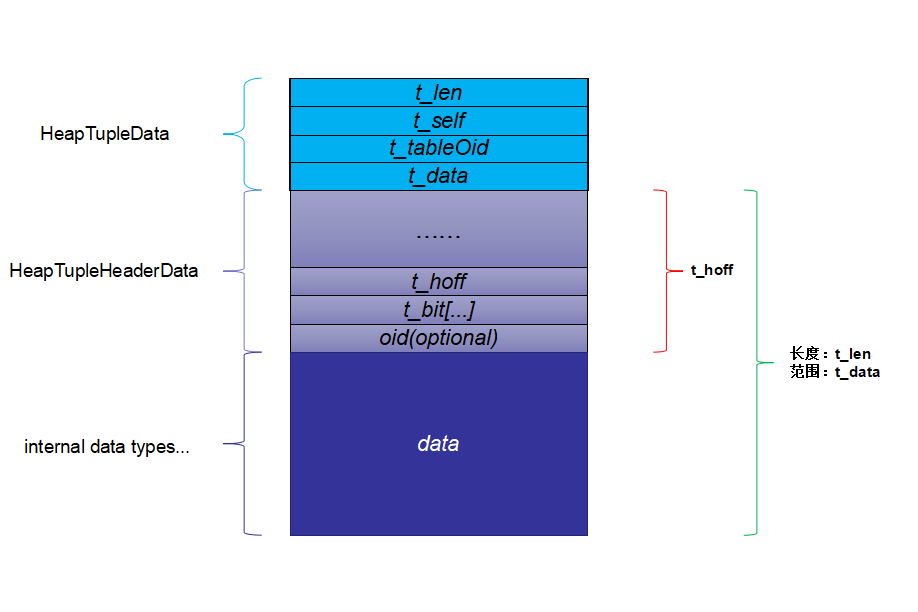
其中,hoff中包括了: 从TupleHeaderData起始位置到t_bits的位置;用户数据是从t_hoff开始,加上t_bits的偏移,以及oid的偏移,开始真正存储的。 这些由上图可以得知。
heap_fill_tuple 函数中依据tupledesc中atts所提供的信息来保存数据到相应的位置。att[i]->attlen == -1 当为此种情况时候,表明其是varlen数据,例如varchar之类的数量类型,att[i]->attlen == -2 当为此种情况时候,为cstring,即字符串形式的数据。never needs alignment 无需进行对齐操作。否则,为固定长度的类型。
如果是varlen类型数据时候。还需要使用VARATT_IS_EXTERNAL来判定是否是存储在外存上面。
做好了一条tuple之后,我们还要把它插入到数据库对应的表中才算完事。
3.Tuple的插入
插入tuple到heap的函数
Oid
heap_insert(Relation relation, HeapTuple tup, CommandId cid,
int options, BulkInsertState bistate)
这个函数还挺复杂的,涉及到了内存和disk的数据交换。内存主要涉及到了缓冲区buffer和lock,对于disk涉及到了FSM映射表和Page。
首先,预处理函数设置元组头部的字段,分配一个OID,并在必要时为元组提供Toast。请注意,在这里heaptup是传进来的tuple,而变量tup是作为一个临时变量存在的。
heaptup = heap_prepare_insert(relation, tup, xid, cid, options);
我们要将元组插入到page,涉及到内存和disk的数据交换,这就要用到buffer。我们知道insert的本质也是先"select"再"insert"。也就是说我们先要找到该表上合适的Page来装这个tuple。因此,我们为该Page申请一个buffer并加上执行锁,将该Page载入申请到的buffer中。注意,此时要插入的tuple并未写到buffer中。
buffer = RelationGetBufferForTuple(relation, heaptup->t_len,
InvalidBuffer, options, bistate,
&vmbuffer, NULL);
这样以后,所有的准备工作都做好了,就差临门一脚了。成与不成就在一举了。是不是听起来有点。。。?
是的,我们要进入临界区了,谁都不要打扰我:
START_CRIT_SECTION();
这个语句其实是设置了全局变量CritSectionCount,就相当于信号量了,这里不多说。
然后我们开始写数据吧:
RelationPutHeapTuple(relation, buffer, heaptup,
(options & HEAP_INSERT_SPECULATIVE) != 0);
但是话说,真的写了?并没有!你忘了我们postgresql有WAL么?你WAL log都还没写,数据怎么能先到磁盘?
那么这里我们有什么?我们buffer里面有Page,我们"手上"有tuple,好的,我们把tuple放到这个buffer装的Page里面对应的位置上。
就是说,我们的数据还在buffer里。
那么怎么通知Postgres我有脏数据要写啊?
MarkBufferDirty(buffer);
设置buffer为脏,这样Postgres在下次写磁盘(checkpointer)的时候就知道把这个buffer里的数据丢回disk了。
那么,我们也就知道了,接下来我们就要开始准备WAL和数据了。
这里大致用到了这几个函数:
XLogBeginInsert
XLogRegisterData
XLogRegisterBuffer
XLogRegisterBufData
PageSetLSN
好的,WAL也设置好了。(只等插入这条tuple的命令commit之后,WAL数据立即落盘,写到disk上,也就是pg_xlog目录下的WAL段里面。)此时退出临界区。
这个时候要放开buffer了。
最后我们再做一做清理工作,打完收工。
最最最后,实际的元组仍然在内存,不过没事,因为你的查询也是要先走buffer和cache的,所以你已经可以查询到这条数据了。等到系统调用了checkpointer进程,你的数据才真正落了盘,然而,这对你是透明的。
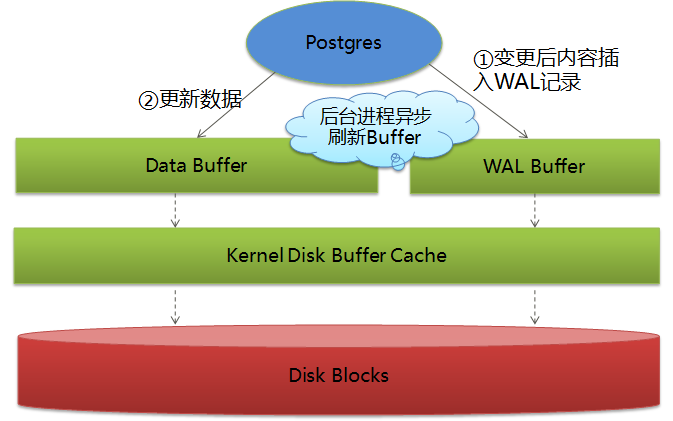
这里关于数据落盘的先后顺序和时机,我还是借网上的两张图吧:
WAL和data进入buffer的时机:
WAL和data写到disk的时机:
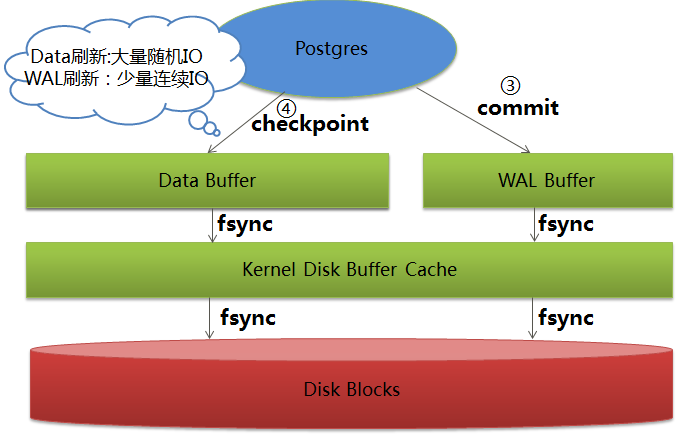
好的就是这样~
恩,这次对WAL的插入的分析比较简略,下次我弄清楚了再细说吧各位。
参考文章:
http://blog.jobbole.com/106585/
http://www.cnblogs.com/sangli/p/6404771.html
http://www.jianshu.com/p/a37ceed648a8
Postgres的tuple的组装的更多相关文章
- Postgres中tuple的组装与插入
1.相关的数据类型 我们先看相关的数据类型: HeapTupleData(src/include/access/htup.h) typedef struct HeapTupleData { uint3 ...
- Python~函数的参数
def func(a,b,c,*args,**kw): print('a=',a,'b=',b,'c=',c,'args=',args,'kw=',kw) 必选参数,默认参数,可变参数,关键字参数 d ...
- Storm中关于Topology的设计
一:介绍Storm设计模型 1.Topology Storm对任务的抽象,其实 就是将实时数据分析任务 分解为 不同的阶段 点: 计算组件 Spout Bolt 边: 数据流向 数据从上 ...
- MySQL and Postgres command equivalents (mysql vs psql)
MySQL and Postgres command equivalents (mysql vs psql) 博客分类: Database From: http://blog.endpoint.c ...
- Following a Select Statement Through Postgres Internals
This is the third of a series of posts based on a presentation I did at the Barcelona Ruby Conferenc ...
- Discovering the Computer Science Behind Postgres Indexes
This is the last in a series of Postgres posts that Pat Shaughnessy wrote based on his presentation ...
- Tuple
Tuple(组元)是C# 4.0引入的一个新特性,编写的时候需要基于.NET Framework 4.0或者更高版本. 在以前编程中,当需要返回多个值得方法中,常常需要将这些值放置到一个结构体或者对象 ...
- 再说Postgres中的高速缓存(cache)
表的模式信息存放在系统表中,因此要访问表,就需要首先在系统表中取得表的模式信息.对于一个PostgreSQL系统来说,对于系统表和普通表模式的访问是非常频繁的.为了提高这些访问的效率,PostgreS ...
- Postgres中的物化节点之sort节点
顾名思义,物化节点是一类可缓存元组的节点.在执行过程中,很多扩展的物理操作符需要首先获取所有的元组后才能进行操作(例如聚集函数操作.没有索引辅助的排序等),这时要用物化节点将元组缓存起来.下面列出了P ...
随机推荐
- 老大哥在看着你!我国部署超2000万个AI监控系统
原文:Big brother is watching you! China installs 'the world's most advanced video surveillance system' ...
- thinkphp项目在apache服务器中“去掉”index.php后出现找不到url的问题
今天将MAC中apache环境下的thinkphp项目移植到windows中得apache环境下.原本都是apache环境,而且配置都一样,死活给我这样的提示: Not Found The reque ...
- HDU4027 Can you answer these queries?(线段树 单点修改)
A lot of battleships of evil are arranged in a line before the battle. Our commander decides to use ...
- 1016: [JSOI2008]最小生成树计数
1016: [JSOI2008]最小生成树计数 Time Limit: 1 Sec Memory Limit: 162 MBSubmit: 6200 Solved: 2518[Submit][St ...
- escape、unescape、encodeURIComponent、decodeURLComponent
项目中遇到的问题,当我设置一个标签的属性,这个属性值含有js内容,这样就会被执行产生安全问题 解决办法:,可以将后端给的内容先encodeURIComponent,获取的时候再decodeURICom ...
- 隐藏input的光标
https://segmentfault.com/q/1010000000684888 https://wap.didialift.com/beatles/campaign/driver/activi ...
- html 自定义标签使用实现方法
通过指定html命名空间的名字来定义自定义标签:默认的一些标签p div等都在html默认的命名空间下.而自定义的标签可以放在自定义的命名空间下,可通过xmlns:命名空间名 来指定,而自定义标签需要 ...
- absolute元素 text-align属性
text-align属性的元素可以有效作用于inline/inline-block水平的子元素,但是,text-align属性对应用了position:absloute/fixed声明的元素无效! ...
- javaSE基础
变量 1.变量就是数据存储空间的表示. 2.标识符命名规则:变量名=首字母+其余部分 ①首字母:字母.下划线.“$”符号(开头) ②其余部分:数字.字母.下划线“$” ③应避开关键字:int int ...
- PHP面向对象摘要
一.面向对象的三种特性,分别是封装性,继承性和多态性. 1.封装性:封装是面向对象的核心思想,将对象的属性和行为封装起来,不需要让外界知道具体的实现细节,这就是封装思想. 2.继承性:继承性主要是描述 ...