决策树&随机森林
参考链接:
https://www.bilibili.com/video/av26086646/?p=8
《统计学习方法》
一、决策树算法:
1.训练阶段(决策树学习),也就是说:怎么样构造出来这棵树?
2.剪枝阶段。
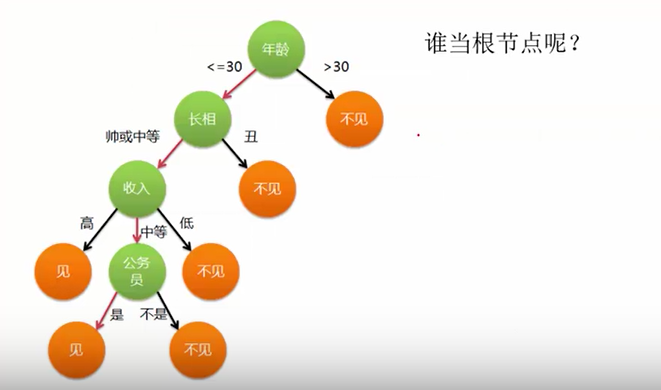
问题1:构造决策树,谁当根节点?例:相亲时为啥选年龄作为根节点?
H(X)为事件发生的不确定性。
事件X,Y相互独立,概率P(X),P(Y)。认为:P(几率越大)->H(X)越小,如今天正常上课。P(几率越小)->H(X)越大,如今天翻车了。
熵是表示随机变量不确定性的度量。熵越大,不确定性越大,越混乱。
设X是一个取有限个值的离散随机变量,其概率分布为:P(X=xi)=pi, i=1,2,...,n,则随机变量X的熵定义为:

由定义可知,熵只依赖于X的分布,而与X的取值无关,所以也可将X的熵记做H(p)。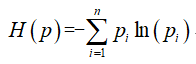
例2:对于两个集合A,B来说,如果A比较混乱,B内部比较单一纯净,那么集合A的熵更大。
思想:构造决策树,随着深度的增加,节点的熵迅速降低。熵降低的速度越快越好,迅速地构建出决策树。\
案例(根据天气判断是否打篮球):
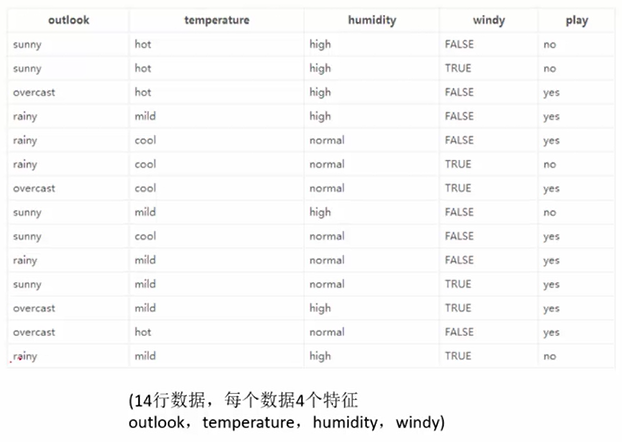
1.先计算原始数据的熵,为0.940.

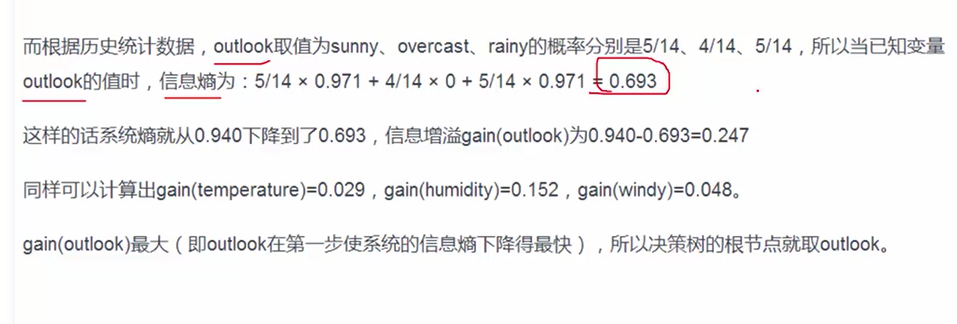
2.再计算按照4中划分方式得到的熵(确切地说,是条件熵,H(Y|X)),以及信息增益gain。比如基于Outlook划分时,熵为0.693,信息增益=0.940-0.693=0.247.算出四种划分的信息增益,越大越好,得出gain(outlook)最大的结论。


问题2:怎么样衡量最终决策树好不好,衡量划分的效果呢?机器学习算法中,都有一个目标函数。
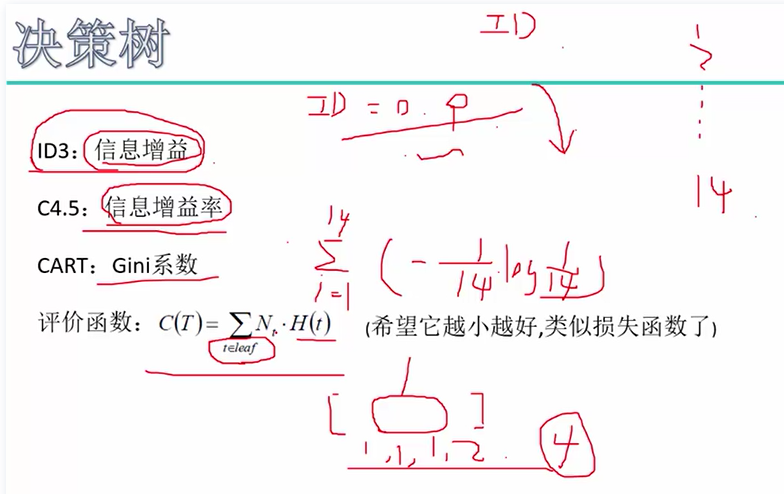
我们希望最后的C(T)越小越好,越小说明分类效果还不错。
问题3:若属性值是连续的怎么办?离散化,用阈值和不等式来离散化。如下例子所示:
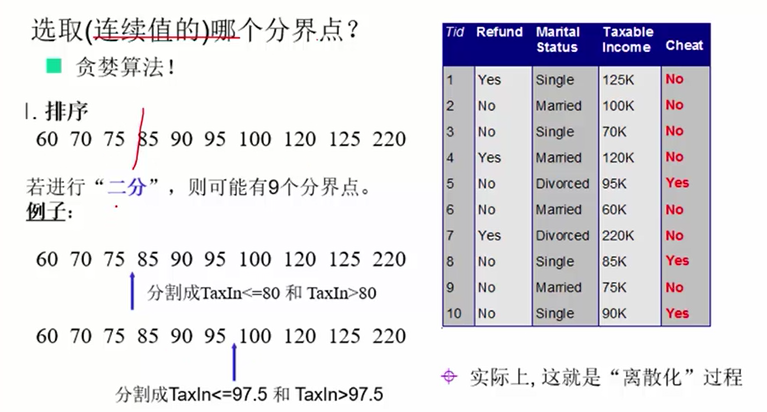
思想:我们希望得到一颗高度最矮的决策树。
切得太碎,太细,容易出现过拟合。即树不能太高,因为树越高说明分支越多。因此,思考怎么样使得建立的决策树别把所有的叶子节点都只包含一个样本。
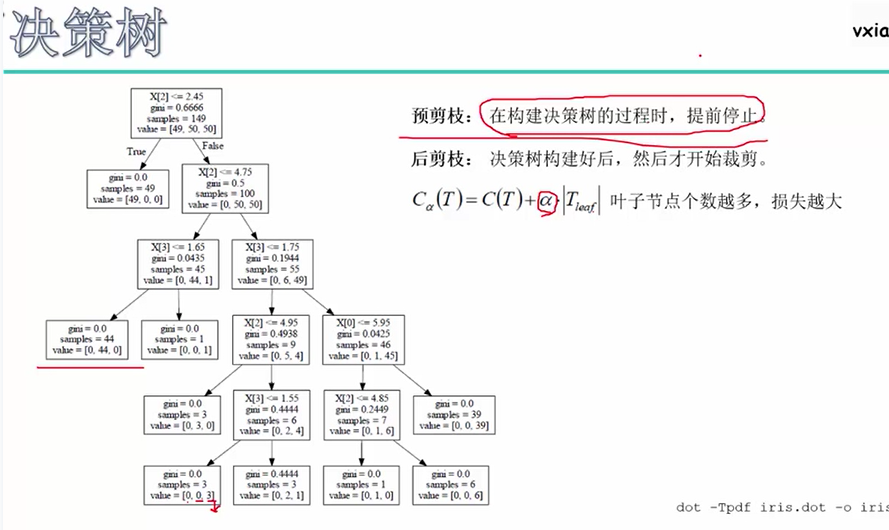
预剪枝:比如d=3,当高度超过3时停止分裂;比如min_sample=50,也就是说节点所含的样本数低于50个时,停止分裂。
后剪枝:C(T)为原来的评价函数,新的评价函数Cα(T)考虑了叶子节点的个数。
二、随机森林算法
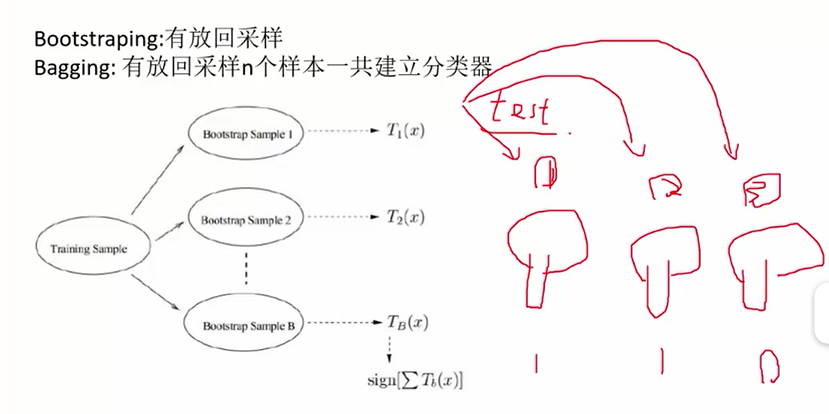
随机森林:构造出多棵决策树,然后分类问题取众数(或者其它取法),回归问题取平均数。用这一片决策树进行预测。
随机森林:1.建立每一棵树的时候,都随机选择其中一部分样本(有放回地采样!),这样有时候可以避免掉不好的样本点,从而构造出比较好的树。
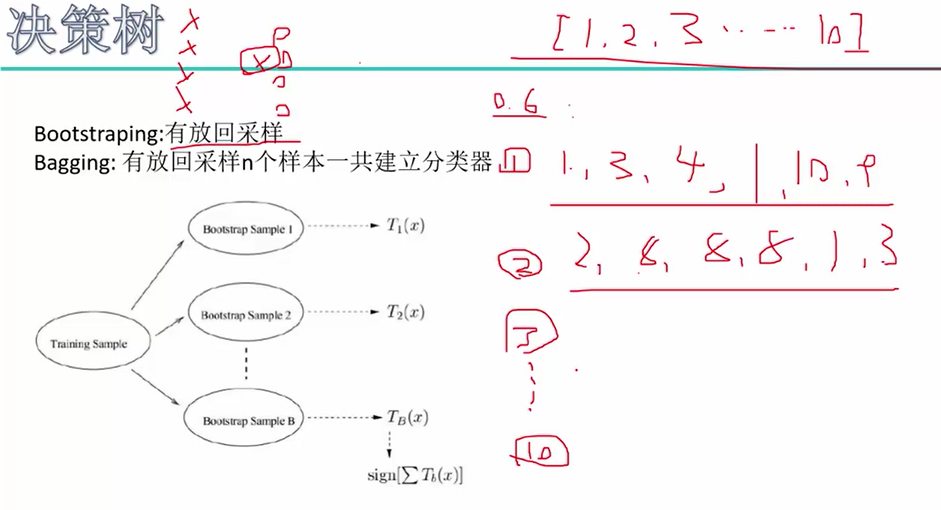
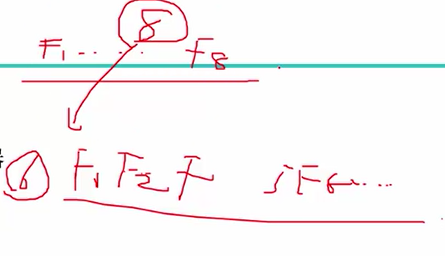
2.构建每一棵树时,随机选择一部分特征(比如8个特征里面取6个)。两重随机性,第一重是样本的随机性,第二重是特征的随机性。
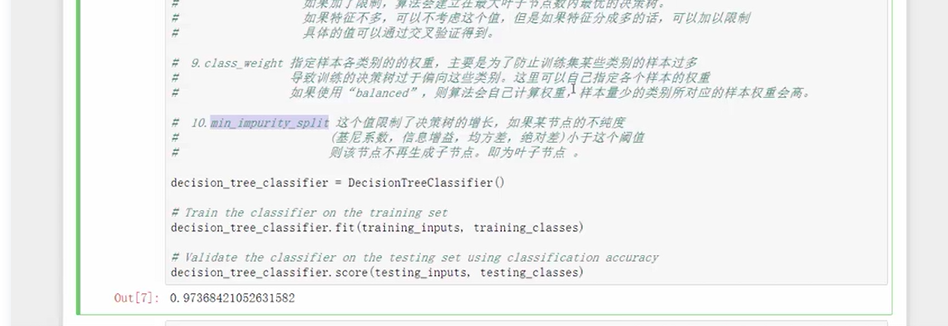
三、python实战——鸢尾花分类
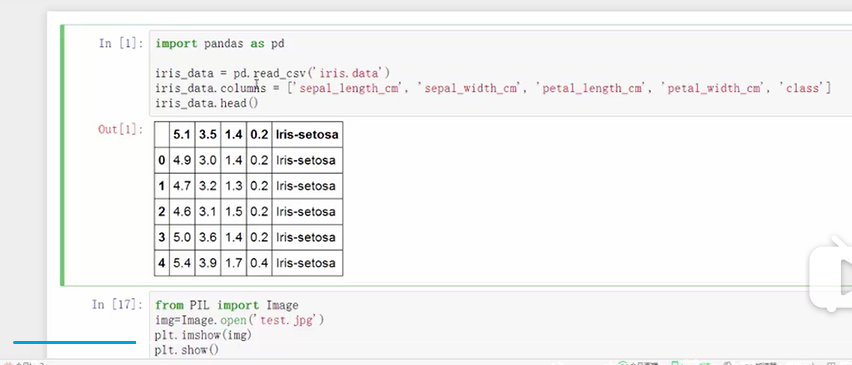
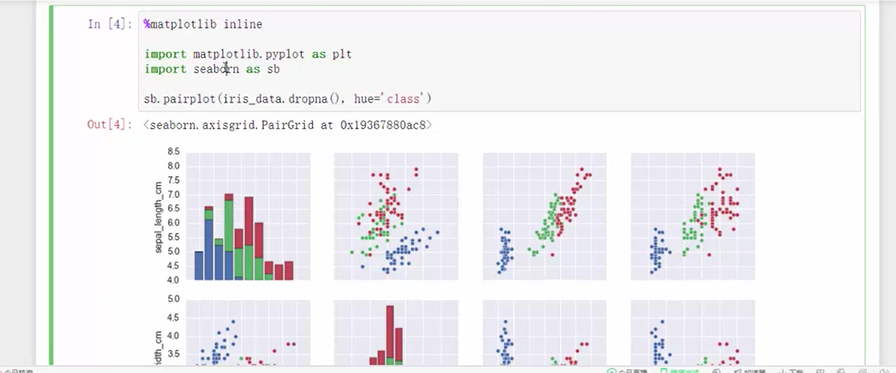
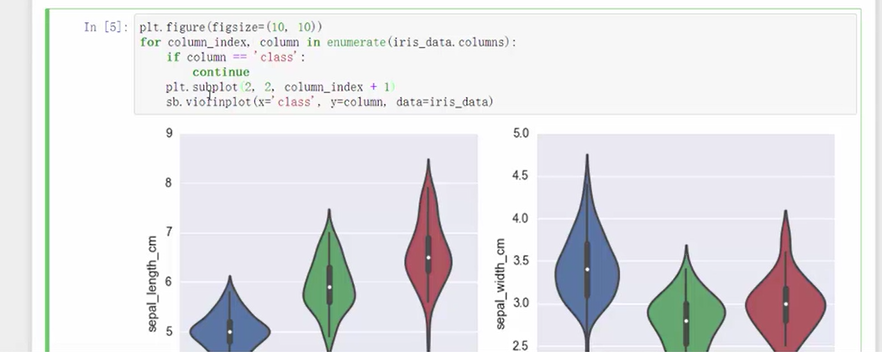
代码:

决策树&随机森林的更多相关文章
- AI学习---分类算法[K-近邻 + 朴素贝叶斯 + 决策树 + 随机森林 ]
分类算法:对目标值进行分类的算法 1.sklearn转换器(特征工程)和预估器(机器学习) 2.KNN算法(根据邻居确定类别 + 欧氏距离 + k的确定),时间复杂度高,适合小数据 ...
- bootstrap && bagging && 决策树 && 随机森林
看了一篇介绍这几个概念的文章,整理一点点笔记在这里,原文链接: https://machinelearningmastery.com/bagging-and-random-forest-ensembl ...
- scikit-learn机器学习(四)使用决策树做分类,并画出决策树,随机森林对比
数据来自 UCI 数据集 匹马印第安人糖尿病数据集 载入数据 # -*- coding: utf-8 -*- import pandas as pd import matplotlib matplot ...
- 美团店铺评价语言处理以及分类(tfidf,SVM,决策树,随机森林,Knn,ensemble)
第一篇 数据清洗与分析部分 第二篇 可视化部分, 第三篇 朴素贝叶斯文本分类 支持向量机分类 支持向量机 网格搜索 临近法 决策树 随机森林 bagging方法 import pandas as pd ...
- 随机森林(Random Forest),决策树,bagging, boosting(Adaptive Boosting,GBDT)
http://www.cnblogs.com/maybe2030/p/4585705.html 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- sklearn_随机森林random forest原理_乳腺癌分类器建模(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Adaboost和随机森林
在集成学习中,主要分为bagging算法和boosting算法.随机森林属于集成学习(Ensemble Learning)中的bagging算法. Bagging和Boosting的概念与区别该部分主 ...
随机推荐
- ubuntu 摄像头软件
sudo apt-get install cheese
- UVALive 4025 Color Squares(BFS)
题目链接:UVALive 4025 Color Squares 按题意要求放带有颜色的块,求达到w分的最少步数. //yy:哇,看别人存下整个棋盘的状态来做,我什么都不想说了,不知道下午自己写了些什么 ...
- codeforces 792C. Divide by Three
题目链接:codeforces 792C. Divide by Three 今天队友翻了个大神的代码来问,我又想了遍这题,感觉很好,这代码除了有点长,思路还是清晰易懂,我就加点注释存一下...分类吧. ...
- Sublime Text 3中关闭记住上次打开的文件
使用UltraEdit的时候,每次安装后就得修改一堆配置,其中一项便是关闭“打开上一次未关闭的文件”,Sublime Text 2也有这么一个默认的功能,在实际使用中,这种方式确实可以较快速的访问文件 ...
- HDU 6464 免费送气球 【权值线段树】(广东工业大学第十四届程序设计竞赛)
传送门:http://acm.hdu.edu.cn/showproblem.php?pid=6464 免费送气球 Time Limit: 2000/1000 MS (Java/Others) M ...
- JDBC(3)ResultSet
ResultSet 在执行查询(select)时候使用 这是一个结果对象,该对象包含结果的方法但指针定位到一行时 调用Statement 对象的 executeQuery(sql)可以得到结果集 可以 ...
- 浅谈sql之连接查询
SQL之连接查询 一.连接查询的分类 sql中将连接查询分成四类: 内链接 外连接 左外连接 右外连接 自然连接 交叉连接 二.连接查询的分类 数据库表如下: 1.学生表 2.老师表 3.班级表 表用 ...
- STC12LE5620AD RAM问题
1.此款单片机内部有 sram:768B=512B(aux)+256B(Internal) 2.内部RAM解析 2. 3.内部扩展RAM 4.keil中可以选择内存类型 5. 网上摘抄的一段话: 在S ...
- JAVA给你讲它的故事
计算机语言如果你将它当做一个产品,就像我们平时用的电视机.剃须刀.电脑.手机等, 他的发展也是有规律的. 任何一个产品的发展规律都是:向着人更加容易使用.功能越来越强大的方向发展. 那么,我们的计算机 ...
- Hibernate一级缓存和三种状态
Hibernate一级缓存又称session缓存,生命周期很短,跟session生命周期相同. 三种状态:1.transient(瞬时态):刚new出来的对象,既不在数据库中,也不在session管理 ...