【字符编码】字符编码 && Base64编码算法
一、前言
在前面的解决乱码的一文中,只找到了解决办法,但是没有为什么,说白了,就是对编码还是不是太熟悉,编码问题是一个很简单的问题,计算机从业人员应该也必须弄清楚,基于编码的应用有Base64加密算法,然后,这个问题一直放着,想找个机会解决。于是乎,终于逮到机会,开始下手。
二、编码
关于ASCII、Unicode编码、UTF-8编码等问题,可以参见笔者另外一篇博客【字符编码】彻底理解字符编码。
三、Base64算法
Base64是网络上最常见的用于传输8Bit字节代码的编码方式之一,关于Base64的介绍可以参见这两篇文章base64,BASE64算法,下面我们通过Java来实现Base64编码算法并且详细解析其中遇到的问题。
Base64编码算法的流程图如下:
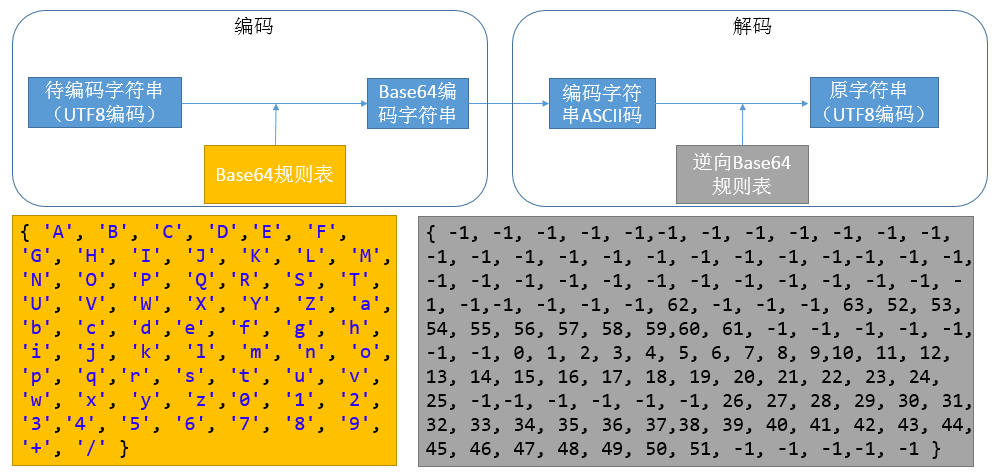
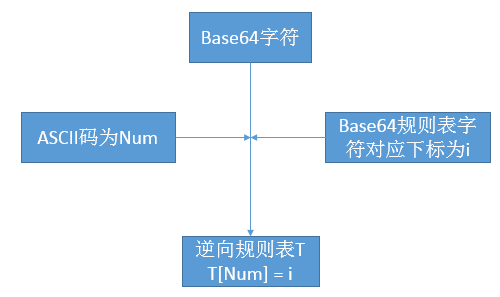
说明:Base64规则表由Base64的规定的规则得到,而逆向Base64规则表则通过少量的计算获得,如某Base64的编码字符串为QQ==,对于字符Q而言,Q的ASCII编码为81,Base64规则中,16对应Q,则将逆向Base64表中下标为81的项置为16。其余不在Base64中的元素在逆向表中值为-1,逆向表的计算流程如下:
四、Base64算法的Java实现
Java中的字符都是以Unicode格式进行存储的,如何查看任一个字符在Java中的表示?使用如下代码即可
import java.io.UnsupportedEncodingException;
public class Test {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "张";
byte[] bytes = str.getBytes("utf-8");
for (int i = 0; i < bytes.length; i++) {
System.out.print(Integer.toHexString(bytes[i] & 0xff).toUpperCase() + " ");
}
}
}
运行结果:
E5 BC A0
说明:假设中文张的编码为GBK,则转化为UTF-8编码经过了GBK->Unicode->UTF-8的步骤。
Base64算法代码清单
package com.leesf.chapter10;
import java.io.UnsupportedEncodingException;
public class Base64 {
private static char[] base64EncodeChars = new char[] { 'A', 'B', 'C', 'D',
'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q',
'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd',
'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q',
'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3',
'4', '5', '6', '7', '8', '9', '+', '/' };
private static byte[] base64DecodeChars = new byte[] { -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59,
60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1,
-1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37,
38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1,
-1, -1 };
public static String encode(byte[] data) {
StringBuffer sb = new StringBuffer();
int len = data.length;
int i = 0;
int b1, b2, b3;
while (i < len) {
// 提取b1
b1 = data[i++] & 0xff;
if (i == len) { // len % 3 == 1
// 向右无符号移动2位,保留b1的0-5位(前六位)
sb.append(base64EncodeChars[b1 >>> 2]);
// 保留b1的6-7位(后两位),其余位为0,然后向左移动4位,低位补0
sb.append(base64EncodeChars[(b1 & 0x3) << 4]);
// 添加两个等号(Base64规则)
sb.append("==");
// 跳出循环
break;
}
// 提取b2
b2 = data[i++] & 0xff;
if (i == len) { // len % 3 == 2
// 保留b1的0-5位(前六位),其余位为0
sb.append(base64EncodeChars[b1 >>> 2]);
// 保留b1的6-7位(后两位),其余位为0,然后向左移动4位,低位补0
// 然后保留b2的0-3位(前四位),然后合并
sb.append(base64EncodeChars[((b1 & 0x03) << 4)
| ((b2 & 0xf0) >>> 4)]);
sb.append(base64EncodeChars[(b2 & 0x0f) << 2]);
// 添加两个等号(Base64规则)
sb.append("=");
// 跳出循环
break;
}
// 提取b3
b3 = data[i++] & 0xff;
// 向右无符号移动2位,保留b1的0-5位(前六位)
sb.append(base64EncodeChars[b1 >>> 2]);
// 保留b1的6-7位(后两位),其余位为0,然后向左移动4位,低位补0
// 然后保留b2的0-3位(前四位),然后合并
sb.append(base64EncodeChars[((b1 & 0x03) << 4)
| ((b2 & 0xf0) >>> 4)]);
// 保留b2的4-7位(后四位),然后向右移2位,低位补0,
// 然后保留b3的0-1位(前两位),然后合并
sb.append(base64EncodeChars[((b2 & 0x0f) << 2)
| ((b3 & 0xc0) >>> 6)]);
// 保留b3的2-7位(后六位)
sb.append(base64EncodeChars[b3 & 0x3f]);
}
return sb.toString();
}
public static byte[] decode(String str) throws UnsupportedEncodingException {
// 使用ISO8859-1搭配其他编码如UTF-8,GBK可以显示中文
StringBuffer sb = new StringBuffer();
// 获取ASCII码
byte[] data = str.getBytes("US-ASCII");
int len = data.length;
int i = 0;
int b1, b2, b3, b4;
while (i < len) {
do {
b1 = base64DecodeChars[data[i++]];
} while (i < len && b1 == -1);
if (b1 == -1)
break;
do {
b2 = base64DecodeChars[data[i++]];
} while (i < len && b2 == -1);
if (b2 == -1)
break;
// b1向左移2位,然后b2保留2-3位,再向右无符号移动4位,再合并
sb.append((char) ((b1 << 2) | ((b2 & 0x30) >>> 4)));
do {
b3 = data[i++];
if (b3 == 61) // 遇到了=号,结束,返回
return sb.toString().getBytes("ISO8859-1");
b3 = base64DecodeChars[b3];
} while (i < len && b3 == -1);
if (b3 == -1)
break;
// 提取b2的4-7位(后四位),再向左移动4位,b3保留2-5位,再向右无符号移动2位
sb.append((char) (((b2 & 0x0f) << 4) | ((b3 & 0x3c) >>> 2)));
do {
b4 = data[i++];
if (b4 == 61) // 遇到了=号,结束,返回
return sb.toString().getBytes("ISO8859-1");
b4 = base64DecodeChars[b4];
} while (i < len && b4 == -1);
if (b4 == -1)
break;
// 提取b3的6-7位(最后两位),再向左移动6位,再取b4的2-7位(后六位),然后合并b4
sb.append((char) (((b3 & 0x03) << 6) | (b4 & 0x3f)));
}
return sb.toString().getBytes("ISO8859-1");
}
public static void main(String[] args) throws UnsupportedEncodingException {
String s = "张";
System.out.println("编码前:" + s);
String x = encode(s.getBytes());
System.out.println("编码后:" + x);
String x1 = new String(decode(x));
System.out.println("解码后:" + x1);
}
}
运行结果:
编码前:张
编码后:5byg
解码后:张
说明:理解了Base64的编码解码过程,那么代码也很好理解。
五、总结
经过此篇博文,对字符编码的理解更深刻了,明白了字符编码之间的如何进行转化,有了这个基础后,再看其他与字符编码相关的知识将更容易,特此记录,以后遇到与字符编码相关的问题还会进行记录。谢谢各位园友观看~
【字符编码】字符编码 && Base64编码算法的更多相关文章
- 关于字符,字节与base64编码的理解
字符是用来显示的,如中文字符,英文字符,其类型我字符(串)类型: 字节是用来存储的,一个字节为8bit.由于字节是8位,无法对中文编码,因此诸如a=b'中文'的写法是错误的.但英文标点数字是可以的,如 ...
- php和js中,utf-8编码转成base64编码
1.php下转化base64编码 php中,文本文件的编码决定了程序变量的编码,比如以下代码在不同编码的php文件中,展示的效果也是不一样的 <?php $word = '严'; echo ba ...
- 计算机编码规则之:Base64编码
目录 简介 Base64和它的编码原理 Base64的变体 Base64的编码细节 总结 简介 我们知道计算机中的文件可以分为两种,一种是人肉眼可读的文本类文件,一种是肉眼不可读的二进制文件.一般来说 ...
- Base64编码 图片与base64编码互转
package com.education.util; import sun.misc.BASE64Decoder; import sun.misc.BASE64Encoder; import jav ...
- memortstream Base64编码和filestream base64编码不同
memorystream base64 function BaseImage(fn: string): string; var m1: TMemoryStream; m2: TStringSt ...
- 刨根究底字符编码之十一——UTF-8编码方式与字节序标记
UTF-8编码方式与字节序标记 一.UTF-8编码方式 1. 接下来将分别介绍Unicode字符集的三种编码方式:UTF-8.UTF-16.UTF-32.这里先介绍应用最为广泛的UTF-8. 为满足基 ...
- BASE64编码原理分析脚本实现及逆向案例
在互联网中的每一刻,你可能都在享受着Base64带来的便捷,但对于Base64的基础原理你又了解多少?今天小编带大家了解一下Base64编码原理分析脚本实现及逆向案例的相关内容. 01编码由来 数 ...
- URL编码和Base64编码 (转)
我们经常会遇到所谓的URL编码(也叫百分号编码)和Base64编码. 先说一下Bsae64编码.BASE64编码是一种常用的将二进制数据转换为64个可打印字符的编码,常用于在通常处理文本数据 ...
- base64编码解码原理
计算机只能处理数字,所以要处理任何文本,只能先将文本转化为数字才行. Bit(bit)(b) 位或比特,是计算机运行的基础,属于二进制的范畴.数据传输大多是以[位]为单位,一个位即代表一个0或者1(即 ...
- Base64图片编码原理,base64图片工具介绍,图片在线转换Base64
Base64图片编码原理,base64图片工具介绍,图片在线转换Base64 DataURI 允许在HTML文档中嵌入小文件,可以使用 img 标签或 CSS 嵌入转换后的 Base64 编码,减少 ...
随机推荐
- nodejs学习之加密
Nodejs中的加密是Crypto模块, 1.md5的使用 var crypto = require("crypto"); //创建 var md5 = crypto.create ...
- php将html转成word文档下载
<meta charset="utf-8" /> <?php class word{ function start(){ ob_start(); echo '&l ...
- POI
一.简介 POI(Point of Interest),中文可以翻译为“兴趣点”.在地理信息系统中,一个POI可以是一栋房子.一个商铺.一个邮筒.一个公交站等. 1.POI检索 百度地图SDK提供三种 ...
- 4.Powershell交互界面
Powershell提供两种接口:交互式和自动化脚本 先学下如何与Powershell Console和平共处,通过Powershell Console和机器学会对话. 通过以上一个简单测试,知道Po ...
- vs中“Stack around the variable was corrupted”的解决方案
把 project->配置属性->c/c++->代码生成->基本运行时检查 为 默认值 就不会报本异常.具体原因正在研究中... 如果改为其他就有exception. exce ...
- for循环后面跟分号 - for (i = 0; i <= 3; i++);这不是错误语句
#include<iostream> int main() { using namespace std; ; ; i <= ; i++); t = t + i; cout <& ...
- ASP.NET SignalR 高可用设计
在 One ASP.NET 的架构图中,微软将 WebAPI 和 SignalR 归类到 Services 类型与 MVC.Web Forms 同列为一等公民,未来的 ASP.NET 5 尽管还在be ...
- nodejs事件轮询详述
目录 概述 nodejs特点 事件轮询 关于异步方法 概述 关于nodejs的介绍网上资料非常多,最近由于在整理一些函数式编程的资料时,多次遇到nodejs有关的内容.所以就打算专门写一篇文章总结一下 ...
- [译]Asp.net MVC 之 Contorllers(一)
Asp.net MVC contorllers 在Ajax全面开花的时代,ASP.NET Web Forms 开始慢慢变得落后.有人说,Ajax已经给了Asp.net致命一击.Ajax使越来越多的控制 ...
- dofile执行ANDROID APK里面的文件
我使用dofile执行APK文件是不行的,比如 dofile("assets/res/flist")只能先拷贝到writablePath然后再dofile拿到数据后再清除这个临时文 ...