Frequent Pattern 挖掘之一(Aprior算法)(转)
数据挖掘中有一个很重要的应用,就是Frequent Pattern挖掘,翻译成中文就是频繁模式挖掘。这篇博客就想谈谈频繁模式挖掘相关的一些算法。
定义
何谓频繁模式挖掘呢?所谓频繁模式指的是在样本数据集中频繁出现的模式。举个例子,比如在超市的交易系统中,记载了很多次交易,每一次交易的信息包括用户购买的商品清单。如果超市主管是个有心人的话,他会发现尿不湿,啤酒这两样商品在许多用户的购物清单上都出现了,而且频率非常高。尿不湿,啤酒同时出现在一张购物单上就可以称之为一种频繁模式,这样的发掘就可以称之为频繁模式挖掘。这样的挖掘是非常有意义的,上述的例子就是在沃尔玛超市发生的真实例子,至今为工业界所津津乐道。
Aprior挖掘算法:
那么接下来的问题就很自然了,用户该如何有效的挖掘出所有这样的模式呢?下面我们就来讨论一下最简单,最自然的一种方法。在谈到这个算法之前,我们先声明一个在频繁模式挖掘中的一个特性-Aprior特性。
Aprior特性:
这个特性是指如果一个Item set(项目集合)不是frequent item set(频繁集合),那么任何包含它的项目集合一定也不是频繁集合.这里的集合就是模式.这个特性很自然,也很容易理解.比如还是看上面沃尔玛超市的例子,如果啤酒这个商品在所有的购物清单中只出现过1次,那么任何包含啤酒这个商品的购物商品组合,比如(啤酒,尿不湿)最多也只出现了一次,如果我们认定出现次数多于2次的项目集合才能称之为频繁集合的话,那么这些包含了啤酒的购物组合肯定都不是频繁集合.反之,如果一个项目集合是频繁集合,那么它的任意非空子集也是频繁集合.
有了这个特性,那么就可以在挖掘过程中对一些不可能的项目集合进行排除,避免造成不必要的计算浪费.这个方法主要包含两个操作:product(叉积)和prune(剪枝).这两种操作是整个方法的核心.
首先是product:
先有几个定义,L(k)-候选项目队列,该队列中包含一系列的项目集合(也就是说队列是项目集合的集合),这些项目集合的长度都是一样的,都为k,这个长度我们称之为秩(呵呵,秩是我自己取的中文名),这些长度相同的集合称之为k-集合。那么就有L(k+1)=L(k) product L(k).也就是说通过product操作(自叉积),秩为k的候选队列可以生成秩为k+1的候选队列。需要注意的是,这里所有的候选队列中的k-集合都按照字母顺序(或者是另外的某种事先定义好的顺序)排好序了。好,下面关键来了,product该如何执行?product操作是针对候选队列中的k-集合的,实际上就是候选队列中的k-集合两两进行执行join操作。K-集合l1,l2之间能够进行join有一个前提,那就是两个k-集合的前k-1个项目是相同的,并且l1(k)的顺序大于l2(k)(这个顺序的要求是为了排除重复结果)。用公式表示这个前提就是(l1[1]=l2[1])^(l1[2]=l2[2])^…^(l1[k-1]=l2[k-1])^(l1[k]<l2[k]).那么join的结果就形成了一个k+1长度的集合l1[1],l1[2],…,l1[k-1],l1[k],l2[k]。如果L(k)队列中的所有k-集合两两之间都完成了join操作,那么这些形成的k+1长度的集合就构成了一个新的秩为k+1的候选项目队列L(k+1)。
剪枝操作:
这个操作是针对候选队列的,它对候选队列中的所有k-集合进行一次筛选,筛选过程会对数据库进行一次扫描,把那些不是频繁项目集合的k-集合从L(k)候选队列中去掉。为什么这么做呢?还记得前面提到的Aprior特性么?因为这些不是频繁集合的k-集合通过product操作无法生成频繁集合,它对product操作产生频繁集合没有任何贡献,把它保留在候选队列中除了增加复杂度没有任何其他优点,因此就把它从队列中去掉。
这两个操作就构成了算法的核心,用户从秩为1的项目候选队列开始,通过product操作,剪枝操作生成秩为2的候选队列,再通过同样的2步操作生成秩为3的候选队列,一直循环操作,直到候选队列中所有的k-集合的出现此为等于support count.
下面给出一个具体的例子,可以很好得阐述上面的算法思想:
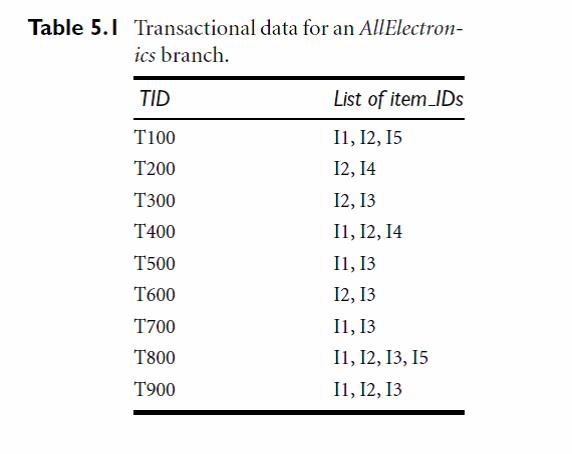

这种算法思路比较清晰直接,实施起来比较简单。但是缺点就是代价很大,每一次剪枝操作都会对数据库进行扫描,每一次product操作需要对队列中的k-集合两两进行join操作,其复杂度为C(sizeof(L(k)),2)。
为了提高算法效率,Han Jiawei提出了FP Growth算法,使得频繁模式的挖掘效率又提升了一个数量级。下一篇博客就着重分析一下FP growth。
Frequent Pattern 挖掘之一(Aprior算法)(转)的更多相关文章
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- Aprior算法
在关联规则挖掘领域最经典的算法法是Apriori,其致命的缺点是需要多次扫描事务数据库.于是人们提出了各种裁剪(prune)数据集的方法以减少I/O开支,韩嘉炜老师的FP-Tree算法就是其中非常高效 ...
- 八、频繁模式挖掘Frequent Pattern Mining
频繁模式挖掘(Frequent Pattern Mining): 频繁项集挖掘是通常是大规模数据分析的第一步,多年以来它都是数据挖掘领域的活跃研究主题.建议用户参考维基百科的association r ...
- 频繁项集挖掘之Aprior和FPGrowth算法
频繁项集挖掘的应用多出现于购物篮分析,现介绍两种频繁项集的挖掘算法Aprior和FPGrowth,用以发现购物篮中出现频率较高的购物组合. 基础知识 项:“属性-值”对.比如啤酒2罐. 项集:项的集 ...
- 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法
转自:http://www.cnblogs.com/fengfenggirl/p/associate_apriori.html 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法 我计划 ...
- 数据关联分析 association analysis (Aprior算法,python代码)
1基本概念 购物篮事务(market basket transaction),如下表,表中每一行对应一个事务,包含唯一标识TID,和购买的商品集合.本文介绍一种成为关联分析(association a ...
- 数据挖掘Aprior算法详解及c++源码
[算法大致描述] Aprior算法主要有两个操作,扫描数据库+统计.计算每一阶频繁项集都要扫描一次数据库并且统计出满足支持度的n阶项集. [算法主要步骤] 一.频繁一项集 算法开始第一步,通过扫描数据 ...
随机推荐
- Android JNI使用方法
经过几天的努力终于搞定了android JNI部分,下面将我的这个小程序和大家分享一下.android JNI是连接android Java部分和C/C++部分的纽带,完整使用JNI需要Java代码和 ...
- Android 获取图片资源的4种方式
1. 图片放在sdcard中 Bitmap imageBitmap = BitmapFactory.decodeFile(path) (path 是图片的路径,跟目录是/sdcard) 2. 图片在项 ...
- BZOJ3132: 上帝造题的七分钟
3132: 上帝造题的七分钟 Time Limit: 20 Sec Memory Limit: 128 MBSubmit: 483 Solved: 222[Submit][Status] Desc ...
- js前台与后台数据交互-后台调前台(后台调用、注册客户端脚本)
转自:http://blog.csdn.net/wang379275614/article/details/17049721 客户端脚本一般都在前台,这里讲的是(1)在后台调用前台定义的脚本(2)在后 ...
- 你认为A和B所在方格颜色相同吗?
[你认为A和B所在方格颜色相同吗? ]据说全世界只有0.003%的人和photoshop能看出它们的颜色是相同的. 我属于那 99.9997% 的人...因为我不是神...
- 如何解决PHP生成UTF-8编码的CSV文件用Excel打开乱码的问题
为了识别 Unicode 文件,Microsoft 建议所有的 Unicode 文件应该以 ZERO WIDTH NOBREAK SPACE字符开头.这作为一个”特征符”或”字节顺序标记(byte-o ...
- Bzoj 1976: [BeiJing2010组队]能量魔方 Cube 最小割,最大流
1976: [BeiJing2010组队]能量魔方 Cube Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 879 Solved: 304[Submi ...
- 怎样安装Joomla 1.7网站系统
http://jingyan.baidu.com/article/8065f87fc3de112331249830.html 如果你想使用Joomla(地球上最好的内容管理系统之一)搭建一个网站, ...
- RHEL7 -- Linux搭建FTP虚拟用户
安装vsftpd软件包[root@localhost ~]# yum install vsftpd -y [root@localhost ~]# yum install db4 db4-utils 建 ...
- ubuntu-15.04 下编译 ijkplayer 安卓版
我的环境: 1.win7 主系统 2.VirtualBox 5.1.2 虚拟机 3.ubuntu-15.04-desktop-amd64.iso 镜像文件 4.android-ndk-r10e-lin ...