cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning 听课笔记
1. 深度学习面临的问题:
1)模型越来越大,很难在移动端部署,也很难网络更新。
2)训练时间越来越长,限制了研究人员的产量。
3)耗能太多,硬件成本昂贵。
解决的方法:联合设计算法和硬件。
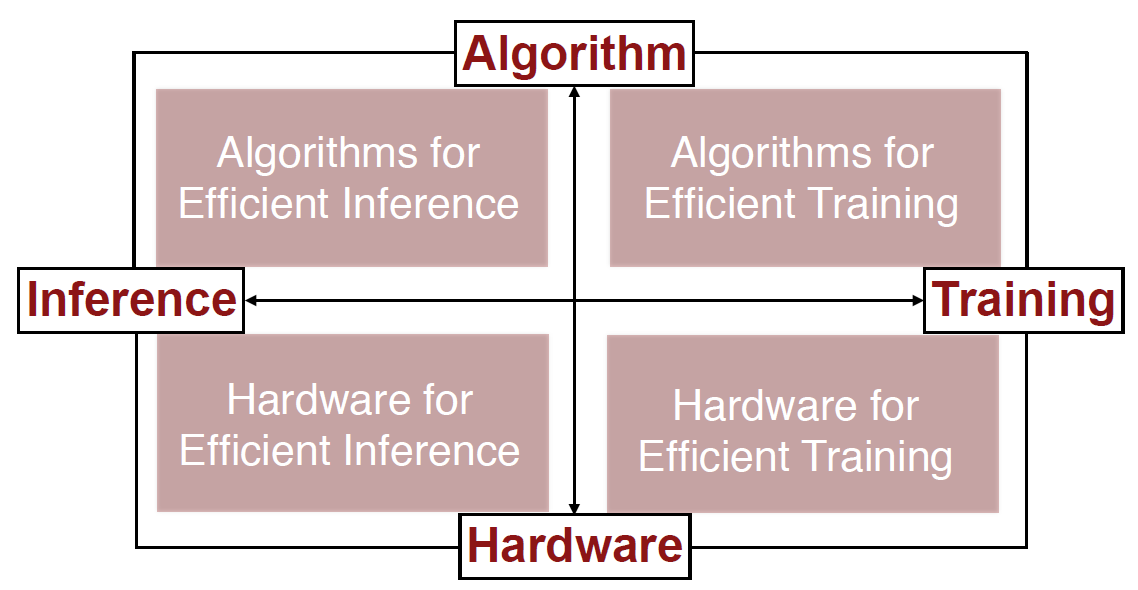
计算硬件可以分为通用和专用两大类。通用硬件又可以分为CPU和GPU。专用硬件可以分为(FPGA和ASIC,ASIC更高效,谷歌的TPU就是ASIC)。
2. Algorithms for Efficient Inference
1)Pruning,修剪掉不那么重要的神经元和连接。第一步,用原始的网络训练;第二步,修剪掉一部分网络;第三步,继续训练剩下的网络。不断重复第二步和第三步。在不损失精度的情况下,网络可以缩小到原来的十分之一(继续缩小精度会变差)。
2)Weight Sharing,权重并不需要那么精确,可以把一些近似的权重看成一样的(比如2.09、2.12、1.92、1.87可以全部看成2)。也是在原始训练基础上,用某种方式简化权重,然后不断训练调整简化权重的方式。在不损失精度的情况下,网络可以缩小到原来的八分之一。
前两种方法可以结合使用,网络可以缩小到原来的百分之几。有个名字Deep Compression。
3)Quantization,数据类型。TPU的设计主要就是优化这一部分。
4)Low Rank Approximation,把大网络拆成一系列小网络。
5)Binary(二元)/Ternary(三元) Net,很疯狂地把权重离散化成(-1,0,1)三种。
6)Winograd Transformation,一种更高效的求卷积的做法。
3. Hardware for Efficient Inference
这个方向各种硬件的共同目的是减少内存的读取(minimize memory access)。硬件需要能用压缩过的神经网络做预测。
EIE(Efficient Inference Engine)(Han et al. ISCA 2016):稀疏权重(扔掉为0的权重)、稀疏激活值(扔掉为0的激活值)、Weight Sharing(4-bit)。
4. Algorithms for Efficient Training
1)Parallelization。CPU按照摩尔定律发展,这些年单线程的性能已经提高的非常缓慢,而核的数量在不断提高。

2)Mixed Precision with FP16 and FP32,正常是用32位计算,但计算权重更新的时候用16位。
3)Model Distillation,用训练的很好的大网络的“软结果”(soft targets)作为标签提供给压缩过的小网络训练。这是Hinton的一篇论文提出的,里面解释了为什么软结果比ground truth更好。
4)DSD(Dense-Sparse-Dense Training),先对原始的稠密的网络做Pruning,训练稀疏的网络后,再Re-Dense出稠密的网络。Han说这是先学习树的枝干,再学习叶子。相比原来的稠密网络,Re-Dense出的精度更高。
5. Hardware for Efficient Training
Computation和Memory bandwidth是影响整体性能的两个因素。
Han对比Nvidia Pascal和Volta,猛吹了一波Volta。。。Volta有120个Tensor Core,非常擅长矩阵运算。
cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning 听课笔记的更多相关文章
- cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning
讲课嘉宾是Song Han,个人主页 Stanford:https://stanford.edu/~songhan/:MIT:https://mtlsites.mit.edu/songhan/. 1. ...
- 韩松毕业论文笔记-第六章-EFFICIENT METHODS AND HARDWARE FOR DEEP LEARNING
难得跟了一次热点,从看到论文到现在已经过了快三周了,又安排了其他方向,觉得再不写又像之前读过的N多篇一样被遗忘在角落,还是先写吧,虽然有些地方还没琢磨透,但是paper总是这样吧,毕竟没有亲手实现一下 ...
- cs231n spring 2017 lecture9 CNN Architectures 听课笔记
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture9 CNN Architectures
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture7 Training Neural Networks II 听课笔记
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture7 Training Neural Networks II
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture13 Generative Models 听课笔记
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
- cs231n spring 2017 lecture11 Detection and Segmentation 听课笔记
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种"Unpooling"." ...
- cs231n spring 2017 Python/Numpy基础 (1)
本文使根据CS231n的讲义整理而成(http://cs231n.github.io/python-numpy-tutorial/),以下内容基于Python3. 1. 基本数据类型:可以用 prin ...
随机推荐
- 对Java中堆栈的解析
Java把内存分为两种:一种是栈内存,一种是堆内存 栈内存:在函数中定义的一些基本类型的变量和对象的引用变量,当超过变量的作用域之后,Java自动释放该变量内存 堆内存:存放new创建的对象和数组,由 ...
- C++11 新知识点
翻了下新版的C++ Primer,新的C++ 11真是变化很大,新增了很多语法特性.虽然已经很久没在写C++了,但一直对这门经典语言很感兴趣的,大致看了看前几章基础部分,总结下新特性备个忘吧.估计也很 ...
- Intellij IDEA 像eclipse那样给maven添加依赖
打开pom.xml,在它里面使用快捷键:ALT+Insert ---->点击dependency 再输入想要添加的依赖关键字,比如:输个spring 出现下图: 根据需求选择版本,完成以后 ...
- 干货分享!关于APP导航菜单设计你应该了解的一切
导航菜单是人机交互的最主要的桥梁和平台,主要作用是不让用户迷失方向.现在市面上产品的菜单栏种类繁多,到底什么样的才是优秀的导航菜单设计呢?好的菜单设计不仅能提升整个产品的用户体验,而且还能让用户耳目一 ...
- phpexcel用法(转)
.php导出excel(多种方法) (2013-03-23 15:44:02) 转载▼ 分类: php 基本上导出的文件分为两种: 1:类Excel格式,这个其实不是传统意义上的Excel文件,只 ...
- Hello TensorFlow 三 (Golang)
在一台ubuntu 16.04.2虚拟机上为golang安装TensorFlow. 官方参考:https://www.tensorflow.org/install/install_go 首先安装go ...
- linux mysql添加、删除用户、用户权限及mysql最大字段数量
1. 登录: mysql -u username -p 显示全部的数据库: show databases; 使用某一个数据库: use databasename; 显示一个数据库的全部表: show ...
- shiro Filter--拦截器
一 shiro自带的filter:下面主要叙述顺序是 NameableFilter->OncePerRequestFilter->AdviceFilter->PathMatching ...
- 8、公司的上市问题 - CEO之公司管理经验谈
在公司发展到一定阶段之后,CEO就能够考虑公司上市的问题了.一条线路,就是先成立公司,进行投资,然后上市赚取利润,根据不同公司的总经理的想法不同而定.这条路是现在很多公司领导要求的做法.因为,通过发行 ...
- C# DataTable抽取Distinct数据(不重复数据)
http://blog.csdn.net/jyh_jack/article/details/17959821 DataTable dataTable; DataView dataView = data ...