scrapy学习(完全版)
scrapy1.6中文文档
Scrapy框架
- 下载页面
- 解析页面
- 并发
- 深度
安装
- scrapy学习教程
- 如果安装了anconda,可以在anaconda prompt中使用conda install scrapy
- 也可以使用pycharm安装
使用
- 指定初始URL
- 解析响应内容
- 给调度器
- 给item;pipeline用于做格式化;持久化
创建一个初始scrapy初始项目初始工作
① 、在windows终端(cmd)输入,进行前期工作
- scrapy startproject 工程名 >(注意你此时的路径就是你工程所在的路径)
- cd 工程名 (转到你工程所在的文件夹)
- scrapy genspider 爬虫名 要爬的网址 (创建一个爬虫)
- 打开工程文件中的
settings.py文件 ,进行基本设置
- 令 ROBOTSTXT_OBEY = False (不遵守robot协议,因为如果遵守基本上爬取不到东西)
- 在Override the default request headers: 中 启动headers 加'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE'
②、spiders文件里的编辑
- 打开 爬虫名.py 进行编辑 (编写你的爬虫文件)
- scrapy crawl 爬虫名 (运行爬虫,此时应处于你的工程路径下,如果后面加 "--nolog会只输出结果)
- 在spider文件的初始处理函数中写入:form scrapy.http import Request , yield Request(url = url,callback = self.parse) 可以将新要访问的url添加到调度器中,然后调度器进行访问与下载,得到的response交给parse函数处理 (如果要执行深度的话,必须使callback =self.parse 这样才能迭代
- response的方法与属性:
- response.text 返回服务器返回的response(一般为网页源代码)的字符串形式
- response.body 返回服务器返回的response(一般为网页源代码)的字节形式
- response.xpath('str') 以xpath语法定位元素,返回为selector或者selector_lsit对象
- response.meta 返回的是一个字典,其中包含了很多信息,例如 depth
- selector或者seletor_list对象可以使用xpath继续定位元素
- selector_list对象可以迭代
- 通过对selector或者selector_list对象使用extract()等价于getall() 或者 extract_first()等价于get()方法,可以将selector或seletor_list对象中的文本信息提取出来,那个getall()和extract()是生成字符串组成的列表
- 可以通过重写该方法,让访问start_urls中的url的访问返回的response对象调用新的方法(即指定最开始处理请求的方法),即可以将self.parse改成别的
def start_requests(self):
for url in self.start_urls:
yield Request(url,callback=self.parse)
③、items文件中的编辑
- 通过在items.py文件的XXXXItem类中写入:例如:author =scrapy.Field() ,content =scrapy.Field() 可以将要传给pipelines的数据进行格式化,即用一个XXXItem对象进行封装。然后通过在spider文件初始函数中中写入:from 工程名.items import XXXItem ,item = XXXXItem(author = author,content =content)就可以将数据进行格式化,将author,content封装到item对象中,再通过写yield item 自动将item对象递交给引擎,然后引擎再传给pipelines
④ 、pipelines文件中的编辑
- settings文件中 开启Configure item pipelines 中的那个字典,其中的数字代表了pipelines执行的优先级,你可以在 pipelines文件中定义多个类,通过优先级决定了他们执行的顺序,小的优先。
- 在pipelines中传递的item就是从spider中那边传过来的数据,可以通过
dict(item)将其变成字典进行储存,也可以用scrapy中内置的类进行存储,见后面;spider指的是spider对象,他有name属性 ,因而可以通过 if spider.name = "XXX"判断是那个蜘蛛爬取的信息,进而有区别的进行处理。 - pipeline对象中process_item()方法是当spiders有yield语句 或reurn 数据语句中会执行该方法,open_spider()方法是当爬虫打开后会调用这个函数,close_spider()方法是爬虫完成后会调用该方法。
因而在打开文件的操作可以放在,open_spider()方法中,关闭文件的操作可以放在close_spider()方法中,这样可以防止重复的打开与关闭文件。from_crawler()方法用于创建对象,并获取配置文件中的相关数据。
import json
#from scrapy.exporters import JsonItemExporter
from scrapy.exceptions import DropItem
class QsbkPipeline(object):
# def __init__(self):
# self.fp = open('duanzi.json','w',encoding = 'utf-8')
#
def __init__(self):
'''
进行数据初始化
'''
# self.fp = open('duanzi.json','wb',encoding = 'utf-8') # 这里要用二进制方式打开,因为JsonItemExporter写入文件的形式是二进制形式
# self.exporter = JsonItemExporter(self.fp,ensure_ascii = False,encoding = 'utf-8')
# self.exporter.start_exporting()
pass
@classmethod
def from_crawler(cls,crawler):
'''
创建对象,并获取配置文件(settings)中的相关数据
:param crawler:
:return:
'''
# conn_str = crawler.settings.get("DB") # 获取配置文件(settings文件)中的DB值,
# return cls(conn_str)# 创建对象,并向对对象中传入配置文件中的DB值,可以在__inint__方法中,获取到
def process_item(self, item, spider):
'''
当spiders有yield语句 或reurn 数据语句中会执行该方法
:param item:
:param spider:
:return:
'''
# item_json = json.dumps(dict(item),ensure_ascii = False)
# self.fp.write(item_json+'\n')
# return item
print(item['author']+":"*5+item['content'])
# return item # 当有多个pipeline对象时,这里返回一个item,即可以将item传递给下一个pipeline对象
# raise DropItem() # 若不想将item交给下一个pipeline对象,应该使用这种方式,因为后面有某种方式可以监听
def open_spider(self,spider):
'''
爬虫打开后会调用这个函数
:param spider:
:return:
'''
pass
def close_spider(self,spider):
'''
爬虫完成后会调用这个函数
:param spider:
:return:
'''
pass
scrapy中的自带的去重方法:
输入这个语句即可看到,scrapy中自带类的语句,模范这个类,自定义写一个新的文件,自定义相关方法,即可自定义去重
from scrapy.dupefilters import RFPDupeFilter
自定义去重方法(scrapy中默认是可以在传入调度器中的url去重的)
- 也可以自定义对象,来进行自定义去重 例子:新创建一个含有类RepeatFilter文件,在settings文件中加入以下下配置信息,进行自定义去重类的注册(激活)
DUPEFILTER_CLASS = '工程名.类所在的文件名.RepeatFilter'
类RepeatFilter文件中的代码如下:
# 这个类的名称可以随意定义
class RepeatFilter(object):
def __init__(self):
'''
2、进行对象初始化
'''
self.visited_set = set() #定义一个集合,用来存储非重复地url
@classmethod # 这是一个类方法
def from_settings(cls, settings):
'''
1、创建对象
'''
return cls() #在这里创建了一个实例,因而会去执行__init__()方法
def request_seen(self, request):
'''
4、对象被访问即调用该方法
'''
if request.url in self.visited_set:
return True
self.visited_set.add(request.url)
return False
def open(self): # can return deferred
'''
3、打开蜘蛛,开始爬取
'''
pass
def close(self, reason): # can return a deferred
'''
停止爬取
'''
pass
def log(self, request, spider): # log that a request has been filtered
pass
cookies问题(模拟登陆时用到的)
# -*- coding: utf-8 -*-
# Scrapy settings for qsbk project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'qsbk' # 爬虫的名字,会放在后面的USER_AGENT中
# 爬虫的路径
SPIDER_MODULES = ['qsbk.spiders']
NEWSPIDER_MODULE = 'qsbk.spiders'
# 标识请求的身份
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'qsbk (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
# Obey robots.txt rules 是否遵守爬虫协议
ROBOTSTXT_OBEY = False
# 并发请求的最大数目,一次可以发出的最大请求数目
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# 当对同一网站发送不同请求之间的延迟(单位:秒)
DOWNLOAD_DELAY = 2
# The download delay setting will honor only one of:
# 具体针对某个域名或IP的最大并发数,比上面的更精准
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# 是否帮你获取cookies,默认为True
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# 是否监听爬虫的状态,默认为True,在cmd中输入:telnet 127.0.0.1 6023 即可进入监听状态,输入相应操作命令即
# 可获得相关信息,例如:est()
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers: 设置请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'qsbk.middlewares.QsbkSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'qsbk.middlewares.QsbkDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
# 注册扩展
EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
'qsbk.my_extention.MyExtend':200
}
from scrapy.extensions.telnet import TelnetConsole
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# 注册pipeline,即pipelines文件的代码能运行
ITEM_PIPELINES = {
'qsbk.pipelines.QsbkPipeline': 300, # pipelines执行的优先级
}
# 智能请求,让请求间的时间间隔变得不固定,这里填的参数是智能限速算法的相关参数
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True # 是否允许智能请求
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5 # 初始请求的延迟时间(秒)
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60 # 请求间的最大延迟时间
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# 15. 调度器队列
# SCHEDULER = 'scrapy.core.scheduler.Scheduler'
# from scrapy.core.scheduler import Scheduler
# 做缓存
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# 是否启用缓存策略 默认为False
# HTTPCACHE_ENABLED = True
# 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可 默认的缓存策略
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy"
# 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略 这种缓存策略比上面的好,一般用这个就行,上面的可以不用
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy"
# 缓存超时时间,若请求时间超过多少我就不存了
# HTTPCACHE_EXPIRATION_SECS = 0
# 缓存保存路径
# HTTPCACHE_DIR = 'httpcache'
# 缓存忽略的Http状态码,如果状态码是这个,我就不存了
# HTTPCACHE_IGNORE_HTTP_CODES = []
# 缓存存储的插件,即缓存的具体方法
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# from scrapy.extensions.httpcache import FilesystemCacheStorage # 通过这条语句可以看到里面具体的方法
#DEPTH_LIMIT = 1 # 指定"递归"的层数 可以限制爬取深度,这个深度是与start_urls中定义url的相对值。也就是相对url的深度。
# 例如定义url为:http://www.domz.com/game/,DEPTH_LIMIT=1那么限制爬取的只能是此url下一级的网页。深度大于设置值的将被ignore。
#DEPTH_PRIORITY =0 # 只能是0或1,依次表示是深度度优先还是广度优先,调度器中url访问的顺序,默认为0
# 进行自定义去重类的注册(激活)
# DUPEFILTER_CLASS = 'qsbk.my_dupefilter.RepeatFilter'
# 里面的配置变量名 必须大写
缓存
缓存:在更近的地方快速将数据读取出来
在settings文件中进行相关注册与配置
代理
- scrapy中默认的代理必须依赖环境变量 (不好用,使用自定义的更好)
from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware
#默认的代理要添加到这里面去,格式如下
os.environ
{
http_proxy:http://代理账号:代理密码@192.168.11.11:9999/
https_proxy:http://192.168.11.11:9999/
}
- 使用自定义代理插件
例子:新创建一个含有类ProxyMiddleware文件,在settings文件中加入相关配置信息,进行自定义代理的注册(激活)
新建文件的代码如下:
import base64
import random
def to_bytes(text, encoding=None, errors='strict'):
if isinstance(text, bytes):
return text
if not isinstance(text, six.string_types):
raise TypeError('to_bytes must receive a unicode, str or bytes '
'object, got %s' % type(text).__name__)
if encoding is None:
encoding = 'utf-8'
return text.encode(encoding, errors)
# 这个类的名称不能改变
class ProxyMiddleware(object):
def process_request(self, request, spider):
PROXIES = [
{'ip_port': '111.11.228.75:80', 'user_pass': ''},
{'ip_port': '120.198.243.22:80', 'user_pass': ''},
{'ip_port': '111.8.60.9:8123', 'user_pass': ''},
{'ip_port': '101.71.27.120:80', 'user_pass': ''},
{'ip_port': '122.96.59.104:80', 'user_pass': ''},
{'ip_port': '122.224.249.122:8088', 'user_pass': ''},
]
# 把代理就填入PROXIES字典中
proxy = random.choice(PROXIES)
if proxy['user_pass'] is not None:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass']))
request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass)
print("**************ProxyMiddleware have pass************" + proxy['ip_port'])
else:
print ("**************ProxyMiddleware no pass************" + proxy['ip_port'])
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
在settings文件中配置以激活
DOWNLOADER_MIDDLEWARES = {
'工程名.代理插件文件名.ProxyMiddleware': 500,
}
https访问(scrapy默认不支持自定义证书访问)
- 要爬取的网站使用的是可信任证书(默认支持)
这是在settings中默认的配置,一般不可见
DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory"
DOWNLOADER_CLIENTCONTEXTFACTORY = "scrapy.core.downloader.contextfactory.ScrapyClientContextFactory"
- 要爬取网站使用的自定义证书
例子:需要改写MySSLFactory类,在settings文件改变相关配置信息
新建文件的代码如下:
from scrapy.core.downloader.contextfactory import ScrapyClientContextFactory
from twisted.internet.ssl import (optionsForClientTLS, CertificateOptions, PrivateCertificate)
class MySSLFactory(ScrapyClientContextFactory):
def getCertificateOptions(self):
from OpenSSL import crypto
# 这里只需要改变你拿到的证书的两个文件的地址即可
v1 = crypto.load_privatekey(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.key.unsecure', mode='r').read())
v2 = crypto.load_certificate(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.pem', mode='r').read())
return CertificateOptions(
privateKey=v1, # pKey对象
certificate=v2, # X509对象
verify=False,
method=getattr(self, 'method', getattr(self, '_ssl_method', None))
)
相关在settings文件中的配置信息
DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory"
DOWNLOADER_CLIENTCONTEXTFACTORY = "工程名.文件名.MySSLFactory"
中间件
1. 自定义下载中间件
传入给调度器的Request请求会一个个经过自定义的下载中间件(DOWNLOADER_MIDDLEWARES),顺序为settings文件中的配置信息数值得大小(小的优先),要是自定义的下载中间件都不下载,最后会由scrapy内置的下载中间件去下载。
- 一般执行方法的顺序是,先去执行每一个下载中间件的process_request方法(顺序为setting文件中的配置权顺序,小的先),然后以相反的顺序执行每一个下载中间件的process_response方法。若前面过程中出现了异常,会执行每一个下载中间件的process_exception方法。然后执行爬虫中间件中的process_spider_input方法,最后会执行爬虫中的yield Request(callback=fun1)指明的fun1方法
- 有一个下载中间件中的process_request方法中,返回了response(即存在 return response),后续就不在执行后续中间件的process_request方法
- process_response 方法中必须要有 return response ,否知resposne传不到其它的process_response方法和spider中的方法中
自定义下载中间件的文件中的示例代码:
class DownMiddleware1(object):
def process_request(self, request, spider):
'''
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;,没有return语句时的默认形式
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
'''
pass
def process_response(self, request, response, spider):
'''
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
'''
print('response1')
return response
def process_exception(self, request, exception, spider):
'''
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
'''
return None
setting文件中的配置:
DOWNLOADER_MIDDLEWARES = {'工程名.文件名.DownMiddleware1':543}
爬虫中间件
自定义spider中间件的文件中的示例代码:
class SpiderMiddleware(object):
def process_spider_input(self, response, spider):
'''
下载中间件完成后,调用该方法,然后交给spider中的parse(指callbakc指定的函数)处理
:param response:
:param spider:
:return:
'''
pass
def process_spider_output(self, response, result, spider):
# 这个result就是parse中yield Request或yield Item的生成器
'''
spider处理完成,返回时调用该方法
:param response:
:param result:
:param spider:
:return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)
'''
return result
def process_spider_exception(self, response, exception, spider):
'''
异常调用
:param response:
:param exception:
:param spider:
:return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline
'''
return None
def process_start_requests(self, start_requests, spider):
'''
爬虫启动时调用
:param start_requests:
:param spider:
:return: 包含 Request 对象的可迭代对象
'''
return start_requests
setting文件中的配置:
SPIDER_MIDDLEWARES = {'工程名.文件名.SpiderMiddleware':500}
自定制命令
- 在spiders同级创建任意文件夹,如:commands
- 在其中创建 crawlall.py 文件 (此处文件名就是自定义的命令) 文件中的代码如下:
from scrapy.commands import ScrapyCommand
from scrapy.utils.project import get_project_settings
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
# 找到所有的爬虫名称
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
- 在settings.py 中添加配置
COMMANDS_MODULE = '工程名.文件名'
- 在cmd中,在项目目录执行命令:scrapy crawlall,即可运行所有的爬虫
scrapy shell(命令行交互模式)
由于scrapy框架比较大,每次运行起来都要等待一段时间。因此要去验证我们写的提取规则(xpath等)是否正确,是一个比较麻烦的事情。因此scrapy提供了一个shell,用来方便的测试规则。当然也不仅仅只局限于这一个功能。
- 打开Scrapy Shell:打开cmd终端,进入到Scrapy项目所在的目录,然后进入到
scrapy框架所在的虚拟环境中,输入命令:
scrapy shell 链接
# 例如:scrapy shell https://www.baidu.com
- 进入到scrapy的shell环境中后,你就可以跟在爬虫的parse方法中一样使用了。
- 例如输入 content = response.xpath('......') 进行元素定位与选取
- exit()退出该模式
快速输出
不需要在pipelines编写相关语句,但是需要在items格式化,但是要在spider 中yield item
在cmd窗口中(此时应在该项目目录中)输入:
scrapy crawl 爬虫名 -o 输出文件名.json # 输出为json文件
scrapy crawl 爬虫名 -o 输出文件名.csv # 输出为csv文件
scrapy crawl 爬虫名 -o 输出文件名.jl # 输出为每一个item为一行的json文件
scrapy crawl 爬虫名 -o 输出文件名.xml # 输出为xml文件
scrapy crawl 爬虫名 -o 输出文件名.pickle # 输出为pickle文件
利用py文件启动爬虫(即不需要在cmd窗口中输入命令)
在项目文件夹下新建一个py文件,如图:


文件中代码示例如下:
from scrapy import cmdline
# 这个文件是执行命令行的语句,
cmdline.execute(['scrapy','crawl', 'qsbk_spider'])
这样,以后通过点击start.py文件,即可执行爬虫。
pipelines中优化存储数据的方式
方式1:
from scrapy.exporters import JsonItemExporter
#这种方式是先将item以字典形式添加到列表中,然后在finish_expoerting()时将整个列表写入js文件中。这种方式比较占内存.
但是整个文件是一个json文件形式,可以直接load
# 还有其他导出方式,在exporters文件中去寻找相关类
class QsbkProjectPipeline(object):
def __init__(self):
self.f = open('duanzi.json','wb') # 这里要用二进制形式打开,因为JsonItemExporter是以二进制形式写入文件的
self.exporter = JsonItemExporter(self.f,ensure_ascii = False,encoding ='utf-8')
self.exporter.start_exporting()
def process_item(self, item, spider):
self.exporter.export_item(item)
def open_spider(self,spider):
print("爬虫开始了啊")
def close_spider(self,spider):
self.exporter.finish_exporting()
self.f.close()
print('爬虫结束了')
方式2:
from scrapy.exporters import JsonLinesItemExporter
# 这种方式是一个字典(item),写入json文件中的一行,整个文件并不满足json文件形式,这样在读取该文件时,应该一行行读取,然后挨个loads
# 并且这种方式不需要,start_exporting()与finish_exporting()语句,节省内存
class QsbkProjectPipeline(object):
def __init__(self):
self.f = open('duanzi.json','wb') # 这里要用二进制形式打开,因为JsonItemExporter是以二进制形式写入文件的
self.exporter = JsonLinesItemExporter(self.f,ensure_ascii = False,encoding ='utf-8')
def process_item(self, item, spider):
self.exporter.export_item(item)
def open_spider(self,spider):
print("爬虫开始了啊")
def close_spider(self,spider):
self.f.close()
print('爬虫结束了')
Crawlspider类
对于一般的scrapy.spider类,我们一般是自己在解析整个页面后获取下一页的url,然后重新发送一个请求。有时候我们想要这样做,只要满足某个条件的url,都给我们进行爬取。那么此时我们就可以通过CrawlSpider来帮助我们完成。CrawlSpiser继承自Spider,只不过是在之前的基础上增加了新的功能,可以定义爬取url的规则,以后scrapy碰到满足条件的url都进行爬取,而不用手动的yield Request
创建CrawlSpider爬虫
scrapy genspider -t crawl [爬虫名] [域名]
LinkExtractors链接提取器
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规划的url,实现自动的爬取。介绍如下:
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains=(),
deny_extensions=None,
restrict_xpaths=(),
tags = ('a','area'),
attrs = ("href"),
canonicalize = True,
unique=True,
process_value =None,
deny_extensions
....
)
主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取。里面可以写正则表达式
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。里面可以写正则表达式
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。里面可以写正则表达式
-deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。里面可以写正则表达式 - estirct_xpaths=(),restricc_css()在网页哪个区域里提取链接,可以用xpath表达式和css表达式这个功能是划定提取链接的位置,让提取更加精准。
- tags:默认提取a标签和area标签
- attrs:接收一个属性(字符串)或者一个属性列表,提取指定的属性内的链接,默认为attrs=(‘href’,)
- unique:就是说这个地址是不是要规定唯一的,默认true,重复收集一样的地址也没意义不是。
- strip,这个是把地址前后多余的空格删除,很有必要。
- process_value=None,这个作用比较强大了,他接受一个函数,可以立即对提取到的地址做加工,比如提取用js写的链接,官方文档给了一个例子。
# 例如,从这段代码中提取链接:
<a href="javascript:goToPage('../other/page.html'); return false">Link text</a>
# 你可以使用下面的这个 process_value 函数:
def process_value(value):
m = re.search("javascript:goToPage\('(.*?)'", value)
if m:
return m.group(1)
- deny_extensions,排除非网页链接,默认是None,scrapy会给你排除掉以下链接。
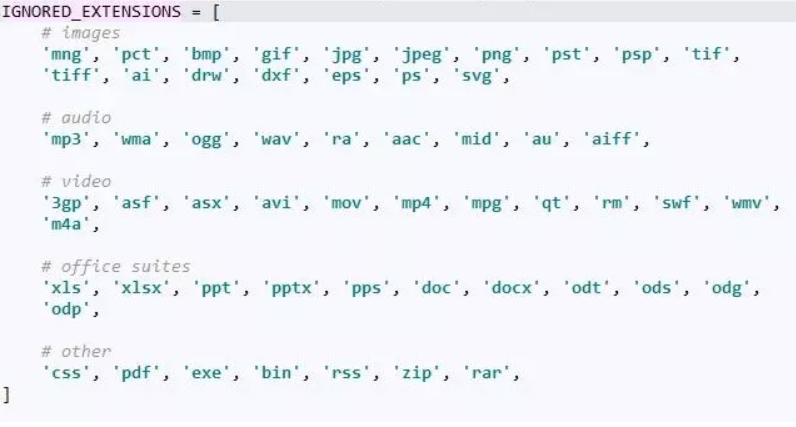
用LinkExtractor类提取的链接,是个link对象组成的list,每个link对象包含ur地址和链接文本。形如这样
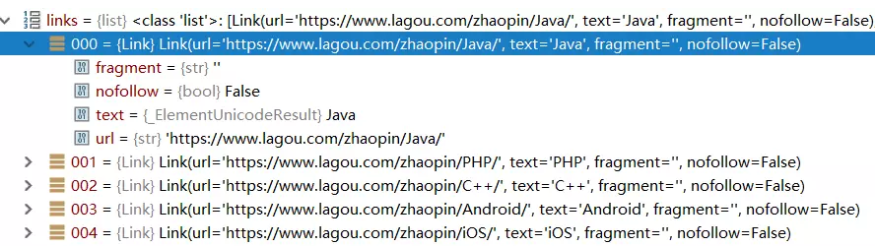
提取链接和文本的方法是实例.link 和实例.text
我用拉勾网的链接提取做个例子,上代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
class YanjiuSpider(scrapy.Spider):
name = 'yanjiu'
allowed_domains = ['www.lagou.com']
start_urls = ['https://www.lagou.com/']
def parse(self, response):
link=LinkExtractor(allow=(r'jobs/\d+.html',r'zhaopin/.*?'),)
links=link.extract_links(response)
print(links)
for lin in links:
print(lin.url,lin.text)
Rule规则类
定义爬虫的规则类。以下是简单的介绍:
class scrapy.spiders.Rule(
link_extractor,
callback=None,
cb_kwargs=None,
follow =None,
process_links =None,
process_request =None
)
主要参数讲解:
- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行啷个回调函数。因为
Crawlspider使用了·parse作为回调函数,因此不要覆盖parse`作为回调函数自己的回调函数。 - follow:指定根据该规则从response中提取的链接是否需要跟进。一般为True,即新出现的页面中的url是否需要跟进
- process_links:从`link_extractor中获取到链接的列表后会传递给这个函数,用来过滤不需要爬取的链接。
- cb_kwargs:给回调函数传参(cb_kwargs)。
- process_request: 该规则提取到每个request时都会调用该函数。 (用来过滤request),该函数必须返回一个request或者None。 (用来过滤request),可以用来更改request
例如:在使用rule提取链接后,request如何添加headers、cookies?
class TestSpider(CrawlSpider):
name = "test"
start_urls = [
"https://www.zhihu.com",
]
myheaders = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
"Referer": "https://www.zhihu.com"
}
rules = [
Rule(LinkExtractor(allow= '/topic/\d+$'),
process_request='request_tagPage', callback = "parse_tagPage", follow = True)
]
def request_tagPage(self, request):
# 这里可以更改Request对象中的信息,例如:body,headers,method,等等
newRequest = request.replace(headers=self.myheaders)
# request.repleace方法是:Create a new Request with the same attributes except for those
given new values
newRequest.meta.update(cookiejar=1)
return newRequest
def parse_tagPage(self,response):
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from wxapp.items import WxappItem
class WxappSpiderSpider(CrawlSpider):
name = 'wxapp_spider'
allowed_domains = ['wxapp-union.com']
start_urls = ['http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1']
#rules中可以有多个Rule,用于对提取url,并进行相关操作
rules = (
Rule(LinkExtractor(allow=r'mod=list&catid=2&page=\d+'),follow=True),
Rule(LinkExtractor(allow=r'article-\d+-\d\.html'), callback= 'parse_item', follow=False)
#猜想,对于这种提取到的<a href="article-5216-1.html" </a>,scrapy会自动将其与allowed_domains(允许的域名)进行进行拼接,以形成完整的url
)
# 第一个Rule中的callback参数不需要再指定,因为只要对提取的这些url进行ruquest,然后在resposne中follow(继续)用rules进行提取url,并进行相关操作
# 第二个Rule中,follo参数为false,因为对于详情页中的url,不需要在提取并进行相关操作
# 笔记:
# 什么情况下使用follow?:使用follow:如果在爬取页面的时候,需要将满足当前条件的url再进行跟进,那么就设置为True,否则设置为False
# 什么情况下该指定callback?: 如果这个url对应的页面,只是为了获取更多的url,并不需要里面的数据,那么可以不指定callback。如果想要获取url对应页面
# 中的数据,那么就需要指定一个callback。
# 注意:这里就不要用parse方法了,因为CrawlSpider类中已经定义了parse方法
def parse_item(self, response):
title = response.xpath('//h1[@class = "ph"]/text()').get()
author = response.xpath('//p[@class ="authors"]/a/text()').get()
content = "".join(response.xpath('//td[@id="article_content"]//text()').getall()).strip()
item = WxappItem(title=title,content=content,author=author)
yield item
#### Reuquest对象与Response对象
1. Request 对象在我们写爬虫,爬取一页的数据需要重新发送一个请求的时候调用。这个类需要传递一些参数,其中比较常用的参数有
- url:这个ruquest对象发送请求的url.
- callback:在下载器完相应的数据后执行的回调函数。若不指定,他会由原先的parse方法去执行。故一般request时,最好callback指定个函数,若实在不需要,可以写个pass函数。
- method:请求的方法。默认为GET方法,可以设置为其它方法还有:POST,但是对于POST方法,建议使用FormRequest来实现
- headers:请求头,对于一些固定的设置,放在settings.py中指定就可以了。对于那些非固定的,可以在发送请求的时候指定。
- meta:比较常用。用于在不同的请求之间传递数据用的。好像只能是字典。
- encoding:编码。默认的为utf-8,使用默认的就可以了。
-dot_filter:表示是否使用调度器过滤,默认为True,即默认是过滤的。在执行多次重复的请求的时候用得比较多。
-errback:在发生错误的时候执行的函数。
2. Response对象
Resposne对象一般是由Scrapy给你自动构建的。因此开发者不需要关心如何创建Response对象,而是如何使用他。Resposne对象有很多属性,可以用来提取数据的。主要有以下属性:
- meta:从其他请求(Request)传过来的meta属性,可以用来保持多个请求之间的数据连接。
- encoding:返回当前字符串编码与解码的格式。
- text:将返回的数据作为unicode字符串返回,
- body:将返回的数据作为bytes字符串返回
- xpath:使用xpath选择器,来定位元素
- css:使用css选择器,来定位元素
3. 发送POST请求:
有时候我们想要在请求数据的时候发送POST请求,那么这时候需要使用Request的子类FormRequest来实现。如果想要在爬虫一开始的时候就发动POST请求,那么需要在爬虫类中重写`start_request(self)方法(里面使用的get请求),并且不再调用`start_urls里的url.
-- coding: utf-8 --
import scrapy
class GitHubSpider(scrapy.Spider):
name = 'github_spider'
allowed_domains = ['github.com']
start_urls = ['http://github.com/']
# 这里要重写start_requests这个方法,因为scrapy默认的第一个请求是由这个方法执行的,且默认url为start_urls中的url,
# method为GET,故要重写
def start_requests(self):
url = 'https://github.com/login'
yield scrapy.Request(url = url,callback= self.login,meta = {'cookiejar':1})
# 注意这里必须要用yiel
# Request对象中传递的meta好像只能是字典
def login(self,response):
url = 'https://github.com/session'
authenticity_token = response.xpath('//div[@id="login"]/form/input[2]/@value').get()
form_data = {'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token,
'login': 'Niceljg',
'password': 'ljg4667203123',
'webauthn-support': 'supported'
}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"}
yield scrapy.FormRequest(url= url,formdata = form_data,callback=self.parse,meta={'cookiejar':response.meta['cookiejar']},headers =headers)
# 在需要使用post方法请求时推荐使用scrapy.FormRequest进行请求,这样能很好地提交表单信息。
def parse(self, response):
url = 'https://github.com/settings/repositories'
# 注意这个网站是个人设置里面的repositories
yield scrapy.Request(url = url,meta = {'cookiejar':True},dont_filter= True,callback=self.get_repositories)
def get_repositories(self,response):
projects_names= response.xpath('//div[@class="listgroup-item simple public fork js-collab-repo"]//a[@class = "mr-1"]/text()').getall()
for i in projects_names:
print(i)
注意:debug信息中出现
D:\Anaconda3\lib\site-packages\scrapy\spidermiddlewares\referer.py:284: RuntimeWarning: Could not load referrer policy 'origin-when-cross-origin, strict-origin-when-cross-origin'
warnings.warn(msg, RuntimeWarning)
是正常的,猜想是提醒你重写了start_requests方法了吧
#### 下载文件与图片
scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的item pipelines。这些pipeline有些共同的方法和结构(我们称之为media pipeline)。一般来说你会使用Files Pipelines或者Images Pipeline。
1. 为什么要选择使用`scrapy`内置的下载文件的方法:
- 避免重新下载最近已经下载过的数据。
- 可以方便的指定文件存储的路径
- 可以将下载的图片转换成通用的格式。比如png或jpg
- 可以方便的生成缩略图。
- 可以方便的检测图片的宽和高,确保他们满足最小限制
- 异步下载,效率非常高
2. 下载文件的Files Pipeline:
当使用`Files Pipeline`下载文件的时候,按照以下步骤完成:
- 定义好一个`Item`,然后在这个`Item`中定义两个属性,分别为`files_urls`以及`files`。`files_urls`是用来存储需要下载的图片的url链接,需要给一个列表。
- 当文件下载完成后,会把文件下载的相关信息存储到`tem`的`files`属性中。比如下载路径、下载的url和文件的校验码等。
- 在配置文件`settings.py`中配置FILES_STORE,这个配置是用来设置文件下载下来的路径。
-scrapy学习(完全版)的更多相关文章
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- Scrapy学习篇(七)之Item Pipeline
在之前的Scrapy学习篇(四)之数据的存储的章节中,我们其实已经使用了Item Pipeline,那一章节主要的目的是形成一个笼统的认识,知道scrapy能干些什么,但是,为了形成一个更加全面的体系 ...
- Learning ROS for Robotics Programming - Second Edition(《ROS机器人编程学习-第二版》)
Learning ROS for Robotics Programming - Second Edition <ROS机器人编程学习-第二版> ----Your one-stop guid ...
- Scrapy:学习笔记(2)——Scrapy项目
Scrapy:学习笔记(2)——Scrapy项目 1.创建项目 创建一个Scrapy项目,并将其命名为“demo” scrapy startproject demo cd demo 稍等片刻后,Scr ...
- Scrapy:学习笔记(1)——XPath
Scrapy:学习笔记(1)——XPath 1.快速开始 XPath是一种可以快速在HTML文档中选择并抽取元素.属性和文本的方法. 在Chrome,打开开发者工具,可以使用$x工具函数来使用XPat ...
- python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学 ...
- Scrapy学习篇(十三)之scrapy-splash
之前我们学习的内容都是抓取静态页面,每次请求,它的网页全部信息将会一次呈现出来. 但是,像比如一些购物网站,他们的商品信息都是js加载出来的,并且会有ajax异步加载.像这样的情况,直接使用scrap ...
- 转载一个不错的Scrapy学习博客笔记
背景: 最近在学习网络爬虫Scrapy,官网是 http://scrapy.org 官方描述:Scrapy is a fast high-level screen scraping and web c ...
- Scrapy学习篇(十一)之设置随机User-Agent
大多数情况下,网站都会根据我们的请求头信息来区分你是不是一个爬虫程序,如果一旦识别出这是一个爬虫程序,很容易就会拒绝我们的请求,因此我们需要给我们的爬虫手动添加请求头信息,来模拟浏览器的行为,但是当我 ...
随机推荐
- 个人永久性免费-Excel催化剂功能第42波-任意字符指定长度随机函数
日常做表过程中,难免会有一些构造数据的场景,构造数据最好是用随机的数据,如随机密码,随机英文字母.数字等.在Excel原生的随机函数Rand中,仅能处理数字的随机,且最终生成的结果也是数字类型.今天E ...
- 深入了解数据校验:Java Bean Validation 2.0(JSR380)
每篇一句 吾皇一日不退役,尔等都是臣子 相关阅读 [小家Java]深入了解数据校验(Bean Validation):基础类打点(ValidationProvider.ConstraintDescri ...
- C#编程之JSON序列化与反序列化
1.在C#管理NuGet程序包中添加Json.NET 2.C#将对象序列化成JSON字符串 模型类1 /// <summary> /// JSON字符串模型.是否出错 /// </s ...
- Spring Cloud 之 Config与动态路由.
一.简介 Spring Cloud Confg 是用来为分布式系统中的基础设施和微服务应用提供集中化的外部配置支持,它分为服务端与客户端两个部分.其中服务端也称为分布式配置中心,它是一个独立的微服务 ...
- mysql语句汇总
MySQL常用命令: show databases; 显示数据库 create database name; 创建数据库 use databasename; 选择数据库 drop database ...
- decode函数的几种用法
1:使用decode判断字符串是否一样 DECODE(value,if1,then1,if2,then2,if3,then3,...,else) 含义为 IF 条件=值1 THEN RETURN(va ...
- textarea的拖拽怎么解决
textarea文本域在页面中是可以拖动的,即时你给了固定的宽度和高度,但这在我们页面布局中,使我们不需要的,因为可拖拽很多时候会影响我们页面的布局和整体的美观度. css3提供了一个resize属性 ...
- tab切换echarts无法正常显示问题
项目中使用到了Echarts来在展示图表,两个tab切换页面中都存在图表,页面加载完成后 对所有图表进行了初始化和绘制,然后切换查看时,发现图表的宽度不正确.,第一个tab显示是很正常的,但是第二个t ...
- Java中Timer和TimerTask来实现计时器循环触发
package xian; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.Fi ...
- StarUML 3.0 破解方法
首先在我这里下载 StarUML3.0 破解替换文件app.asar 链接:https://pan.baidu.com/s/1wDMKDQkKrE9D1c0YeXz0xg 密码:y65m 然后参照下 ...