python+selenium+unittest,爬虫电影网站
以前经常在这个网站上下载电影下来看,这个网站比较坑的就是,主页上只有电影的名称,但是评分是看不到的;只有再点击电影名字,进入电影主页时才能看到评分。一般下载的电影都是评分高的才看,低的就忽略掉了。每次都要来回去看评分,太麻烦了。So,我就写了一个小小的爬虫,暂时就叫爬虫好了。
在脚本中使用的是:python2.7 + selenium + unittest + chrome(其实我想用phantomjs的,但是在抓取评分的时候,老是抓取不到,好像是js搞的鬼)
其实流程很简单:1、进入主页获取电影的title和url,2、根据获取的url,获取该电影的评分score,3、保存结果到本地文件中
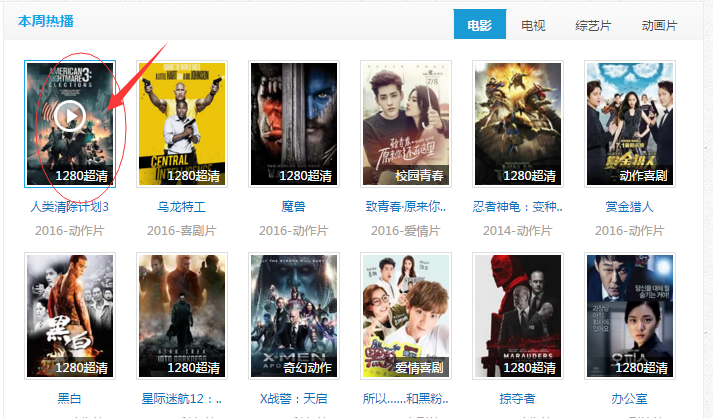
1、进入主页获取电影的title和url
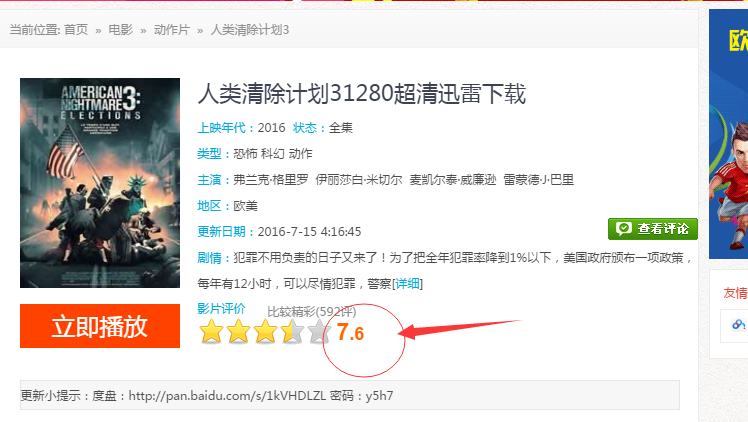
2、根据获取的url,获取该电影的评分score
下面我就逐步分解:
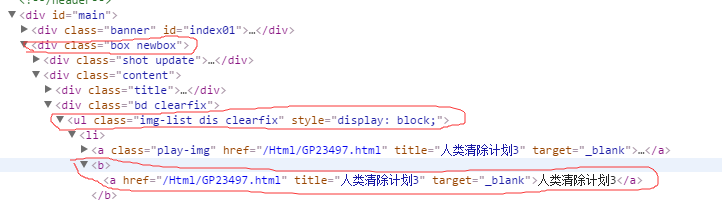
首先,进入该网站的主页,利用webdriver来定位电影,然后获取所有电影的属性:title,url,使用的定位是css
def geturl(self): # 该函数是获取首页的电影的 title 和 url
self.dr.get('http://www.xiamp4.com') # 网站首页
urls = [] # 存放结果的list
eles = self.dr.find_elements_by_css_selector('div.box.newbox ul.img-list.dis.clearfix b a') # 定位满足条件的所有电影,css定位
for ele in eles:
tmp = dict()
url = ele.get_attribute('href') # 获取电影的url
title = ele.get_attribute('title') # 获取电影的title
tmp['url'] = url
tmp['title'] = title
urls.append(tmp) # 将电影的title和url放在一个字典中,然后添加到 urls中
return urls
2、根据获取的url,获取该电影的评分score

def getscore(self, url):
# url = 'http://www.xiamp4.com/Html/GP23161.html'
self.dr.get(url) # 进入电影的页面
time.sleep(2)
ele = self.dr.find_element_by_css_selector('input#MARK_B2') # 定位评分的元素
score = ele.get_attribute('value') # 获取元素value的值
# print score
return score # 该函数的左右就是 根据参数电影的url,返回该电影的评分
下面是最终的代码:
#coding=utf-8 from selenium import webdriver
import unittest
import time class Spider(unittest.TestCase):
def setUp(self):
print '####################### Start #######################'
self.dr = webdriver.Chrome()
self.dr.implicitly_wait(10) def tearDown(self):
self.dr.close()
print '####################### End #######################' def geturl(self):
self.dr.get('http://www.xiamp4.com')
urls = []
eles = self.dr.find_elements_by_css_selector('div.box.newbox ul.img-list.dis.clearfix b a')
for ele in eles:
tmp = dict()
url = ele.get_attribute('href')
title = ele.get_attribute('title')
tmp['url'] = url
tmp['title'] = title
urls.append(tmp)
return urls def getscore(self, url):
# url = 'http://www.xiamp4.com/Html/GP23161.html'
self.dr.get(url)
time.sleep(2)
ele = self.dr.find_element_by_css_selector('input#MARK_B2')
score = ele.get_attribute('value')
# print score
return score def test_run(self):
moves = self.geturl()
# print len(moves)
for move in moves:
move['score'] = self.getscore(move['url'])
try:
if len(moves) > 0:
with open('MoveMessage.txt', 'a') as f:
f.write('####################### Start #######################' + '\n')
for move in moves:
tmp = 'MoveName: %s\t,MoveScore: %s\t,MoveUrl: %s' % (move['title'],move['score'],move['url'])
print tmp
with open('MoveMessage.txt', 'a') as f:
f.write(tmp.encode('utf-8') + '\n')
with open('MoveMessage.txt', 'a') as f:
f.write('####################### End #######################' + '\n')
except Exception,e:
print 'Not found moves!',e if __name__ == '__main__':
unittest.main()
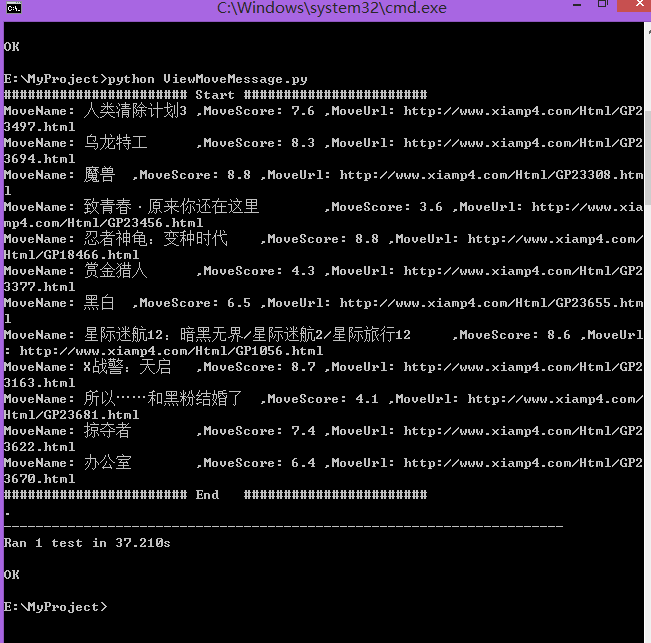
运行的最终结果:

python+selenium+unittest,爬虫电影网站的更多相关文章
- Python+selenium+unittest+HTMLTestReportCN单元测试框架分享
分享一个比较基础的,系统性的知识点.Python+selenium+unittest+HTMLTestReportCN单元测试框架分享 Unittest简介 unittest是Python语言的单元测 ...
- Python+Selenium+Unittest+Ddt+HTMLReport分布式数据驱动自动化测试框架结构
1.Business:公共业务模块,如登录模块,可以把登录模块进行封装供调用 ------login_business.py from Page_Object.Common_Page.login_pa ...
- python+selenium +unittest生成HTML测试报告
python+selenium+HTMLTestRunner+unittest生成HTML测试报告 首先要准备HTMLTestRunner文件,官网的HTMLTestRunner是python2语法写 ...
- 【爬虫】如何用python+selenium网页爬虫
一.前提 爬虫网页(只是演示,切勿频繁请求):https://www.kaola.com/ 需要的知识:Python,selenium 库,PyQuery 参考网站:https://selenium- ...
- Python Selenium unittest+HTMLTestRunner实现 自动化测试及发送测试报告邮件
1.UI测试框架搭建-目录结构 2. 文件介绍 2.1.baseinfo->__init__.py 配置文件定义基础参数 #-*-coding:utf-8-*- #测试用例配置参数 base_u ...
- python selenium --unittest 框架
转自:http://www.cnblogs.com/fnng/p/3300788.html 学习unittest 很好的一个切入点就是从selenium IDE 录制导出脚本.相信不少新手学习sele ...
- python + selenium + unittest 自动化测试框架 -- 入门篇
. 预置条件: 1. python已安装 2. pycharm已安装 3. selenium已安装 4. chrome.driver 驱动已下载 二.工程建立 1. New Project:建立自己的 ...
- Python+Selenium ----unittest单元测试框架
unittest是一个单元测试框架,是Python编程的单元测试框架.有时候,也做叫做“PyUnit”,是Junit的Python语言版本.这里了解下,Junit是Java语言的单元测试框架,Java ...
- windiows下搭建python+selenium+unittest+Chrome的Web自动化环境
一.selenium.unittest概念 Selenium 是用于测试 Web 应用程序用户界面 (UI) 的常用框架.它是一款用于运行端到端功能测试的超强工具.您可以使用多个编程语言编写测试,并且 ...
随机推荐
- EF性能之关联加载
鱼和熊掌不能兼得 ——中国谚语 一.介绍 Entity Framework作为一个优秀的ORM框架,它使得操作数据库就像操作内存中的数据一样,但是这种抽象是有性能代价的,故鱼和熊掌不能兼得.但是,通过 ...
- 【转】javascript运行机制之this详解
this是面向对象语言中一个重要的关键字,理解并掌握该关键字的使用对于我们代码的健壮性及优美性至关重要.而javascript的this又有区别于Java.C#等纯面向对象的语言,这使得this更加扑 ...
- C# 汉字转拼音 使用微软的Visual Studio International Pack 类库提取汉字拼音首字母
代码参考该文http://www.cnblogs.com/yazdao/archive/2011/06/04/2072488.html VS2015版本 1.使用Nuget 安装 "Simp ...
- Java关键字--static
在Java中,将关键字static分为三部分进行讨论,分别为Java静态变量.Java静态方法.Java静态类 Java Static Variables Java instance variable ...
- 单元测试mock之mockito使用
先来一个简单的例子来感受一下 外部接口类:TestService.java package com.yzl.mock; /** * 测试用服务 * * @author yangzhilong */ p ...
- 【css】a:hover 设置上下边框在 ie6 和 ie7 下失效
前段时间在写样式的时候发现了这个问题,虽然当时就解决了这个 bug 不过还是记录下,以免再次出现这样的问题. demo 代码: <!doctype html> <html lang= ...
- pod 出错备忘
pod install #输出信息 /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/rubygems ...
- datagridview设置currentrow为指定的某一行[转]
最近由于程序需要,需要实现指定的行为datagridview的currentrow ,当我设置 dataGridView1.Rows[i].Selected = true时,刷新后,界面显示是当前行被 ...
- 通过PowerShell获取TCP响应(类Telnet)
通常情况下,为了检测指定的TCP端口是否存活,我们都是通过telnet指定的端口看是否有响应来确定,然而默认情况下win8以后的系统默认是不安装telnet的.设想一下如果你黑进了一个服务器,上面没装 ...
- U-boot.lds文件分析
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm") ...