python 多线程糗事百科案例
案例要求参考上一个糗事百科单进程案例
Queue(队列对象)
Queue是python中的标准库,可以直接import Queue引用;队列是线程间最常用的交换数据的形式
python下多线程的思考
对于资源,加锁是个重要的环节。因为python原生的list,dict等,都是not thread safe的。而Queue,是线程安全的,因此在满足使用条件下,建议使用队列
初始化: class Queue.Queue(maxsize) FIFO 先进先出
包中的常用方法:
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.full 与 maxsize 大小对应
Queue.get([block[, timeout]])获取队列,timeout等待时间
创建一个“队列”对象
- import Queue
- myqueue = Queue.Queue(maxsize = 10)
将一个值放入队列中
- myqueue.put(10)
将一个值从队列中取出
- myqueue.get()
多线程示意图
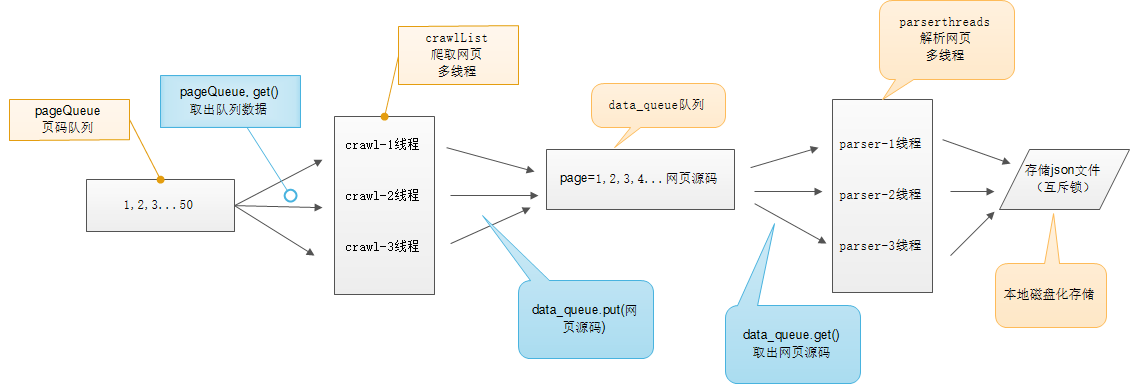
# -*- coding:utf-8 -*-import requestsfrom lxml import etreefrom Queue import Queueimport threadingimport timeimport jsonclass thread_crawl(threading.Thread):'''抓取线程类'''def __init__(self, threadID, q):threading.Thread.__init__(self)self.threadID = threadIDself.q = qdef run(self):print "Starting " + self.threadIDself.qiushi_spider()print "Exiting ", self.threadIDdef qiushi_spider(self):# page = 1while True:if self.q.empty():breakelse:page = self.q.get()print 'qiushi_spider=', self.threadID, ',page=', str(page)url = 'http://www.qiushibaike.com/8hr/page/' + str(page) + '/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36','Accept-Language': 'zh-CN,zh;q=0.8'}# 多次尝试失败结束、防止死循环timeout = 4while timeout > 0:timeout -= 1try:content = requests.get(url, headers=headers)data_queue.put(content.text)breakexcept Exception, e:print 'qiushi_spider', eif timeout < 0:print 'timeout', urlclass Thread_Parser(threading.Thread):'''页面解析类;'''def __init__(self, threadID, queue, lock, f):threading.Thread.__init__(self)self.threadID = threadIDself.queue = queueself.lock = lockself.f = fdef run(self):print 'starting ', self.threadIDglobal total, exitFlag_Parserwhile not exitFlag_Parser:try:'''调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。如果队列为空且block为False,队列将引发Empty异常。'''item = self.queue.get(False)if not item:passself.parse_data(item)self.queue.task_done()print 'Thread_Parser=', self.threadID, ',total=', totalexcept:passprint 'Exiting ', self.threadIDdef parse_data(self, item):'''解析网页函数:param item: 网页内容:return:'''global totaltry:html = etree.HTML(item)result = html.xpath('//div[contains(@id,"qiushi_tag")]')for site in result:try:imgUrl = site.xpath('.//img/@src')[0]title = site.xpath('.//h2')[0].textcontent = site.xpath('.//div[@class="content"]/span')[0].text.strip()vote = Nonecomments = Nonetry:vote = site.xpath('.//i')[0].textcomments = site.xpath('.//i')[1].textexcept:passresult = {'imgUrl': imgUrl,'title': title,'content': content,'vote': vote,'comments': comments,}with self.lock:# print 'write %s' % json.dumps(result)self.f.write(json.dumps(result, ensure_ascii=False).encode('utf-8') + "\n")except Exception, e:print 'site in result', eexcept Exception, e:print 'parse_data', ewith self.lock:total += 1data_queue = Queue()exitFlag_Parser = Falselock = threading.Lock()total = 0def main():output = open('qiushibaike.json', 'a')#初始化网页页码page从1-10个页面pageQueue = Queue(50)for page in range(1, 11):pageQueue.put(page)#初始化采集线程crawlthreads = []crawlList = ["crawl-1", "crawl-2", "crawl-3"]for threadID in crawlList:thread = thread_crawl(threadID, pageQueue)thread.start()crawlthreads.append(thread)#初始化解析线程parserListparserthreads = []parserList = ["parser-1", "parser-2", "parser-3"]#分别启动parserListfor threadID in parserList:thread = Thread_Parser(threadID, data_queue, lock, output)thread.start()parserthreads.append(thread)# 等待队列清空while not pageQueue.empty():pass# 等待所有线程完成for t in crawlthreads:t.join()while not data_queue.empty():pass# 通知线程是时候退出global exitFlag_ParserexitFlag_Parser = Truefor t in parserthreads:t.join()print "Exiting Main Thread"with lock:output.close()if __name__ == '__main__':main()
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- # 使用了线程库
- import threading
- # 队列
- from Queue import Queue
- # 解析库
- from lxml import etree
- # 请求处理
- import requests
- # json处理
- import json
- import time
- class ThreadCrawl(threading.Thread):
- def __init__(self, threadName, pageQueue, dataQueue):
- #threading.Thread.__init__(self)
- # 调用父类初始化方法
- super(ThreadCrawl, self).__init__()
- # 线程名
- self.threadName = threadName
- # 页码队列
- self.pageQueue = pageQueue
- # 数据队列
- self.dataQueue = dataQueue
- # 请求报头
- self.headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
- def run(self):
- print "启动 " + self.threadName
- while not CRAWL_EXIT:
- try:
- # 取出一个数字,先进先出
- # 可选参数block,默认值为True
- #1. 如果对列为空,block为True的话,不会结束,会进入阻塞状态,直到队列有新的数据
- #2. 如果队列为空,block为False的话,就弹出一个Queue.empty()异常,
- page = self.pageQueue.get(False)
- url = "http://www.qiushibaike.com/8hr/page/" + str(page) +"/"
- #print url
- content = requests.get(url, headers = self.headers).text
- time.sleep(1)
- self.dataQueue.put(content)
- #print len(content)
- except:
- pass
- print "结束 " + self.threadName
- class ThreadParse(threading.Thread):
- def __init__(self, threadName, dataQueue, filename, lock):
- super(ThreadParse, self).__init__()
- # 线程名
- self.threadName = threadName
- # 数据队列
- self.dataQueue = dataQueue
- # 保存解析后数据的文件名
- self.filename = filename
- # 锁
- self.lock = lock
- def run(self):
- print "启动" + self.threadName
- while not PARSE_EXIT:
- try:
- html = self.dataQueue.get(False)
- self.parse(html)
- except:
- pass
- print "退出" + self.threadName
- def parse(self, html):
- # 解析为HTML DOM
- html = etree.HTML(html)
- node_list = html.xpath('//div[contains(@id, "qiushi_tag")]')
- for node in node_list:
- # xpath返回的列表,这个列表就这一个参数,用索引方式取出来,用户名
- username = node.xpath('./div/a/@title')[0]
- # 图片连接
- image = node.xpath('.//div[@class="thumb"]//@src')#[0]
- # 取出标签下的内容,段子内容
- content = node.xpath('.//div[@class="content"]/span')[0].text
- # 取出标签里包含的内容,点赞
- zan = node.xpath('.//i')[0].text
- # 评论
- comments = node.xpath('.//i')[1].text
- items = {
- "username" : username,
- "image" : image,
- "content" : content,
- "zan" : zan,
- "comments" : comments
- }
- # with 后面有两个必须执行的操作:__enter__ 和 _exit__
- # 不管里面的操作结果如何,都会执行打开、关闭
- # 打开锁、处理内容、释放锁
- with self.lock:
- # 写入存储的解析后的数据
- self.filename.write(json.dumps(items, ensure_ascii = False).encode("utf-8") + "\n")
- CRAWL_EXIT = False
- PARSE_EXIT = False
- def main():
- # 页码的队列,表示20个页面
- pageQueue = Queue(20)
- # 放入1~10的数字,先进先出
- for i in range(1, 21):
- pageQueue.put(i)
- # 采集结果(每页的HTML源码)的数据队列,参数为空表示不限制
- dataQueue = Queue()
- filename = open("duanzi.json", "a")
- # 创建锁
- lock = threading.Lock()
- # 三个采集线程的名字
- crawlList = ["采集线程1号", "采集线程2号", "采集线程3号"]
- # 存储三个采集线程的列表集合
- threadcrawl = []
- for threadName in crawlList:
- thread = ThreadCrawl(threadName, pageQueue, dataQueue)
- thread.start()
- threadcrawl.append(thread)
- # 三个解析线程的名字
- parseList = ["解析线程1号","解析线程2号","解析线程3号"]
- # 存储三个解析线程
- threadparse = []
- for threadName in parseList:
- thread = ThreadParse(threadName, dataQueue, filename, lock)
- thread.start()
- threadparse.append(thread)
- # 等待pageQueue队列为空,也就是等待之前的操作执行完毕
- while not pageQueue.empty():
- pass
- # 如果pageQueue为空,采集线程退出循环
- global CRAWL_EXIT
- CRAWL_EXIT = True
- print "pageQueue为空"
- for thread in threadcrawl:
- thread.join()
- print "1"
- while not dataQueue.empty():
- pass
- global PARSE_EXIT
- PARSE_EXIT = True
- for thread in threadparse:
- thread.join()
- print "2"
- with lock:
- # 关闭文件
- filename.close()
- print "谢谢使用!"
- if __name__ == "__main__":
- main()
python 多线程糗事百科案例的更多相关文章
- Python爬虫(十八)_多线程糗事百科案例
多线程糗事百科案例 案例要求参考上一个糗事百科单进程案例:http://www.cnblogs.com/miqi1992/p/8081929.html Queue(队列对象) Queue是python ...
- Python爬虫(十七)_糗事百科案例
糗事百科实例 爬取糗事百科段子,假设页面的URL是: http://www.qiushibaike.com/8hr/page/1 要求: 使用requests获取页面信息,用XPath/re做数据提取 ...
- python 爬糗事百科
糗事百科网站段子爬取,糗事百科是我见过的最简单的网站了!!! #-*-coding:utf8-*- import requests import re import sys reload(sys) s ...
- Python 之糗事百科多线程爬虫案例
import requests from lxml import etree import json import threading import queue # 采集html类 class Get ...
- (python)查看糗事百科文字 点赞 作者 等级 评论
import requestsimport reheaders = { 'User-Agent':'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; ...
- 【Python爬虫实战】多线程爬虫---糗事百科段子爬取
多线程爬虫:即程序中的某些程序段并行执行,合理地设置多线程,可以让爬虫效率更高糗事百科段子普通爬虫和多线程爬虫分析该网址链接得出:https://www.qiushibaike.com/8hr/pag ...
- Python爬虫爬取糗事百科段子内容
参照网上的教程再做修改,抓取糗事百科段子(去除图片),详情见下面源码: #coding=utf-8#!/usr/bin/pythonimport urllibimport urllib2import ...
- 利用python的爬虫技术爬去糗事百科的段子
初次学习爬虫技术,在知乎上看了如何爬去糗事百科的段子,于是打算自己也做一个. 实现目标:1,爬取到糗事百科的段子 2,实现每次爬去一个段子,每按一次回车爬取到下一页 技术实现:基于python的实现, ...
- python 爬取糗事百科 gui小程序
前言:有时候无聊看一些搞笑的段子,糗事百科还是个不错的网站,所以就想用Python来玩一下.也比较简单,就写出来分享一下.嘿嘿 环境:Python 2.7 + win7 现在开始,打开糗事百科网站,先 ...
随机推荐
- UIView的transform属性
一.什么是Transform Transform(变化矩阵)是一种3×3的矩阵,如下图所示: 通过这个矩阵我们可以对一个坐标系统进行缩放,平移,旋转以及这两者的任意组着操作.而且矩阵的操作不具备交换律 ...
- vue - node_modules
详情见:node_modules导包机制 在打包或者结束项目时,这个文件夹(node_modules)不应该被打包. 你应该打包其它的文件,如果要运行(直接用以下命令安装即可,它会根据package. ...
- 在Docker中执行web应用
启动一个简单的web 应用 使用社区提供的模板,启动一个简单的web应用,熟悉下各种Docker命令的使用: # docker run -d -P training/webapp python app ...
- Linux-查看进程的完整路径
通过ps及top命令查看进程信息时,只能查到相对路径,查不到的进程的详细信息,如绝对路径等.这时,我们需要通过以下的方法来查看进程的详细信息:Linux在启动一个进程时,系统会在/proc下创建一个以 ...
- js jquery 结束循环
js 中跳出循环用break,结束本次循环用continue,jqeruy 中循环分别对应 return false 和return true. jquery 中each循环 跳出用return tr ...
- VMware配置网络的3种方式:NAT、Host-Only、Bridged
网络常识: 1.网络中对电脑的访问是通过ip定位的 就好像我们的身份证号,可以唯一辨识一个人.ip是用来区分网络中的电脑的,因此同一网络(准确讲是“网段”)中,ip地址不能相同.如果同一网络中有相同的 ...
- Kafka 快速起步
Kafka 快速起步 原创 2017-01-05 杜亦舒 性能与架构 性能与架构 性能与架构 微信号 yogoup 功能介绍 网站性能提升与架构设计 主要内容:1. kafka 安装.启动2. 消息的 ...
- unity, trail renderer gone black on iOS
给物体加了个trail renderer,使用了Legacy Shaders/Transparent/Diffuse,并将颜色调成白色半透明.在编辑器里效果是对的,但在ios上真机测试变成黑色的.然后 ...
- hsqldb
http://www.hsqldb.org/ HSQLDB (HyperSQL DataBase) is the leading SQL relational database software wr ...
- 详解Java中格式化日期的DateFormat与SimpleDateFormat类
DateFormat其本身是一个抽象类,SimpleDateFormat 类是DateFormat类的子类,一般情况下来讲DateFormat类很少会直接使用,而都使用SimpleDateFormat ...