Spark集群无法停止的原因分析和解决
今天想停止spark集群,发现执行stop-all.sh的时候spark的相关进程都无法停止。提示:
no org.apache.spark.deploy.master.Master to stop
no org.apache.spark.deploy.worker.Worker to stop
上网查了一些资料,再翻看了一下stop-all.sh,stop-master.sh,stop-slaves.sh,spark-daemon.sh,spark-daemons.sh等脚本,发现很有可能是由于$SPARK_PID_DIR的一个环境变量导致。
我搭建的是Hadoop2.6.0+Spark1.1.0+Yarn的集群。Spark、Hadoop和Yarn的停止,都是通过一些xxx.pid文件来操作的。以spark的stop-master为例,其中停止语句如下:

再查看spark-daemon.sh中的操作:
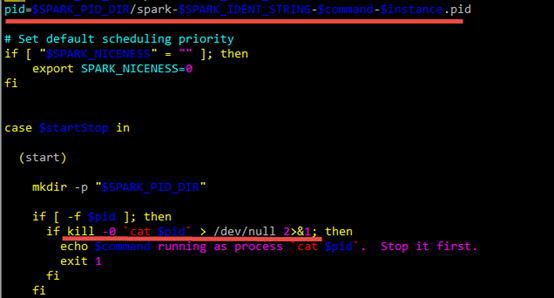
$SPARK_PID_DIR中存放的pid文件中,就是要停止进程的pid。其中$SPARK_PID_DIR默认是在系统的/tmp目录:
系统每隔一段时间就会清除/tmp目录下的内容。到/tmp下查看一下,果然没有相关进程的pid文件了。这才导致了stop-all.sh无法停止集群。
担心使用kill强制停止spark相关进程会破坏集群,因此考虑回复/tmp下的pid文件,再使用stop-all.sh来停止集群。
分析spark-daemon.sh脚本,看到pid文件命名规则如下:
pid=$SPARK_PID_DIR/spark-$SPARK_IDENT_STRING-$command-$instance.pid
其中
$SPARK_PID_DIR是/tmp
$SPARK_IDENT_STRING是登录用户$USER,我的集群中用户名是cdahdp
$command是调用spark-daemon.sh时的参数,有两个:
org.apache.spark.deploy.master.Master
org.apache.spark.deploy.worker.Worker
$instance也是调用spark-daemon.sh时的参数,我的集群中是1
因此pid文件名如下:
/tmp/spark-cdahdp-org.apache.spark.deploy.master.Master-1.pid
/tmp/spark-cdahdp-org.apache.spark.deploy.worker.Worker-1.pid
通过jps查看相关进程的pid:
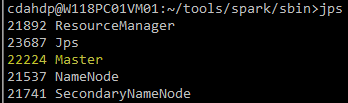
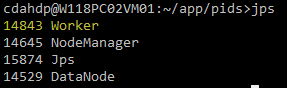
将pid保存到对应的pid文件即可。
之后调用spark的stop-all.sh,即可正常停止spark集群。
停止hadoop和yarn集群时,调用stop-all.sh,也会出现这个现象。其中NameNode,SecondaryNameNode,DataNode,NodeManager,ResourceManager等就是hadoop和yarn的相关进程,stop时由于找不到pid导致无法停止。分析方法同spark,对应pid文件名不同而已。
Hadoop的pid命名规则:
pid=$HADOOP_PID_DIR/hadoop-$HADOOP_IDENT_STRING-$command.pid
pid文件名:
/tmp/hadoop-cdahdp-namenode.pid
/tmp/hadoop-cdahdp-secondarynamenode.pid
/tmp/hadoop-cdahdp-datanode.pid
Yarn的pid命名规则:
pid=$YARN_PID_DIR/yarn-$YANR_IDENT_STRING-$command.pid
pid文件名:
/tmp/yarn-cdahdp-resourcemanager.pid
/tmp/yarn-cdahdp-nodemanager.pid
恢复这些pid文件即可使用stop-all.sh停止hadoop和yarn进程。

要根治这个问题,只需要在集群所有节点都设置$SPARK_PID_DIR, $HADOOP_PID_DIR和$YARN_PID_DIR即可。
修改hadoop-env.sh,增加:
export HADOOP_PID_DIR=/home/ap/cdahdp/app/pids
修改yarn-env.sh,增加:
export YARN_PID_DIR=/home/ap/cdahdp/app/pids
修改spark-env.sh,增加:
export SPARK_PID_DIR=/home/ap/cdahdp/app/pids
启动集群以后,查看/home/ap/cdahdp/app/pids目录,如下:

Spark集群无法停止的原因分析和解决的更多相关文章
- 解决Spark集群无法停止
执行stop-all.sh时,出现报错:no org.apache.spark.deploy.master.Master to stop,no org.apache.spark.deploy.work ...
- Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析
Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析 今天通过集群运行模式观察.研究和透彻的刨析SparkStreaming的日志和web监控台. Day28 ...
- Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续)
Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续) 今天延续昨天的内容,主要对为什么一个处理会分解成多个Job执行进行解析. 让我们跟踪下Job调用过 ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
- spark-2.2.0安装和部署——Spark集群学习日记
前言 在安装后hadoop之后,接下来需要安装的就是Spark. scala-2.11.7下载与安装 具体步骤参见上一篇博文 Spark下载 为了方便,我直接是进入到了/usr/local文件夹下面进 ...
- Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库.整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因. 发现: 集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫 ...
- Spark集群-Standalone 模式
Spark 集群相关 table td{ width: 15% } 来源于官方, 可以理解为是官方译文, 外加一点自己的理解. 版本是2.4.4 本篇文章涉及到: 集群概述 master, worke ...
随机推荐
- ajax接收flask传递的json数据
from flask import Flask, request import json app = Flask(__name__) @app.route('/') def func(): res = ...
- java 用Graphics制作模糊验证码
这篇随笔主要是java中制作验证码的效果,由于是在国庆前做的,现在也找不到原载了.我对自己整理的发表一份 生成的验证码效果如下: 一.建立一个工具类,用来生成验证码 package com.dkt.u ...
- cocos-creator 脚本逻辑-2
1.预制体 1)节点操作 Cc.find(‘node-1’) 获取节点 全局事件 作用于 canvas this.node.destroy() 删除节点(从内存中删除) 添加删除获取节点或组件 let ...
- iview框架下,modal内容过长,select选项位置不对
问题 modal组件中内容过长,超过一屏,有滚动条后,里面包含的select组件选项内容,位置会不对 解决 在使用select的时候添加transfer属性
- 鼠标移动事件(跟随鼠标移动的div)
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- 老生常谈:++a与a--区别
a++的作用是先对a进行操作再++:a--则相反. 如: int a = 1;int b = a++; //此时先运算b=a,再a++,故b=1,a=2int c = --a; //此时先--a,再运 ...
- Python语言下图像的操作方法总结
本章主要讲解 图像的读取方式.灰度化操作.图像转化为矩阵的方法 假设 strImgPath是图像的路径, img对象将图片读入到内存中 读取图像的第一种方式:skImage from skimage ...
- 抖音C#版,自己抓第三方抖音网站
感谢http://dy.lujianqiang.com技术支持 文章更新:http://dy.lujianqiang.com这个服务器已经关了,现在没用了 版权归抖音公司所有,该博客只是为交流学习所使 ...
- C++中long是什么类型
long long本质上还是整型,只不过是一种超长的整型. int型:32位整型,取值范围为-2^31 ~ (2^31 - 1) .long:在32位系统是32位整型,取值范围为-2^31 ~ (2^ ...
- arm汇编学习(四)
一.android jni实现1.静态实现jni:先由Java得到本地方法的声明,然后再通过JNI实现该声明方法.2.动态实现jni:先通过JNI重载JNI_OnLoad()实现本地方法,然后直接在J ...