Why Apache Beam? A data Artisans perspective
https://cloud.google.com/dataflow/blog/dataflow-beam-and-spark-comparison
https://github.com/apache/incubator-beam
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102
http://data-artisans.com/why-apache-beam/
As the Dataflow SDK and the Runners were moving to Apache Incubator as Apache Beam, we were asked by Google to bring the Flink runner into the codebase of Beam, and become committers and PMC members in the new project. We decided to go full st(r)eam ahead with this opportunity as we believe that
(1) the Beam model is the future reference programming model for writing data applications in both stream and batch, and
(2) Flink is the definitive platform to execute these data applications. As Beam is now taking shape, Flink is currently the only practical execution engine for Beam programs outside Google’s Cloud.
Beam包括,SDK部分和runner部分,而在Google外,当前Flink是一个可以作为runner的比较好的选择
Flink and Beam are completely aligned in their concepts, which makes the translation of Beam programs to Flink jobs both straightforward and very efficient.
With full support for concepts such as event time, watermarks, and triggers, and with the new features we are contributing to Flink, we believe that the superiority of the Flink runner will stick for the foreseeable future.
Flink和beam的设计和概念都很相似,所以从Beam programs翻译到Flink jobs 是非常直接的。
One question that remains is what is the relationship between Flink’s own native API (DataStream), and the Beam API?
Will both of these continue to be supported, and is it confusing for developers to have two different APIs that in the end generate Flink jobs?
Our committers at data Artisans will continue to fully support both the Flink DataStream API (which is, as of Flink 1.0, stable and backwards compatible), as well as the Beam API as it evolves for Beam programs that run on Flink.
The differences between the two APIs are largely syntactical (and a matter of taste), and, we are working together with Google towards unifying the APIs, with the end goal of making the Beam and Flink APIs source compatible.
We believe that the two communities can learn from each other, and we encourage users to use either of the two APIs to implement their Flink jobs for stream data processing.
With the native Flink DataStream API you get an already mature and backwards-compatible API, built-in libraries (e.g., CEP and upcoming SQL), mature tooling and connectors, key-value state (with the ability to query that state in the future), and an API which fully utilizes all the features of Flink’s powerful engine.
With the Beam API, you get the option of portability down the line as more Beam runners mature.
Flink API和Beam API的区别是什么?
区别主要是语法上的,并且会致力于unify两种接口,但两种接口会都有其存在的价值
API, model, and engine
To clarify our points above, we would like to explain what we mean by choice of API, choice of programming model, and choice of execution engine.
Currently, Beam has three available runners: the Google Cloud Dataflow proprietary runner by Google, as well as the Flink and Spark runners, included in the open source Apache Beam project. Let us look at this ecosystem, and add Flink and Spark themselves with their native APIs, as well as Storm:
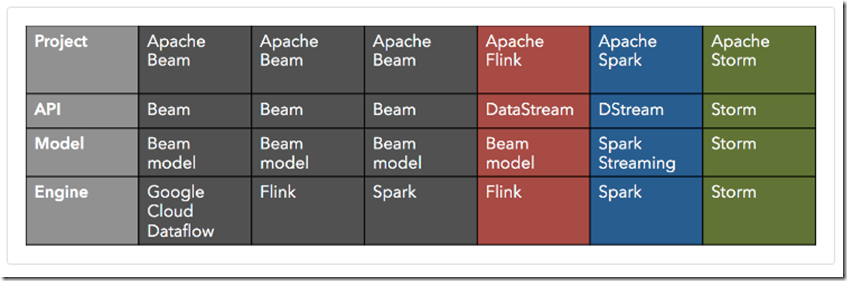
可以看出Beam的好处,关键在于,API和Model的统一,虽然Engine可以是不一样的
Even more, Google and data Artisans are working together to make the two APIs semantically equivalent, ironing out any minor inconsistencies.
This means that users of either API can switch with relatively low effort.
Our long term goal is to make the Beam and Flink DataStream APIs source-compatible, so that programs written in one can natively run on the other with no code changes.
If you choose to invest in the Beam programming model now, you have two options:
- Use the Flink DataStream API in Java and Scala
- Use the Beam API directly in Java (and soon Python) with the Flink runner
长期看, Beam和Flink的API会兼容,所以如果想用Beam编程模型,可以有两种选择,直接用Flink DataStream API或用Beam API加上Flink Runner
We recommend option 1 to users that want to get started immediately, using an already mature and backwards-compatible API, access to libraries (e.g., the existing CEP library and the upcoming SQL functionality), mature tooling and connectors (e.g., to Kafka), as well as an API that fully and natively utilizes all the existing and upcoming features of the Flink engine. In addition, we recommend the Flink native API for use cases that use Flink’s key-value state abstraction, and in the future Flink’s facilities for querying that state.
We recommend option 2 to users that want to keep the option of engine portability (as other Beam runners progress).
选择BeamAPI的唯一好处是,可以做到各个runner的兼容;而显然,Flink的API更丰富和成熟
In a recent blog post, Google compared Beam and Spark Streaming from a programming model perspective. They took a mobile gaming scenario, and implemented several use cases in Beam and Spark Streaming, focusing their analysis on how well are the following concerns separated in the code:
- What results are calculated? Sums, joins, histograms, machine learning models?
- Where in event time are results calculated? Does the time each event originally occurred affect results? Are results aggregated in fixed windows, sessions, or a single global window?
- When in processing time are results materialized? Does the time each event is observed within the system affect results? When are results emitted? Speculatively, as data evolve? When data arrive late and results must be revised? Some combination of these?
- How do refinements of results relate? If additional data arrive and results change, are they independent and distinct, do they build upon one another, etc.?
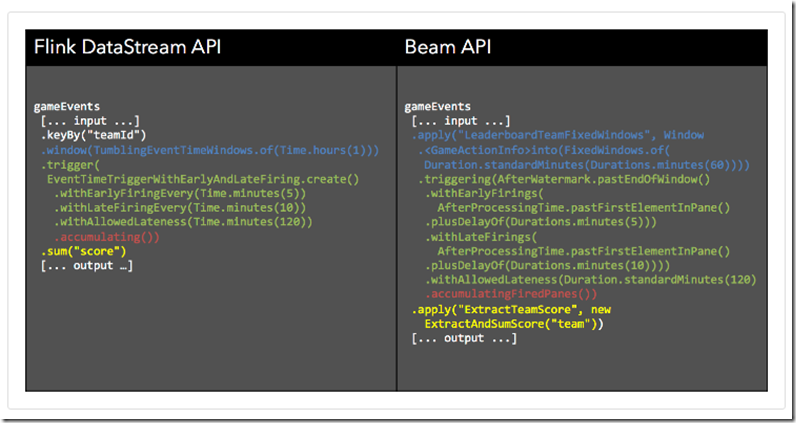
用一个实际例子比较一下,Flink和Beam API的不同,不同颜色部分解决不同的问题,一共4个问题
Conclusion
We firmly believe that the Beam model is the correct programming model for streaming and batch data processing.
We encourage users to adopt this model for their future data applications, embodied in either the Beam API itself or the Flink DataStream API.
Further, we believe that Flink, with its current features and roadmap, is currently the most advanced open source stream processor, and at the same time the only practical solution for deploying Beam programs in production on on-premise or non-GCP clusters. We are looking forward to continue pushing the envelope in stream processing and enabling enterprises to use stream processing technology for their data applications.
Why Apache Beam? A data Artisans perspective的更多相关文章
- beam 的异常处理 Error Handling Elements in Apache Beam Pipelines
Error Handling Elements in Apache Beam Pipelines Vallery LanceyFollow Mar 15 I have noticed a defici ...
- Apache Beam编程指南
术语 Apache Beam:谷歌开源的统一批处理和流处理的编程模型和SDK. Beam: Apache Beam开源工程的简写 Beam SDK: Beam开发工具包 **Beam Java SDK ...
- Apache Beam是什么?
Apache Beam 的前世今生 1月10日,Apache软件基金会宣布,Apache Beam成功孵化,成为该基金会的一个新的顶级项目,基于Apache V2许可证开源. 2003年,谷歌发布了著 ...
- Beam编程系列之Apache Beam WordCount Examples(MinimalWordCount example、WordCount example、Debugging WordCount example、WindowedWordCount example)(官网的推荐步骤)
不多说,直接上干货! https://beam.apache.org/get-started/wordcount-example/ 来自官网的: The WordCount examples demo ...
- Apache Beam的目标
不多说,直接上干货! Apache Beam的目标 统一(UNIFIED) 基于单一的编程模型,能够实现批处理(Batch processing).流处理(Streaming Processing), ...
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
- Apache Beam 剖析
1.概述 在大数据的浪潮之下,技术的更新迭代十分频繁.受技术开源的影响,大数据开发者提供了十分丰富的工具.但也因为如此,增加了开发者选择合适工具的难度.在大数据处理一些问题的时候,往往使用的技术是多样 ...
- Apache Beam—透视Google统一流式计算的野心
Google是最早实践大数据的公司,目前大数据繁荣的生态很大一部分都要归功于Google最早的几篇论文,这几篇论文早就了以Hadoop为开端的整个开源大数据生态,但是很可惜的是Google内部的这些系 ...
- 初探Apache Beam
文章作者:luxianghao 文章来源:http://www.cnblogs.com/luxianghao/p/9010748.html 转载请注明,谢谢合作. 免责声明:文章内容仅代表个人观点, ...
随机推荐
- 关于android LinearLayout的比例布局(转载)
关于android LinearLayout的比例布局,主要有以下三个属性需要设置: 1,android:layout_width,android:layout_height,android:layo ...
- CDH 的Cloudera Manager免费与收费版的对比表
CDH 特性 免费版 付费版 Deployment, Configuration & Management 系统管理 Automated Deployment & Hadoop Rea ...
- CodeForces 404C Ivan and Powers of Two
Ivan and Powers of Two Time Limit:1000MS Memory Limit:262144KB 64bit IO Format:%I64d & % ...
- Tr A(矩阵快速幂)
Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submission( ...
- emacs yasnippet
首先安装emacs 然后下载yasnippet-bundle-0.6.1c.el.tgz解压 在~/.emacs.d/文件夹下新建一个文件plug,一般是新建一个plugins但是我到下面有这个文件夹 ...
- gprof参数说明及常见错误
参数说明 l -b 不再输出统计图表中每个字段的详细描述. l -p 只输出函数的调用图(Call graph的那部分信息). l -q 只输出函数的时间消耗列表. l -e Name 不再输出函数N ...
- 【BZOJ】1798: [Ahoi2009]Seq 维护序列seq(线段树)
http://www.lydsy.com/JudgeOnline/problem.php?id=1798 之前写了个快速乘..........................20多s...... 还好 ...
- 用Git进行协同开发
用Git进行协同开发 问题场景描述 常常会遇到这样的协同场景:后台的同事和前端的同事需要共同开发一个新功能,而他们的代码相互依赖,所以需要不停地更新各自的代码进行联调. 对于这种场景,最简单的方式就是 ...
- JS。 问题类型:穷举,迭代。两个关键词:break和continue
问题类型: 穷举:(在不知道什么情况下是我们需要的结果的时候只能够让它一个一个都给走一遍) 百鸡百钱:公鸡1钱,母鸡2钱,小鸡0.5钱. 思路: 公鸡买100只,母鸡,小鸡都是0只: 母鸡50只,公鸡 ...
- Oracle用户信息查询
1.查看所有用户: select * from dba_users; select * from all_users; select * from user_users; 2.查看用户或角 ...