spark启动原理总结
一般情况下,我们启动spark集群都是start-all.sh或者是先启动master(start-master.sh),然后在启动slave节点(start-slaves.sh),其实翻看start-all.sh文件里面的代码,可以发现它里面其实调用的执行的也是start-master.sh和start-slaves.sh文件的内容:
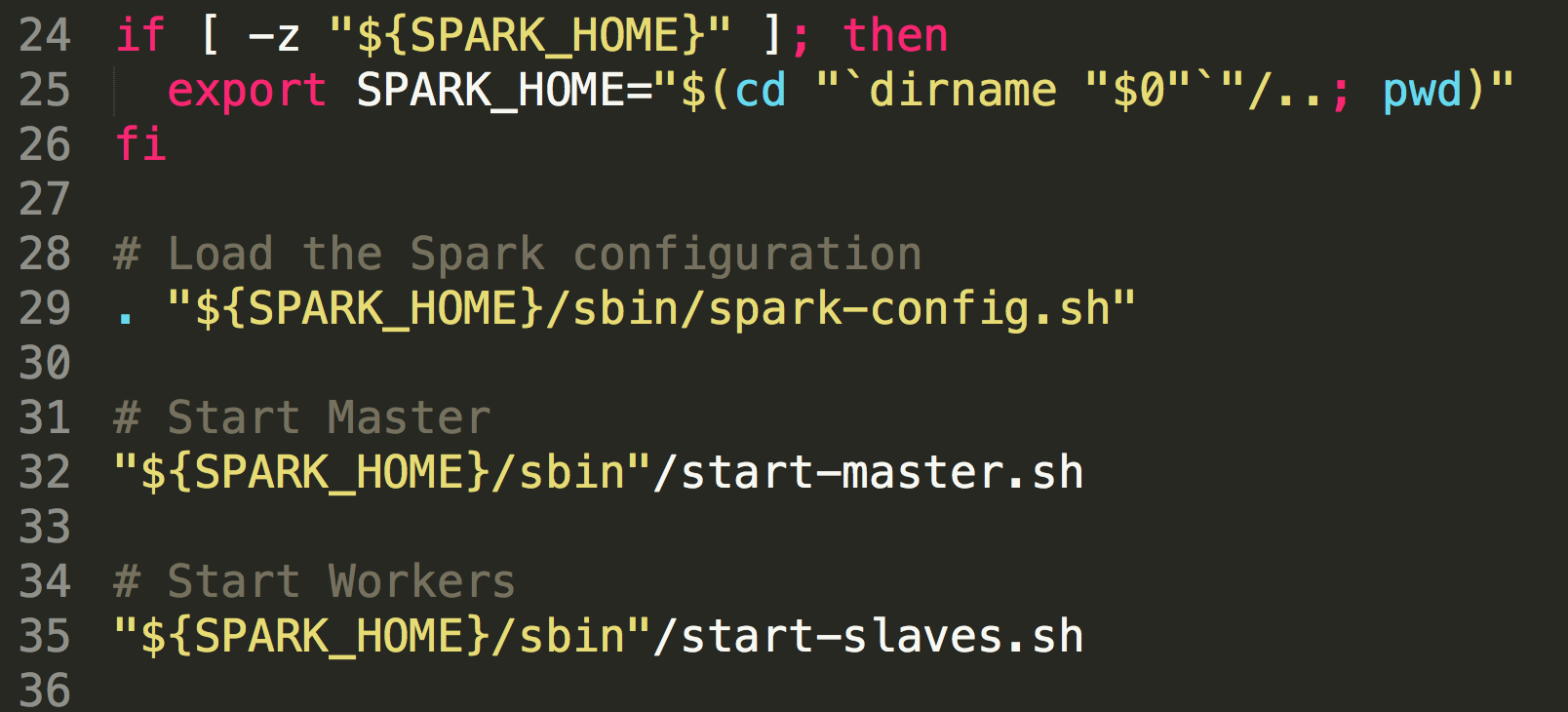
在start-master.sh中定义了CLASS="org.apache.spark.deploy.master.Master" ,最终调用其main方法启动master服务,在start-slaves.sh文件中有调用了start-slave.sh内容,只是定义了
CLASS="org.apache.spark.deploy.worker.Worker"来启动worker。
接下来先看master中的main方法,在main方法中调用了startRpcEnvAndEndpoint()方法,来定义并启动消息通信。
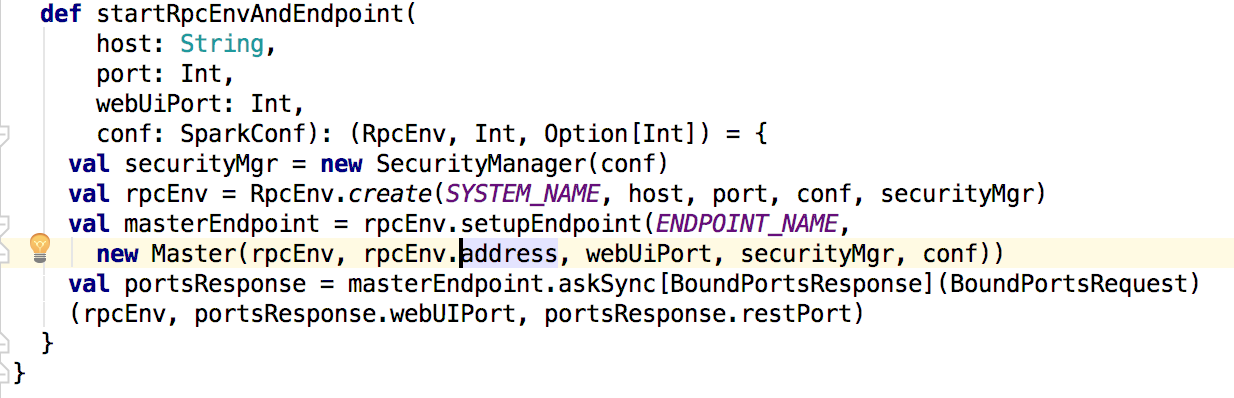
在启动服务端master通信的时候,会在inbox中调用master的onStart方法(关于spark RPC可以查阅其他博客);下面就分析master的onStart方法:
override def onStart(): Unit = {
logInfo("Starting Spark master at " + masterUrl)
logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}")
webUi = new MasterWebUI(this, webUiPort)
webUi.bind()
masterWebUiUrl = "http://" + masterPublicAddress + ":" + webUi.boundPort
if (reverseProxy) {
masterWebUiUrl = conf.get("spark.ui.reverseProxyUrl", masterWebUiUrl)
webUi.addProxy()
logInfo(s"Spark Master is acting as a reverse proxy. Master, Workers and " +
s"Applications UIs are available at $masterWebUiUrl")
}
checkForWorkerTimeOutTask = forwardMessageThread.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(CheckForWorkerTimeOut)
}
}, 0, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)
if (restServerEnabled) {
val port = conf.getInt("spark.master.rest.port", 6066)
restServer = Some(new StandaloneRestServer(address.host, port, conf, self, masterUrl))
}
restServerBoundPort = restServer.map(_.start())
masterMetricsSystem.registerSource(masterSource)
masterMetricsSystem.start()
applicationMetricsSystem.start()
// Attach the master and app metrics servlet handler to the web ui after the metrics systems are
// started.
masterMetricsSystem.getServletHandlers.foreach(webUi.attachHandler)
applicationMetricsSystem.getServletHandlers.foreach(webUi.attachHandler)
val serializer = new JavaSerializer(conf)
val (persistenceEngine_, leaderElectionAgent_) = RECOVERY_MODE match {
case "ZOOKEEPER" =>
logInfo("Persisting recovery state to ZooKeeper")
val zkFactory =
new ZooKeeperRecoveryModeFactory(conf, serializer)
(zkFactory.createPersistenceEngine(), zkFactory.createLeaderElectionAgent(this))
case "FILESYSTEM" =>
val fsFactory =
new FileSystemRecoveryModeFactory(conf, serializer)
(fsFactory.createPersistenceEngine(), fsFactory.createLeaderElectionAgent(this))
case "CUSTOM" =>
val clazz = Utils.classForName(conf.get("spark.deploy.recoveryMode.factory"))
val factory = clazz.getConstructor(classOf[SparkConf], classOf[Serializer])
.newInstance(conf, serializer)
.asInstanceOf[StandaloneRecoveryModeFactory]
(factory.createPersistenceEngine(), factory.createLeaderElectionAgent(this))
case _ =>
(new BlackHolePersistenceEngine(), new MonarchyLeaderAgent(this))
}
persistenceEngine = persistenceEngine_
leaderElectionAgent = leaderElectionAgent_
}
在这个方法里面首先针对webui进行了一系列的处理,然后启动一个线程来检查任何超时的worker,并且清除它;其次处理了一些关于Metrics的内容和在多个master下面的的关于元数据和master选举的一些机制;
根据spark.deploy.recoveryMode设置的参数,可以是ZOOKEEPER,FILESYSTEM,CUSTOM,默认为NONE,当是zookeeper时,基于ZooKeeper选举,元数据信息会持久化到ZooKeeper中。当是fileSystem时集群的元数据会保存到本地的文件系统中,而master启动会立即成为集群的master。当是custom时,是用户自定义,需要实现StandaloneRecoveryModeFactory,并将类的名字配置到spark.deploy.recoveryMode.factory;当是NONE的时候不会持久化元数据信息,master启动会即是集群的master。
接下来看看worker中的处理,在worker的mian方法中调用的是startRpcEnvAndEndpoint()方法
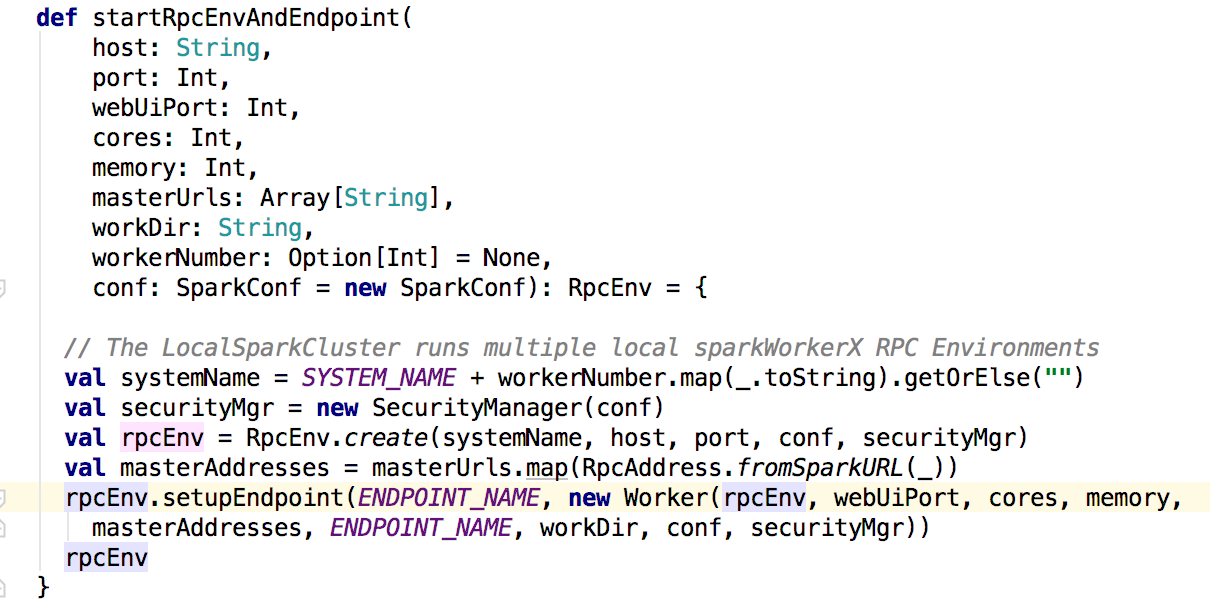
上面的方法也是注册启动了worker的消息通信,同理也会调用worker的onStart方法。在onstart方法里面会调用registerWithMaster()方法来注册到master上。

在这个方法里面会调用tryRegisterAllMasters来注册到master,在其后面是关于重试的处理,主要是判断registered的值来进行相应的处理。接下来是tryRegisterAllMasters方法:
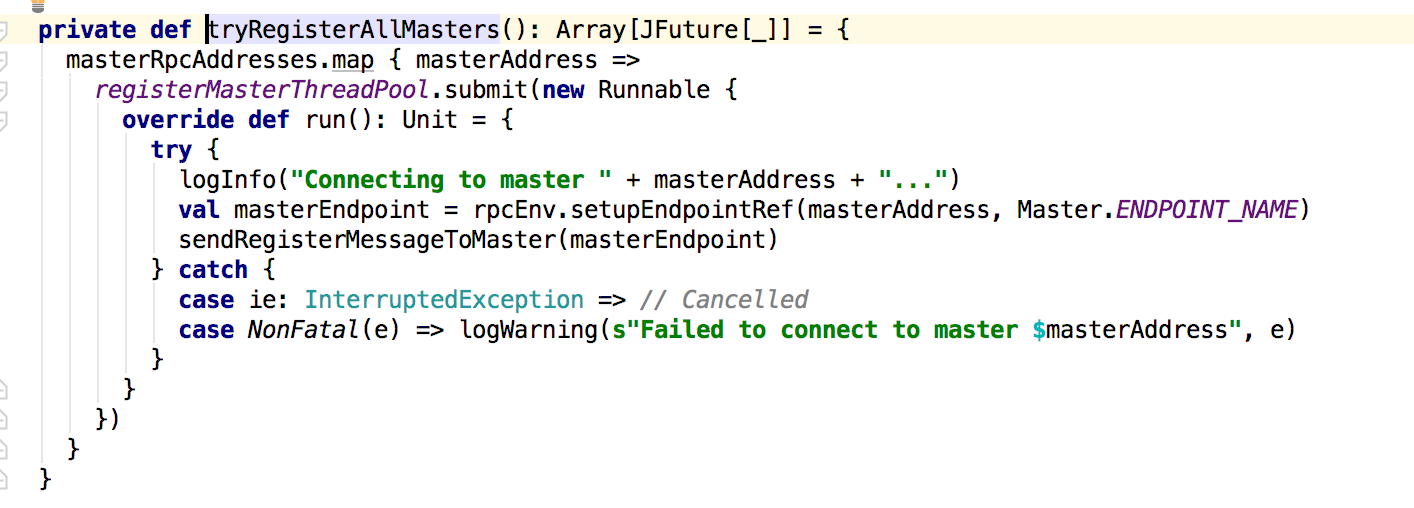
这里会创建一个注册master的线程池来管理,发送的消息在sendRegisterMessageToMaster方法中,就是发送一个RegisterWorker的消息给master;接下俩看master对这个消息的处理:
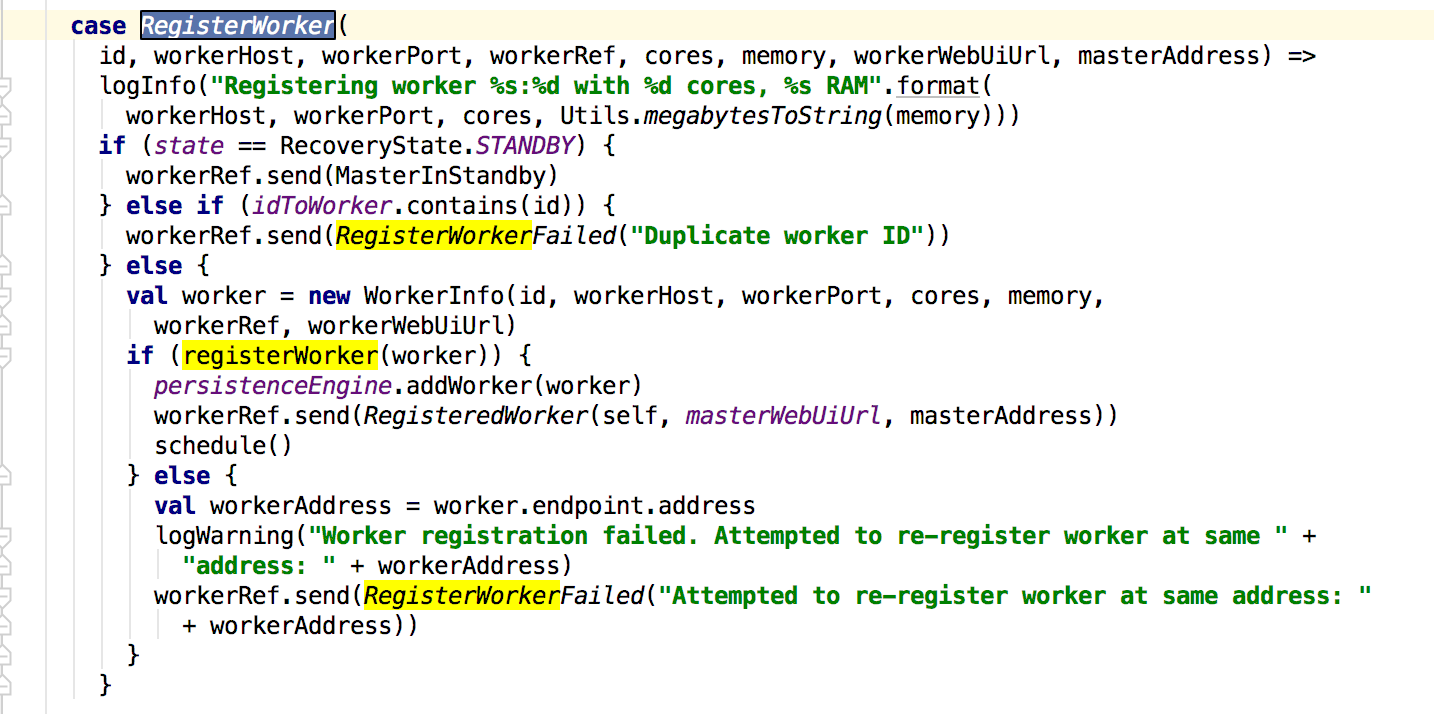
master在接收到这个消息的时候会先判断state状态以及现有注册的worker是否存在新的注册的worker的id,若状态和id没有匹配到则新建一个workerInfo来保存worker的信息,最后调用registerWorker方法添加worker,早真正添加完成之后,会给worker发送RegisteredWorker消息,其后会调用schedule方法;下面先看worker接收到消息的处理:
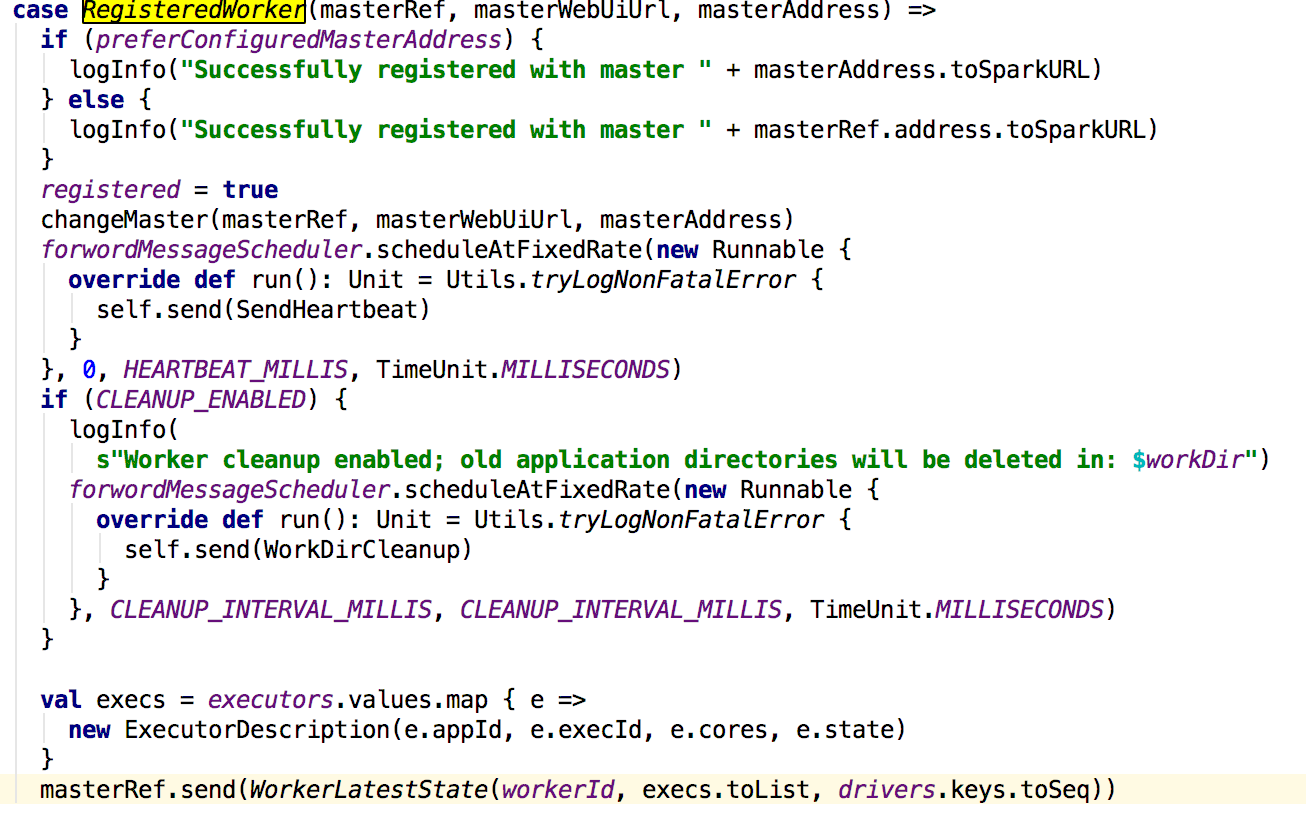
worker在接收到来master的消息之后,先更新registered的值,然后更新master的信息,启动一个线程定时给master发送心跳信息,如果配置了spark.worker.cleanup.enabled为true,则进行清理工作,最后会向master发送worker的exector的信息。
到这个时候master和worker已经完全启动,接下来就是启动worker中的exectors。这个改天再说!
spark启动原理总结的更多相关文章
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
- Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本课主题 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 Spark Worke ...
- .Spark Streaming(上)--实时流计算Spark Streaming原理介
Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍 http://www.cnblogs.com/shishanyuan/p/474 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
- 小记---------spark架构原理&主要组件和进程
spark的主要组件和进程 driver (进程): 我们编写的spark程序就在driver上,由driver进程执行 master(进程): 主要负责资源的 ...
- MySQL 启动原理剖析
200 ? "200px" : this.width)!important;} --> 介绍 本篇文章主要从查看MySQL的启动命令的代码来详细了解MySQL的启动过程,内容 ...
- 【原】iOS学习之应用程序的启动原理
最近看视频了解了一下应用程序的启动原理,这里就做一个博客和大家分享一下,相互讨论,如果有什么补充或不同的意见可以提出来! 1.程序入口 众所周知,一个应用程序的入口一般是一个 main 函数,iOS也 ...
- iOS app 程序启动原理
iOS app 程序启动原理 Info.plist: 常见设置 建立一个工程后,会在Supporting files文件夹下看到一个"工程名-Info.plist"的文件, ...
- iOS的常见文件及程序的启动原理
一. iOS中常见文件 (一). Xcode6之前 创建项目,默认可以看见一个存放框架的文件夹 info文件以工程文件名开头,如:第一个项目-Info.plist 项目中默认有一个PCH文件 (二). ...
随机推荐
- Ssh 证书验证登录
一般使用 PuTTY 等 SSH 客户端来远程管理 Linux 服务器.但是,一般的密码方式登录,容易有密码被暴力破解的问题.所以,一般我们会将 SSH 的端口设置为默认的 22 以外的端口,或者禁用 ...
- Eclipse 无法编译,提示“错误: 找不到或无法加载主类”
jar包问题: 1.项目的Java Build Path中的Libraries中有个jar包的Source attachment指为了一个不可用的jar包, 解决办法是:将这个不可用的jar包remo ...
- 【Leetcode】【Medium】Binary Tree Inorder Traversal
Given a binary tree, return the inorder traversal of its nodes' values. For example:Given binary tre ...
- windows10下运行XX-net
现在墙高了,原来配置的ip4没法用了,所以重新配置一下XX-NET,这篇博客的内容参考了末尾的网站,如果我的办法行不通可以去这个网站查看其他方法 下载XX-NET 打开https://github.c ...
- July 13th 2017 Week 28th Thursday
No dream is too big, and no dreamer is too small. 梦想再大也不嫌大,追梦的人再小也不嫌小. Hold on to your dreams, but b ...
- 记一次挖掘115网盘反射型xss,08xss的储存型xss
记一次对115分站简单绕过过滤继续实现xss,08xss平台也中枪!! 115反射型xss url:http://115.qiye.115.com/disk/?ac=select_public_fil ...
- linux-记录
查看运行的进程 ps -aux|grep java 找到要删除的进程的编号 杀死进程 kill -9 1883(进程编号) 重启服务 sh satrtBussinessService.sh
- java中的泛型1
1.泛型概述 泛型,即“参数化类型”.一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参.那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数 ...
- 上下文(context):相关的内容
简单的理解,就是相关的内容 模式是在某种特定的场景(context)下某个不断重复出现的问题的解决方案. 环境:上下文:来龙去脉 上下文:语境:环境 网络背景:情境:脉络 context其实说白了,和 ...
- io操作的要素
文件 操作. 操作说明 数据