sqlserver 分区表
我们知道很多事情都存在一个分治的思想,同样的道理我们也可以用到数据表上,当一个表很大很大的时候,我们就会想到将表拆
分成很多小表,查询的时候就到各个小表去查,最后进行汇总返回给调用方来加速我们的查询速度,当然切分可以使用横向切分,纵向
切分,比如我们最熟悉的订单表,通常会将三个月以外的订单放到历史订单表中,这里的三个月就是将订单表进行切分的依据。
好了,分区表的好处我想大家都很清楚了,下面我们看看如何实现。
一:分区表
这里我们做个例子,创建一个test数据库,表名为shop,以createtime作为分区依据。
1:确定分区依据
怎么分区的话,这个要看具体业务逻辑了,你可以按照时间,地区,求模等等都可以。
2:创建文件组
既然是文件组,肯定是对文件进行分类管理的,默认情况下就一个mdf和ldf文件,当所有的数据都挤压在mdf上,确实不是一个
很好的事情,降低我们的查询速度,当用到文件组的时候就可以创建多个ndf来分摊mdf中的数据,甚至还可以将ndf分摊到几个磁盘
上,充分利用服务器多核处理能力,说了这么多,我们看看sql语句咋搞,这里我创建四个文件组,分别存放2013之前,2013,2014
和2014年之后的数据。
1 alter database Test add filegroup Before2013
2 alter database Test add filegroup T2013
3 alter database Test add filegroup T2014
4 alter database Test add filegroup After2014
3:创建文件
根据上面在文件组上的概述,文件的作用大家都知道了,这里我们要做的是,将次文件.ndf附加到文件组上,因为我创建了4个文件组,
所以我也创建4个文件分别存放在这4个文件组中。

1 alter database Test add file
2 (Name=N'Before2013',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\Before20131.ndf',size=5mb,maxsize=100Mb,filegrowth=5mb)
3 to filegroup Before2013
4 alter database Test add file
5 (Name=N'T2013',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\T20131.ndf',size=5mb,maxsize=100Mb,filegrowth=5mb)
6 to filegroup T2013
7 alter database Test add file
8 (Name=N'T2014',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\T20141.ndf',size=5mb,maxsize=100Mb,filegrowth=5mb)
9 to filegroup T2014
10 alter database Test add file
11 (Name=N'After2014',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\After20141.ndf',size=5mb,maxsize=100Mb,filegrowth=5mb)
12 to filegroup After2014
4:编写分区函数
刚才也说了,我们是按照时间进行切分的,将数据表数据分成:
① 2013年之前
② 2013-2014
③ 2014-2015
④ 2015之后
既然都知道依据了,我们分区函数也方便写了。
1 create partition function RangeTime (datetime)
2 as range left for values ('2012-12-31','2013-12-31','2014-12-31')
从上面的sql,我们可以看到三个点将时间轴分成了4段
第一:rangeTime 为分组函数名。
第二:left 其实就是当时间点在边界时到底属于左侧还是右侧,因为这里是left,所以属于左侧,如果是right关键词,那就属于右侧了。
5:编写分区方案
分区方案也就是将分区函数与文件组进行一个关联,刚才也说了,3个时间点将一个时间轴分成了4部分,刚好对应了4个文件组。
那么具体的sql写法如下:
1 create partition scheme RangeSchema_CreateTime
2 as partition RangeTime
3 to (before2013,T2013,T2014,after2014)
6:创建分区表
跟普通表创建有点不一样,分区表的创建还需要指定这个分区需要使用哪个分区方案下的分区字段,那么这里就是RangeSchema_CreateTime
中的CreateTime字段。
1 create table Shop
2 (
3 ID varchar(50),
4 ShopName varchar(50),
5 CreateTime datetime
6 ) on RangeSchema_CreateTime(CreateTime)
这里要注意,如果在创建表的时候指定了ID为主键的话,这个时候需要指定ID为分区字段,否则会报错的。
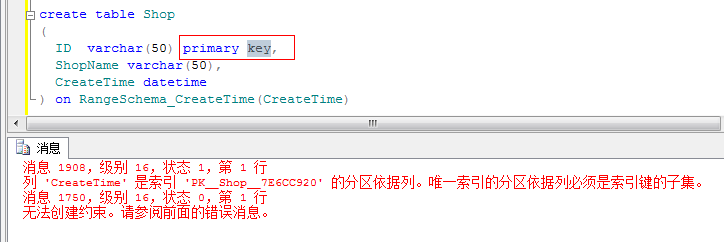
这时候可以在不要主键的情况下先创建表,然后再指定ID为主键。

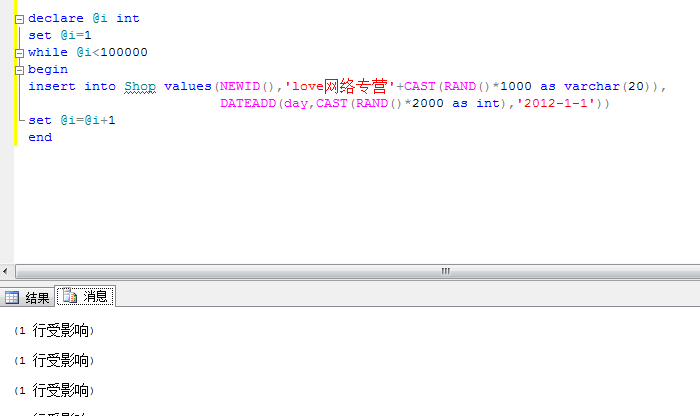
7:插入测试数据并统计
这里我先插入10w条数据,然后来看看数据在各个分区的情况。‘
<1>插入数据
<2> 统计每个分区的数据量
这里主要有一个查询分区的关键字“$partition”,非常的有用。
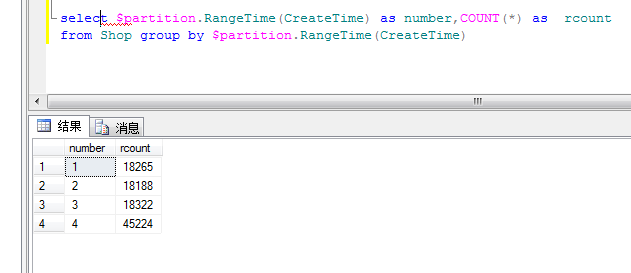
好了,到这个我们通过sql语句来实现分区表就已经完成了。
二:使用管理界面创建分区表
1:首先我们创建test1数据库和shop表
2:创建文件组和文件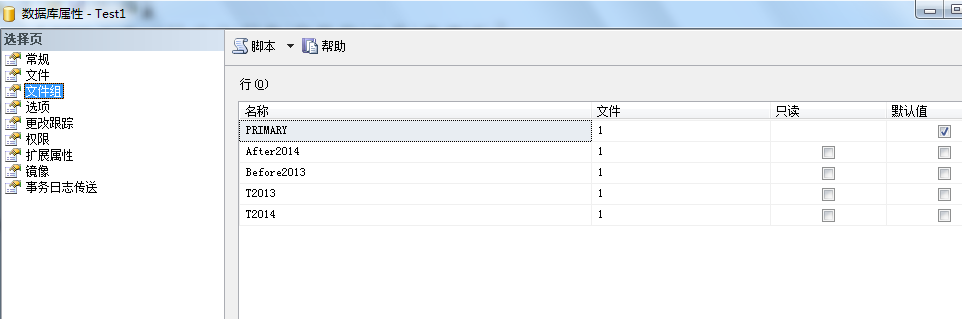
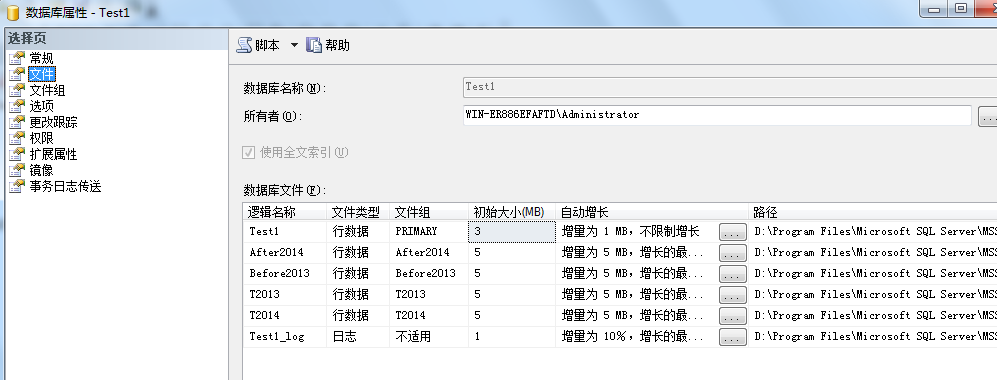
3:创建分区
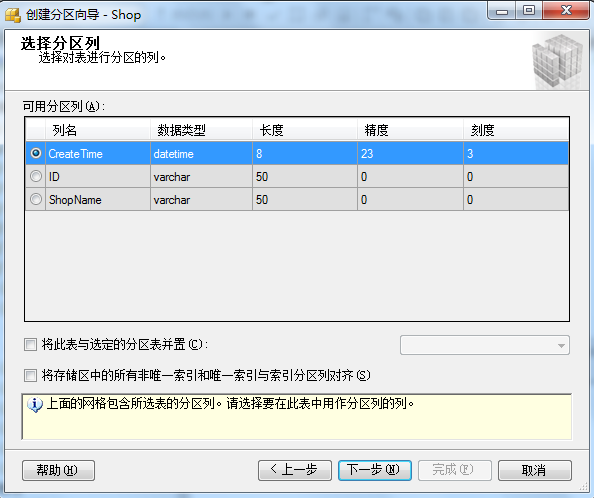
①:右键Shop表,弹出菜单中选择 “存储” => "创建分区"
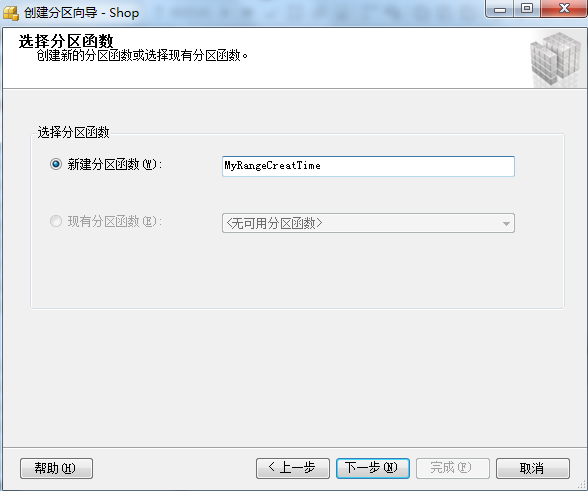
②:创建“分区函数”名 和 “分区方案”名。

③:创建分区映射,也就是将”分区函数“和“文件组”进行关联。
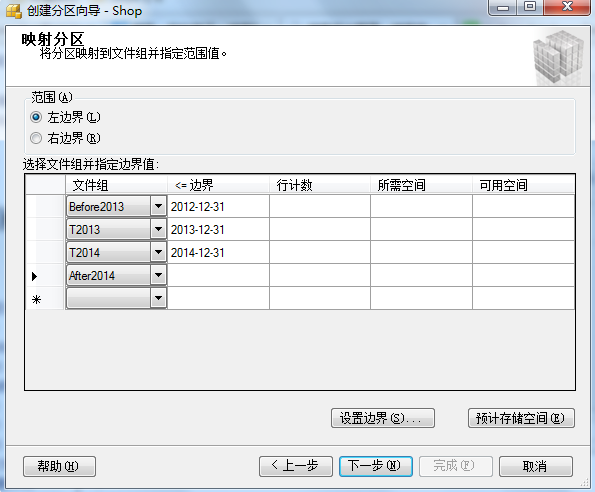
④: 最后我们可以看一下界面给我生成的分区函数以及分区方案,蛮有意思的。
1 USE [Test1]
2 GO
3 BEGIN TRANSACTION
4 CREATE PARTITION FUNCTION [MyRangeCreatTime](datetime) AS RANGE LEFT FOR VALUES (N'2012-12-31T00:00:00', N'2013-12-31T00:00:00', N'2014-12-31T00:00:00')
5
6
7 CREATE PARTITION SCHEME [MySchemeCreateTime] AS PARTITION [MyRangeCreatTime] TO ([Before2013], [T2013], [T2014], [After2014])
8
9
10 ALTER TABLE [dbo].[Shop] DROP CONSTRAINT [PK__Shop__3214EC277F60ED59]
11
12
13 ALTER TABLE [dbo].[Shop] ADD PRIMARY KEY NONCLUSTERED
14 (
15 [ID] ASC
16 )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
17
18
19 CREATE CLUSTERED INDEX [ClusteredIndex_on_MySchemeCreateTime_635288828144372217] ON [dbo].[Shop]
20 (
21 [CreateTime]
22 )WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [MySchemeCreateTime]([CreateTime])
23
24
25 DROP INDEX [ClusteredIndex_on_MySchemeCreateTime_635288828144372217] ON [dbo].[Shop] WITH ( ONLINE = OFF )
26
27
28
29
30 COMMIT TRANSACTION
sqlserver 分区表的更多相关文章
- sqlserver分区表实践:对时间分区表自动进行管理
项目问题:有一张日志表,插入和查询为主,每天记录数据为200多万,大小为2G-4G之间.一开始开发人员使用delete语句手动删除,保留7天数据,经常造成阻塞和性能瓶颈.但是如果不删除数据随着表越来越 ...
- SqlServer分区表概述(转载)
什么是分区表 一般情况下,我们建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在 ...
- (转)SQLServer分区表操作
原文地址:https://www.cnblogs.com/libingql/p/4087598.html 1. 分区表简介 分区表在逻辑上是一个表,而物理上是多个表.从用户角度来看,分区表和普通表是一 ...
- Sqlserver分区表
1. 分区表简介 分区表在逻辑上是一个表,而物理上是多个表.从用户角度来看,分区表和普通表是一样的.使用分区表的主要目的是为改善大型表以及具有多个访问模式的表的可伸缩性和可管理性. 分区表是把数据按设 ...
- SQLSERVER 分区表实战
背景:对NEWISS数据库创建分区表T_SALES的SQL.按照日期来进行分区步骤:1:创建文件组2:创建数据文件3:创建分区函数4:创建分区方案5:创建表及聚集索引6:导入测试数据(此处略),并查询 ...
- sqlserver分区表索引
对于提高查询性能非常有效,因此,一般应该考虑应该考虑为分区表建立索引,为分区表建立索引与为普通表建立索引的语法一直,但是,其行为与普通索引有所差异. 默认情况下,分区表中创建的索引使用与分区表相同分区 ...
- 使用SQL-Server分区表功能提高数据库的读写性能
首先祝大家新年快乐,身体健康,万事如意. 一般来说一个系统最先出现瓶颈的点很可能是数据库.比如我们的生产系统并发量很高在跑一段时间后,数据库中某些表的数据量会越来越大.海量的数据会严重影响数据库的读写 ...
- sqlserver DBA面试题
1.sqlserver 2008 R2 on windows server 2008 R2群集中,有节点A.B,现在需要停机新添加一个节点C进来替换现有节点B,请列出必要的步骤. 2.sqlserve ...
- 一步一步在Windows中使用MyCat负载均衡
一步一步在Windows中使用MyCat负载均衡 http://www.cnblogs.com/zhangs1986/p/6408981.html mycat+sqlServer简单demo配置 ...
随机推荐
- MySQL日志恢复误删记录
1.查询日志是否开启 show variables like"log_"; 2.查询是用的哪个日志文件 show master status; 3.定位是在什么时间误删的 /usr ...
- vim(5)vim下wimrc的配置,解决中文乱码问题
解决linux下vim乱码的情况:(修改vimrc的内容) 全局的情况下:即所有用户都能用这个配置 文件地址:/etc/vimrc 在文件中添加: ,ucs-bom,gb18030,gbk,gb231 ...
- iOS 手写输入法奔溃,替换隐藏键盘方法
{ UITapGestureRecognizer *tapGestureRecognizer = [[UITapGestureRecognizer alloc] initWithTarget:se ...
- bootstrap-面板、modal
面板: <!-- panel 面板 panel-heading 面板头部 panel-title 面板标题样式 panel-body 面板内容 --> <div class=&quo ...
- (String) 205.Isomorphic Strings
Given two strings s and t, determine if they are isomorphic. Two strings are isomorphic if the chara ...
- Nginx作为负载均衡服务器(Windows环境)
一个最简单的负载均衡测试,不涉及到session复制,只是将请求分配到不同的服务器上去而已. 1.创建一个简单的web应用.只有一个index.jsp页面,,内容如下. <%@ page lan ...
- 设置arc/非arc
1,选择项目中的Targets,选中你所要操作的Target,2,选Build Phases,在其中Complie Sources中选择需要ARC的文件双击, 并在输入框中输入:-fobjc- ...
- shutdown immediate时 hang住 (转载)
shutdown immediate 经常关库时hang住,在alert中有 License high water mark = 4All dispatchers and shared servers ...
- JAVA设计模式之享元模式
在阎宏博士的<JAVA与模式>一书中开头是这样描述享元(Flyweight)模式的: Flyweight在拳击比赛中指最轻量级,即“蝇量级”或“雨量级”,这里选择使用“享元模式”的意译,是 ...
- I2C控制器的Verilog建模之一
前言:之前申请了ADI公司的一款ADV7181CBSTZ的视频解码芯片,正好原装DE2板子安的是同系列的ADV7181BBSTZ.虽然都是ADV7181的宗出,但是寄存器配置等等还是有些诧异,引脚也不 ...