MySQL8:连接查询
连接查询
连接是关系型数据库模型的主要特点。
连接查询是关系型数据库中最主要的查询,主要包括内连接、外连接等通过联结运算符可以实现多个表查询。
在关系型数据库管理系统中,表建立时各种数据之间的关系不必确定,常把一个实体的所有信息存放在一个表中,当查询数据时通过连接操作查询出存放在多个表中的不同实体信息,当两个或多个表中存在相同意义的字段时,便可以通过这些字段对不同的表进行连接查询。
本文将介绍多表之间的内连接查询、外连接查询。
创建测试数据
为了后面可以演示内连接、外连接中的左外连接和右外连接,下面创建一些测试数据,首先创建一张base_worker表,用于存放工人基本信息:
create table base_worker
(
s_id int auto_increment,
s_name varchar(20),
s_age int,
primary key(s_id)
)engine=innodb, charset=utf8; insert into base_worker values(null, "aaa", 20);
insert into base_worker values(null, "bbb", 21);
insert into base_worker values(null, "ccc", 22);
commit;
然后创建一张extra_worker表,用于存放工人额外信息:
create table extra_worker
(
e_id int auto_increment,
s_id int,
s_nation varchar(20),
s_phone varchar(30),
primary key(e_id)
)engine=innodb, charset=utf8; insert into extra_worker values(null, 1, "中国", "00000000");
insert into extra_worker values(null, 2, "美国", "11111111");
insert into extra_worker values(null, 5, "英国", "22222222");
commit;
两张表之间通过s_id相关联,当然这里没有设置外键,因为我不太喜欢使用外键,一个是语法太麻烦了,另一个是外键的关联关系太死了,外键不存在插入会报错,还得重新定位问题。
内连接inner join
内连接(inner join)使用比较运算符进行表间某(些)列数据的比较操作,并列出这些表中与连接条件相匹配的数据行,组合成新的记录。换句话说,在内连接查询中,只有满足条件的记录才能出现在结果关系中。
对base_worker和extra_worker使用内连接:
select b.s_id, b.s_name, b.s_age, e.s_nation, e.s_phone from
base_worker b, extra_worker e where b.s_id = e.s_id;
看一下查询结果:
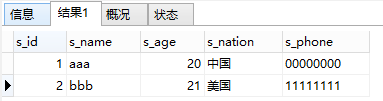
看到base_worker和extra_worker中分别有三条记录,但是最终查询出来只有两条记录,因为只有这两条记录可以通过s_id相匹配上。
另外一个细节点是,s_id这种在两张表中都存在的字段,必须指明读取的是哪张表中的s_id,否则SQL将报错,但是s_name这种只在base_worker表中存在的字段则没有这个限制。
最后,上面的SQL是内连接最常用的SQL写法,内连接还有另外一种SQL写法,结果也是一样的:
select b.s_id, b.s_name, b.s_age, e.s_nation, e.s_phone from
base_worker b inner join extra_worker e on b.s_id = e.s_id;
可以自己验证一下,执行效率上也没有什么差别。
左外连接left join
连接查询将查询多个表中相关联的行,内连接时返回查询结果集合中的仅仅是符合查询条件和连接条件的行。但有时候需要包含没有关联的行中的数据,即返回查询结果集合中的不仅仅包含符合的连接条件的行,而且还包含左表或右表中的所有数据行。外连接分为左外连接和右外连接,这里先看一下左外连接。
左外连接,返回的是左表中的所有记录以及由表中连接字段相等的记录。
看一下SQL:
select b.s_id, b.s_name, b.s_age, e.s_nation, e.s_phone from
base_worker b left outer join extra_worker e on b.s_id = e.s_id;
看一下查询结果:
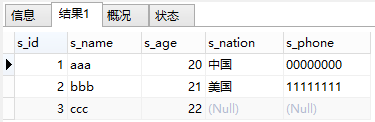
显示了三条纪录,s_id为3的记录在extra_worker表中并没有s_nation与s_phone,所以这两个值为null,但因为base_worker为左表,因此base_worker中的所有数据都会被查出来。
右外连接right join
右外连接是左外连接的反向连接,将返回右表中的所有行,如果右表中的某行在左表中没有匹配的行,左表将返回空值。
看一下SQL:
select e.s_id, b.s_name, b.s_age, e.s_nation, e.s_phone from
base_worker b right outer join extra_worker e on b.s_id = e.s_id;
注意一下,这里的s_id是extra_worker的而不是base_worker的。
看一下查询结果:
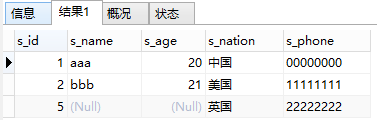
同样的,看到显示了三条纪录,s_id为5的记录在base_worker中并没有s_name与s_age,所以这两个值为null,但因为extra_worker表为右表,因此extra_worker表中的所有数据都会被查出来。
MySQL8:连接查询的更多相关文章
- SQL多表连接查询(详细实例)
转载博客:joeleo博客(http://www.xker.com/page/e2012/0708/117368.html) 本文主要列举两张和三张表来讲述多表连接查询. 新建两张表: 表1:stud ...
- Mysql联合,连接查询
一. 联合查询 UNION, INTERSECT, EXCEPT UNION运算符可以将两个或两个以上Select语句的查询结果集合合并成一个结果集合显示,即执行联合查询.UNION的语法格式为 ...
- Oracle学习笔记五 SQL命令(三):Group by、排序、连接查询、子查询、分页
GROUP BY和HAVING子句 GROUP BY子句 用于将信息划分为更小的组每一组行返回针对该组的单个结果 --统计每个部门的人数: Select count(*) from emp group ...
- SQL多表连接查询
SQL多表连接查询 本文主要列举两张和三张表来讲述多表连接查询. 新建两张表: 表1:student 截图如下: 表2:course 截图如下: (此时这样建表只是为了演示连接SQL语句,当然实际 ...
- mysql的查询、子查询及连接查询
>>>>>>>>>> 一.mysql查询的五种子句 where(条件查询).having(筛选).group by(分组). ...
- oracle(sql)基础篇系列(二)——多表连接查询、子查询、视图
多表连接查询 内连接(inner join) 目的:将多张表中能通过链接谓词或者链接运算符连接起来的数据查询出来. 等值连接(join...on(...=...)) --选出雇员的名字和雇员所 ...
- Sql Server系列:多表连接查询
连接查询是关系数据中最主要的查询,包括内连接.外连接等.通过连接运算符可以实现多个表查询.内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值.SQL Server中的内连接有 ...
- SubSonic3.0使用外连接查询时查询不出数据的问题修改
今天在开发时,要使用到外连接查询,如图 老是查不出数据,所以就追踪了一下代码,发现查询后生成的SQL语句变成了内连接了,真是晕 然后继续Debug,发现原来SqlQuery类在调用LeftInnerJ ...
- Access数据库多表连接查询
第一次在Access中写多表查询,就按照MS数据库中的写法,结果报语法错,原来Access的多表连接查询是不一样的 表A.B.C,A关联B,B关联C,均用ID键关联 一般写法:select * fro ...
随机推荐
- DailyTick 开发实录 —— 开始
2009 年我读了李笑来老师的<把时间当朋友>,知识了柳比歇夫的时间记录法.当时激动坏了,马上动手实践起来.一开始的时候,是用一个小本子,走到哪儿都带着.完成一件事,就记录一下花费的时间. ...
- 浅谈我对DDD领域驱动设计的理解
从遇到问题开始 当人们要做一个软件系统时,一般总是因为遇到了什么问题,然后希望通过一个软件系统来解决. 比如,我是一家企业,然后我觉得我现在线下销售自己的产品还不够,我希望能够在线上也能销售自己的产品 ...
- [NodeJS] 优缺点及适用场景讨论
概述: NodeJS宣称其目标是“旨在提供一种简单的构建可伸缩网络程序的方法”,那么它的出现是为了解决什么问题呢,它有什么优缺点以及它适用于什么场景呢? 本文就个人使用经验对这些问题进行探讨. 一. ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(63)-Excel导入和导出-自定义表模导入
系列目录 前言 上一节使用了LinqToExcel和CloseXML对Excel表进行导入和导出的简单操作,大家可以跳转到上一节查看: ASP.NET MVC5+EF6+EasyUI 后台管理系统(6 ...
- [.NET] 打造一个很简单的文档转换器 - 使用组件 Spire.Office
打造一个很简单的文档转换器 - 使用组件 Spire.Office [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/6024827.html 序 之前,& ...
- XML技术之DOM4J解析器
由于DOM技术的解析,存在很多缺陷,比如内存溢出,解析速度慢等问题,所以就出现了DOM4J解析技术,DOM4J技术的出现大大改进了DOM解析技术的缺陷. 使用DOM4J技术解析XML文件的步骤? pu ...
- Nginx学习笔记--001-Nginx快速搭建
Nginx ("engine x") 是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器.Nginx是由Igor Sysoev为俄罗斯访问量第二的R ...
- 5.2 Array类型的方法汇总
所有对象都具有toString(),toLocaleString(),valueOf()方法. 1.数组转化为字符串 toString(),toLocaleString() ,数组调用这些方法,则返回 ...
- Android中的flexboxlayout布局
提到FlexboxLayout大家估计有点模糊,它是谷歌最近开源的一个android排版库,它的前身Flexbox是2009年W3C提出了一种新的布局,可以简便.完整.响应式的实现页面布局,Flexb ...
- git提交项目到已存在的远程分支
今天想提交项目到github的远程分支上,那个远程分支是之前就创建好的,而我的本地关联分支还没创建. 之前从未用github提交到远程分支过,弄了半个钟,看了几篇博文,终于折腾出来.现在把步骤整理 ...