Python爬虫编程常见问题解决方法
Python爬虫编程常见问题解决方法:
1.通用的解决方案:
【按住Ctrl键不送松】,同时用鼠标点击【方法名】,查看文档
2.TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
问题描述:【类型错误】就是数据的类型应该是bytes类型,而不是str类型
解决方案:
data = data.encode('utf-8')
3.爬取得到的HTML在一行显示
调试步骤:通过print(type(html))查看html的类型, 可以查出是bytes类型,就需要解码
解决方案:
html = html.decode()
4.有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器
解决方案:
header = {"User-Agent": "mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"}
req = request.Request(url=base_url,data=bytes(data,encoding='utf-8'),headers=header)
5.当服务器返回json格式的数据乱码
调试步骤:
1.通过print(type(json_data))查看数据的类型,
2.可以查出是str类型,就是说返回的字符串中有bytes类型的数据
解决方案:把json字符串转换为字典
json_data = json.loads(json_data)
6.怎么只输出json数据的value或者某个key对应的value,不要[{}]
问题描述: 想要jsonkey/value的一部分
典型案例:
例如:
json_data=
{'errno': 0,
'data': [{'k': 'good',
'v': 'adj. 好的;'
},
{'k': 'good morning',
'v': 'int. 早安;'
}
]
}
要求: 只想要输出good: adj. 好的,而不要其他的格式
1.可以通过json_data['data'],只输出json数据json_data中‘data’对应的值,也就是
[{'k': 'good',
'v': 'adj. 好的;'
},
{'k': 'good morning',
'v': 'int. 早安;'
}
]
2.遍历输出每个'k'和'v'的值
# 遍历输出每个'k'和'v'的值
for item in json_data['data']:
print(item['k'], ": ", item['v'])
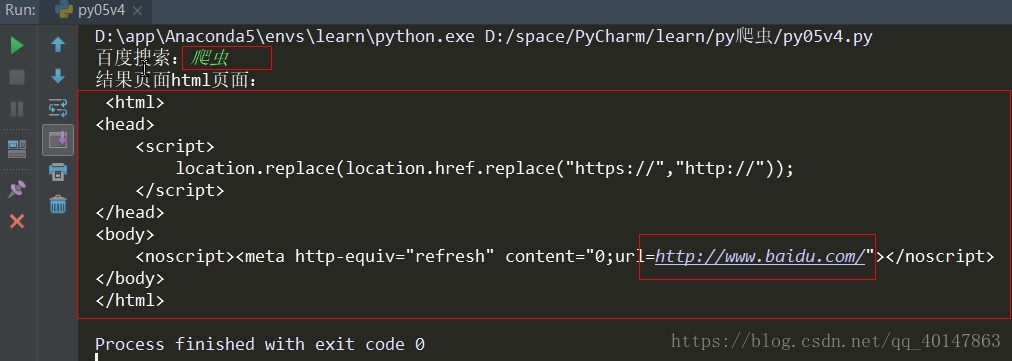
7.返回的页面是一个链接,而不是链接的页面
问题描述: 百度搜索,我们输入搜索内容,返回的是一个包括原地址链接的html,而不是访问该链接 的html,且返回的html中:location.replace(location.href.replace("https://","http://"));
问题实例截图:
解决方案: 如果使用的是http改成https,
如果使用的是https改成http,就可以了
我的爬虫笔记
- Python爬虫教程-01-爬虫介绍
- Python爬虫教程-02-使用urlopen
- Python爬虫教程-03-使用 chardet 检测编码
- Python爬虫教程-04-response简介
- Python爬虫教程-05-python爬虫实现百度翻译
- Python爬虫教程-06-爬虫实现百度翻译(requests)
- Python爬虫教程-07-post介绍(百度翻译)(上)
- Python爬虫教程-08-post介绍(百度翻译)(下)
- Python爬虫教程-09-error 模块
- Python爬虫教程-10-UserAgent和常见浏览器UA值
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
- Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
- Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)
- Python爬虫教程-15-读取cookie(人人网)和SSL(12306官网)
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
- Python爬虫教程-18-页面解析和数据提取
- Python爬虫教程-19-数据提取-正则表达式(re)
- Python爬虫教程-20-xml简介
- Python爬虫教程-21-xpath
- Python爬虫教程-22-lxml-etree和xpath配合使用
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
- Python爬虫教程-24-数据提取-BeautifulSoup4(二)
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
- Python爬虫教程-26-Selenium + PhantomJS
- Python爬虫教程-27-Selenium Chrome版本与chromedriver兼容版本对照表
- Python爬虫教程-28-Selenium 操纵 Chrome
- Python爬虫教程-29-验证码识别-Tesseract-OCR
- Python爬虫教程-30-Scrapy 爬虫框架介绍
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
- Python爬虫教程-33-scrapy shell 的使用
- Python爬虫教程-34-分布式爬虫介绍
- 本笔记不允许任何个人和组织转载
Python爬虫编程常见问题解决方法的更多相关文章
- [python爬虫] Selenium常见元素定位方法和操作的学习介绍(转载)
转载地址:[python爬虫] Selenium常见元素定位方法和操作的学习介绍 一. 定位元素方法 官网地址:http://selenium-python.readthedocs.org/locat ...
- 老出BUG怎么办?游戏服务器常见问题解决方法分享
在游戏开发中,我们经常会遇到一些技术难题,而其引发的bug则会影响整个游戏的品质.女性向手游<食物语>就曾遇到过一些开发上的难题,腾讯游戏学院专家团Wade.Zc.Jovi等专家为其提供了 ...
- OpenStack安装部署管理中常见问题解决方法
一.网络问题-network 更多网络原理机制可以参考<OpenStack云平台的网络模式及其工作机制>. 1.1.控制节点与网络控制器区别 OpenStack平台中有两种类型的物理节点, ...
- Web Deploy发布网站及常见问题解决方法(图文)
Web Deploy发布网站及常见问题解决方法(图文) Windows2008R2+IIs7.5 +Web Deploy 3.5 Web Deploy 3.5下载安装 http://www.iis.n ...
- python字符串的常见处理方法
python字符串的常见处理方法 方法 使用说明 方法 使用说明 string[start:end:step] 字符串的切片 string.replace 字符串的替换 string.split 字符 ...
- [python爬虫] Selenium常见元素定位方法和操作的学习介绍
这篇文章主要Selenium+Python自动测试或爬虫中的常见定位方法.鼠标操作.键盘操作介绍,希望该篇基础性文章对你有所帮助,如果有错误或不足之处,请海涵~同时CSDN总是屏蔽这篇文章,再加上最近 ...
- Python 爬虫入门3种方法
Python 2.0 url = "http://www.baidu.com" print '第一种方法' response1 = urllib2.urlopen(url) pri ...
- python爬虫中文乱码解决方法
python爬虫中文乱码 前几天用python来爬取全国行政区划编码的时候,遇到了中文乱码的问题,折腾了一会儿,才解决.现特记录一下,方便以后查看. 我是用python的requests和bs4库来实 ...
- (转)Python中的常见特殊方法—— repr方法
原文链接:https://www.cnblogs.com/tizer/p/11178473.html 在Python中有些方法名.属性名的前后都添加了双下划线,这种方法.属性通常都属于Python的特 ...
随机推荐
- SD与SE的关系,以及异常值
很多刚进入实验室的同学对实验数据的标准差(SD)与标准误(SE)的含义搞不清,不知道自己的数据报告到底该用SD还是SE.这里对这两个概念进行一些介绍. 标准差(SD)强调raw data的Variat ...
- 浅析PHP反序列化漏洞之PHP常见魔术方法(一)
作为一个学习web安全的菜鸟,前段时间被人问到PHP反序列化相关的问题,以前的博客中是有这样一篇反序列化漏洞的利用文章的.但是好久过去了,好多的东西已经记得不是很清楚.所以这里尽可能写一篇详细点的文章 ...
- PIE SDK与OpenCV结合说明文档
1.功能简介 OpenCV是基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux.Windows.Android和Mac OS操作系统上.它轻量级而且高效——由一系列 C 函数和少量 ...
- git常用安装包,指令
babel-polufill -es6 API转义 npm install --save @babel/polyfill babel-runtime -es语法转义 npm install --s ...
- [转]矩阵树$Matrix-Tree$定理与行列式
[https://www.cnblogs.com/zj75211/p/8039443.html][矩阵树Matrix-Tree定理与行列式]
- Html checkbox全选
html中全选 <table class="data-table td-center"> <tr> <td><input type=&qu ...
- 【python】-matplotlib.pylab常规用法
目的: 了解matplotlib.pylab常规用法 示例 import matplotlib.pylab as pl x = range(10) y = [i * i for i in x] pl. ...
- git 学习之什么是版本库
什么是版本库? 我们一般把版本库也叫仓库(repository),其实我们可以简单的把它看成一个目录,只不过目录里面的文件都会由 Git 进行管理,当我们对文件进行修改.删除.Git 都可以对其进行跟 ...
- r.js 配置文件 example.build.js 不完整注释
/* * This is an example build file that demonstrates how to use the build system for * require.js. * ...
- IE浏览器报Promise未定义
用vue-cli做的项目,用了promise,结果IE下报promise未定义,甚至在比较老的andriod手机浏览器上会显示空白页面,解决方案如下: 首先安装:babel-polyfill npm ...