HDFS Java API的使用举例
HDFS是Hadoop应用程序使用的主要分布式存储。HDFS集群主要由管理文件系统元数据的NameNode和存储实际数据的DataNodes组成,HDFS架构图描述了NameNode,DataNode和客户端之间的基本交互。客户端联系NameNode进行文件元数据或文件修改,并直接使用DataNodes执行实际的文件I / O。
Hadoop支持shell命令直接与HDFS进行交互,同时也支持JAVA API对HDFS的操作,例如,文件的创建、删除、上传、下载、重命名等。
HDFS中的文件操作主要涉及以下几个类:
Configuration:提供对配置参数的访问
FileSystem:文件系统对象
Path:在FileSystem中命名文件或目录。 路径字符串使用斜杠作为目录分隔符。 如果以斜线开始,路径字符串是绝对的
FSDataInputStream和FSDataOutputStream:这两个类分别是HDFS中的输入和输出流
下面是JAVA API对HDFS的操作过程:
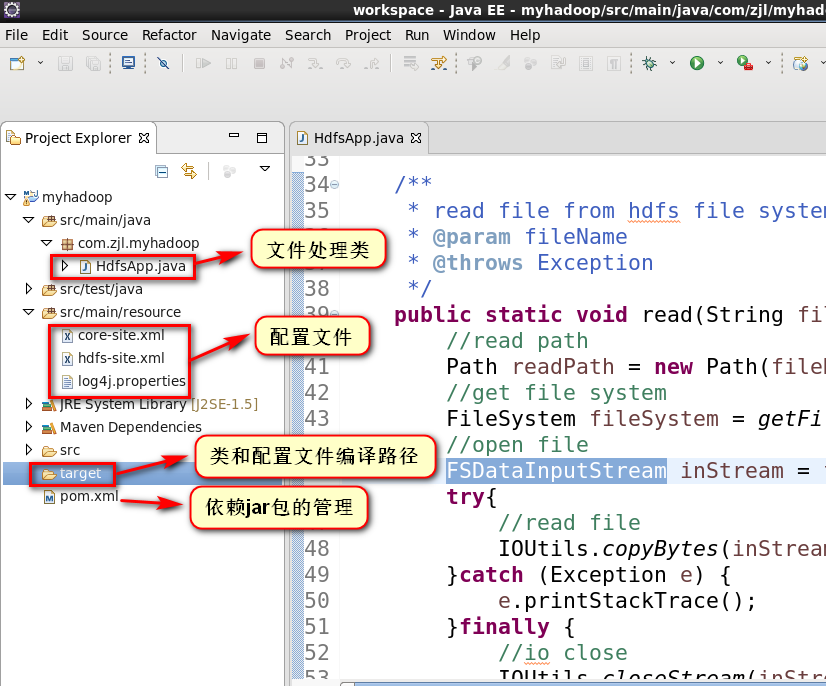
1.项目结构
2.pom.xml配置
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.zjl</groupId>
<artifactId>myhadoop</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>myhadoop</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.5.0</hadoop.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
</dependency>
</dependencies>
</project>
3.拷贝hadoop安装目录下与HDFS相关的配置(core-site.xml,hdfs-site.xml,log4j.properties)到resource目录下
[hadoop@hadoop01 ~]$ cd /opt/modules/hadoop-2.6./etc/hadoop/
[hadoop@hadoop01 hadoop]$ cp core-site.xml hdfs-site.xml log4j.properties /opt/tools/workspace/myhadoop/src/main/resource/
[hadoop@hadoop01 hadoop]$
(1)core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>fs.defaultFS</name>
<!-- 如果没有配置,默认会从本地文件系统读取数据 -->
<value>hdfs://hadoop01.zjl.com:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中 -->
<value>/opt/modules/hadoop-2.6.5/data/tmp</value>
</property>
</configuration>
(2)hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<!-- default value 3 -->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(3)采用默认即可,打印hadoop的日志信息所需的配置文件。如果不配置,运行程序时eclipse控制台会提示警告
4.启动hadoop的hdfs的守护进程,并在hdfs文件系统中创建文件(文件共步骤5中java程序读取)
[hadoop@hadoop01 hadoop]$ cd /opt/modules/hadoop-2.6./
[hadoop@hadoop01 hadoop-2.6.]$ sbin/start-dfs.sh
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hadoop01.zjl.com]
hadoop01.zjl.com: starting namenode, logging to /opt/modules/hadoop-2.6./logs/hadoop-hadoop-namenode-hadoop01.zjl.com.out
hadoop01.zjl.com: starting datanode, logging to /opt/modules/hadoop-2.6./logs/hadoop-hadoop-datanode-hadoop01.zjl.com.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/modules/hadoop-2.6./logs/hadoop-hadoop-secondarynamenode-hadoop01.zjl.com.out
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop01 hadoop-2.6.]$ jps
NameNode
Jps
SecondaryNameNode
DataNode
org.eclipse.equinox.launcher_1.3.201.v20161025-.jar
[hadoop@hadoop01 hadoop-2.6.]$ bin/hdfs dfs -mkdir -p /user/hadoop/mapreduce/wordcount/input
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop01 hadoop-2.6.]$ cat wcinput/wc.input
hadoop yarn
hadoop mapreduce
hadoop hdfs
yarn nodemanager
hadoop resourcemanager
[hadoop@hadoop01 hadoop-2.6.]$ bin/hdfs dfs -put wcinput/wc.input /user/hadoop/mapreduce/wordcount/input/
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop01 hadoop-2.6.]$
5.java代码
package com.zjl.myhadoop; import java.io.File;
import java.io.FileInputStream; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils; /**
*
* @author hadoop
*
*/
public class HdfsApp { /**
* get file system
* @return
* @throws Exception
*/
public static FileSystem getFileSystem() throws Exception{
//read configuration
//core-site.xml,core-default-site.xml,hdfs-site.xml,hdfs-default-site.xml
Configuration conf = new Configuration();
//create file system
FileSystem fileSystem = FileSystem.get(conf);
return fileSystem;
} /**
* read file from hdfs file system,output to the console
* @param fileName
* @throws Exception
*/
public static void read(String fileName) throws Exception {
//read path
Path readPath = new Path(fileName);
//get file system
FileSystem fileSystem = getFileSystem();
//open file
FSDataInputStream inStream = fileSystem.open(readPath);
try{
//read file
IOUtils.copyBytes(inStream, System.out, 4096, false);
}catch (Exception e) {
e.printStackTrace();
}finally {
//io close
IOUtils.closeStream(inStream);
}
} public static void upload(String inFileName, String outFileName) throws Exception { //file input stream,local file
FileInputStream inStream = new FileInputStream(new File(inFileName)); //get file system
FileSystem fileSystem = getFileSystem();
//write path,hdfs file system
Path writePath = new Path(outFileName); //output stream
FSDataOutputStream outStream = fileSystem.create(writePath);
try{
//write file
IOUtils.copyBytes(inStream, outStream, 4096, false);
}catch (Exception e) {
e.printStackTrace();
}finally {
//io close
IOUtils.closeStream(inStream);
IOUtils.closeStream(outStream);
}
}
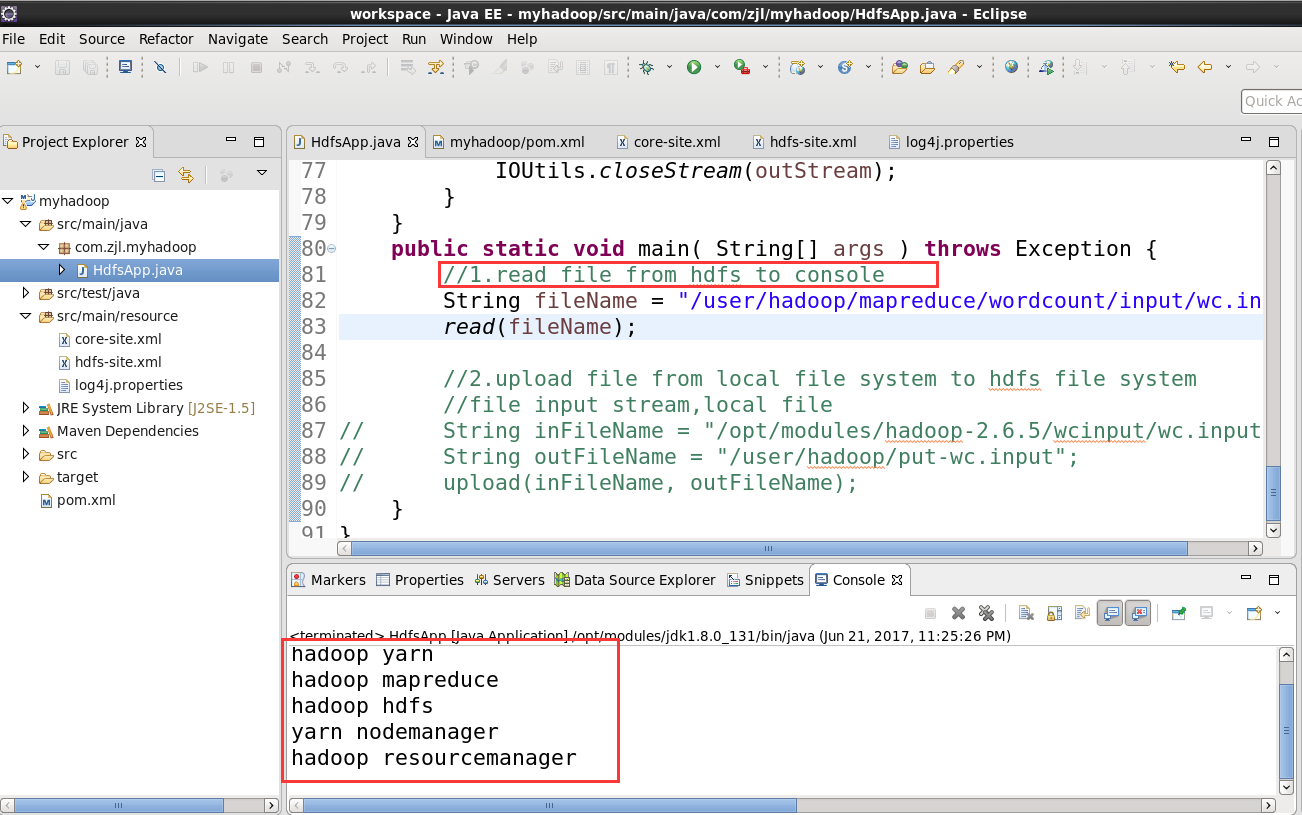
public static void main( String[] args ) throws Exception {
//1.read file from hdfs to console
// String fileName = "/user/hadoop/mapreduce/wordcount/input/wc.input";
// read(fileName); //2.upload file from local file system to hdfs file system
//file input stream,local file
String inFileName = "/opt/modules/hadoop-2.6.5/wcinput/wc.input";
String outFileName = "/user/hadoop/put-wc.input";
upload(inFileName, outFileName);
}
}
6.调用方法 read(fileName)
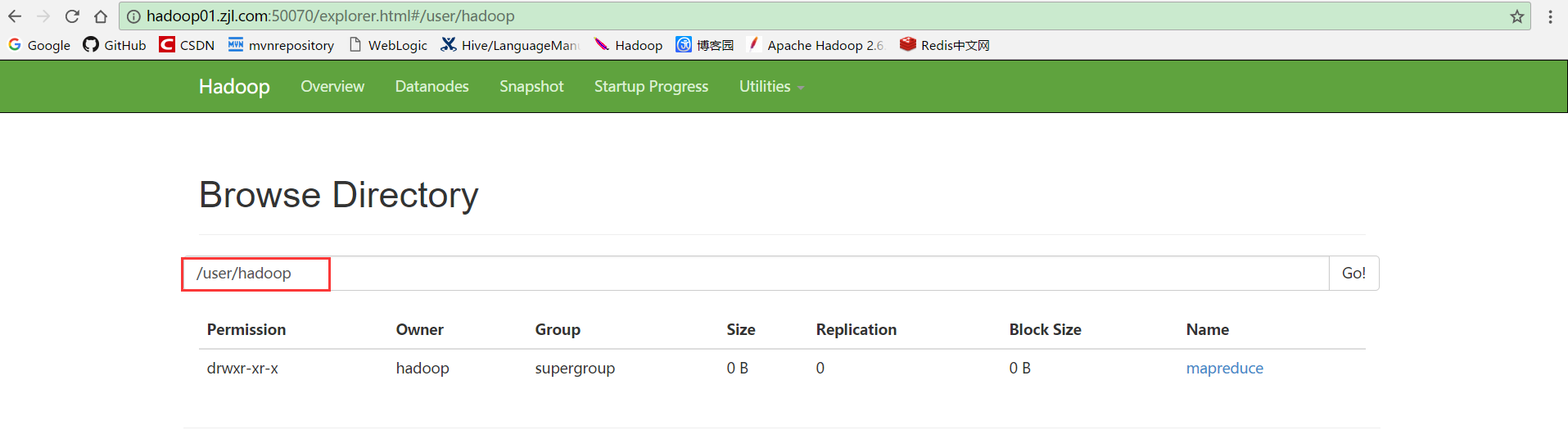
7.进入hdfs文件系统查看/user/hadoop目录
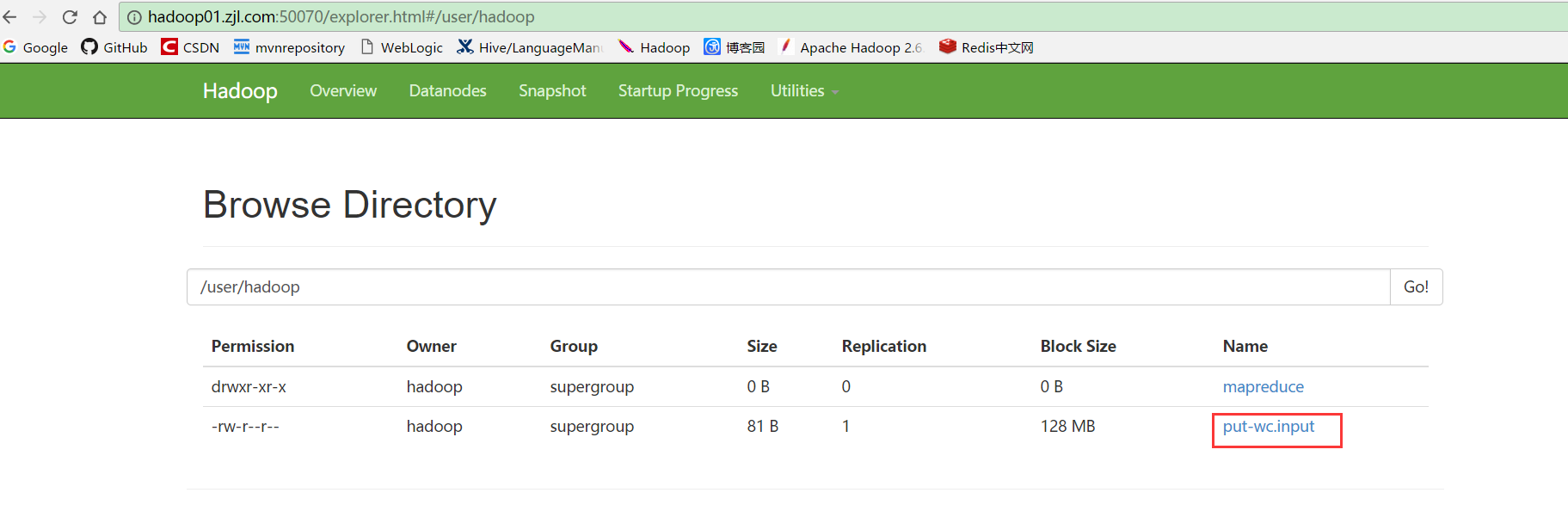
8.调用upload(inFileName, outFileName),然后刷新步骤7的页面,文件上传成功
HDFS Java API的使用举例的更多相关文章
- HDFS Java API 常用操作
package com.luogankun.hadoop.hdfs.api; import java.io.BufferedInputStream; import java.io.File; impo ...
- HDFS shell操作及HDFS Java API编程
HDFS shell操作及HDFS Java API编程 1.熟悉Hadoop文件结构. 2.进行HDFS shell操作. 3.掌握通过Hadoop Java API对HDFS操作. 4.了解Had ...
- 【Hadoop】HA 场景下访问 HDFS JAVA API Client
客户端需要指定ns名称,节点配置,ConfiguredFailoverProxyProvider等信息. 代码示例: package cn.itacst.hadoop.hdfs; import jav ...
- hadoop hdfs java api操作
package com.duking.util; import java.io.IOException; import java.util.Date; import org.apache.hadoop ...
- HDFS Java API
HDFS Java API 搭建Hadoop客户端与Java访问HDFS集群
- HDFS Java API 的基本使用
一. 简介 二.API的使用 2.1 FileSystem 2.2 创建目录 2.3 创建指定权限的目录 2.4 创建文件,并写入内容 ...
- Hadoop 学习之路(七)—— HDFS Java API
一. 简介 想要使用HDFS API,需要导入依赖hadoop-client.如果是CDH版本的Hadoop,还需要额外指明其仓库地址: <?xml version="1.0" ...
- Hadoop 系列(七)—— HDFS Java API
一. 简介 想要使用 HDFS API,需要导入依赖 hadoop-client.如果是 CDH 版本的 Hadoop,还需要额外指明其仓库地址: <?xml version="1.0 ...
- HDFS JAVA API介绍
注:在工程pom.xml 所在目录,cmd中运行 mvn package ,打包可能会有两个jar,名字较长的是包含所有依赖的重量级的jar,可以在linux中使用 java -cp 命令来跑.名字较 ...
随机推荐
- Phaser类详解
Phaser允许并发多阶段任务.Phaser类机制是在每一步结束的位置对线程进行同步,当所有的线程都完成了这一步,才允许执行下一步. 一个Phaser对象有两种状态: 活跃态(Active):当存在参 ...
- JAVA虚拟机系列文章
本系列文章主要记录自己在学习<深入理解Java虚拟机-JVM高级特性与最佳实践>的知识点总结,文章内容都是基于周志明所著书籍的总结. 1.Java内存区域与溢出 2.垃圾收集器与内存分配策 ...
- 如何优雅地运用 Chrome (Google)
已经在很多工具类文章前言中,提及使用工具的重要性:以至于在写这篇时候,大为窘迫:穷尽了脑海中那些名句箴言,目测都已然在先前文章中被引用.鉴于杳让人心底意识到工具的重要性,并且能践行之,远比介绍如何使用 ...
- call,apply和bind,其实很简单
call和apply call和aplly作用完全一样,都是在特定的上下文中调用函数,或者说改变函数内部的this指向:区别仅在于接收参数的方式不同. var dog = { name: " ...
- 15、TCP/IP协议
15.TCP/IP协议 几台孤立计算机系统组在一起形成网络,几个孤立网络连在一起形成一个网络的网络,即互连网.一个互连网就是一组通过相同协议族互连在一起的网络. 互联网的目的之一是在应用程 ...
- object-fit 解决图片指定大小被压缩问题
object-fit 解决图片指定大小被压缩问题 第一次遇到这个属性,是在给video 写 poster的时候,选取的作为poster的img的尺寸有点小,导致video播放器两边有留白.在控制台查看 ...
- 点击空白处隐藏指定dom元素(纯javascript方法)
<script type="text/javascript"> document.onclick = function (event) { event = event ...
- Git添加远程库和从远程库中获取(新手傻瓜式教学)
一. Git添加远程库 1.在本地新建一个文件夹,在该文件夹使用Git工具,运行$ git init,将该文件夹变为本地Git仓库,同时会生成一个隐藏的.git文件夹. 2.在该文件夹中用Not ...
- ASP微信开发获取用户经纬度
wx.config({ //debug: true, debug: true, appId: '<%= appId %>', timestamp: '<%= timestamp %& ...
- java(3) if结构
一.基本if结构 1.流程图 1)输入输出 2)判断和分支 3) 流程线 1.1 简单的if条件判断 if(表达式){ //表达式为true,执行{}中的代码 } 示例1:如 ...