python之大作业
一、题目要求
获得网页中A-Z所有名字并且爬取名字详情页中的信息,如姓名,性别,,说明等,并存放到csv中(网址:http://www.thinkbabynames.com/start/0/A)
现在得到了所要的信息,但是还没有存入csv中
网页截图:
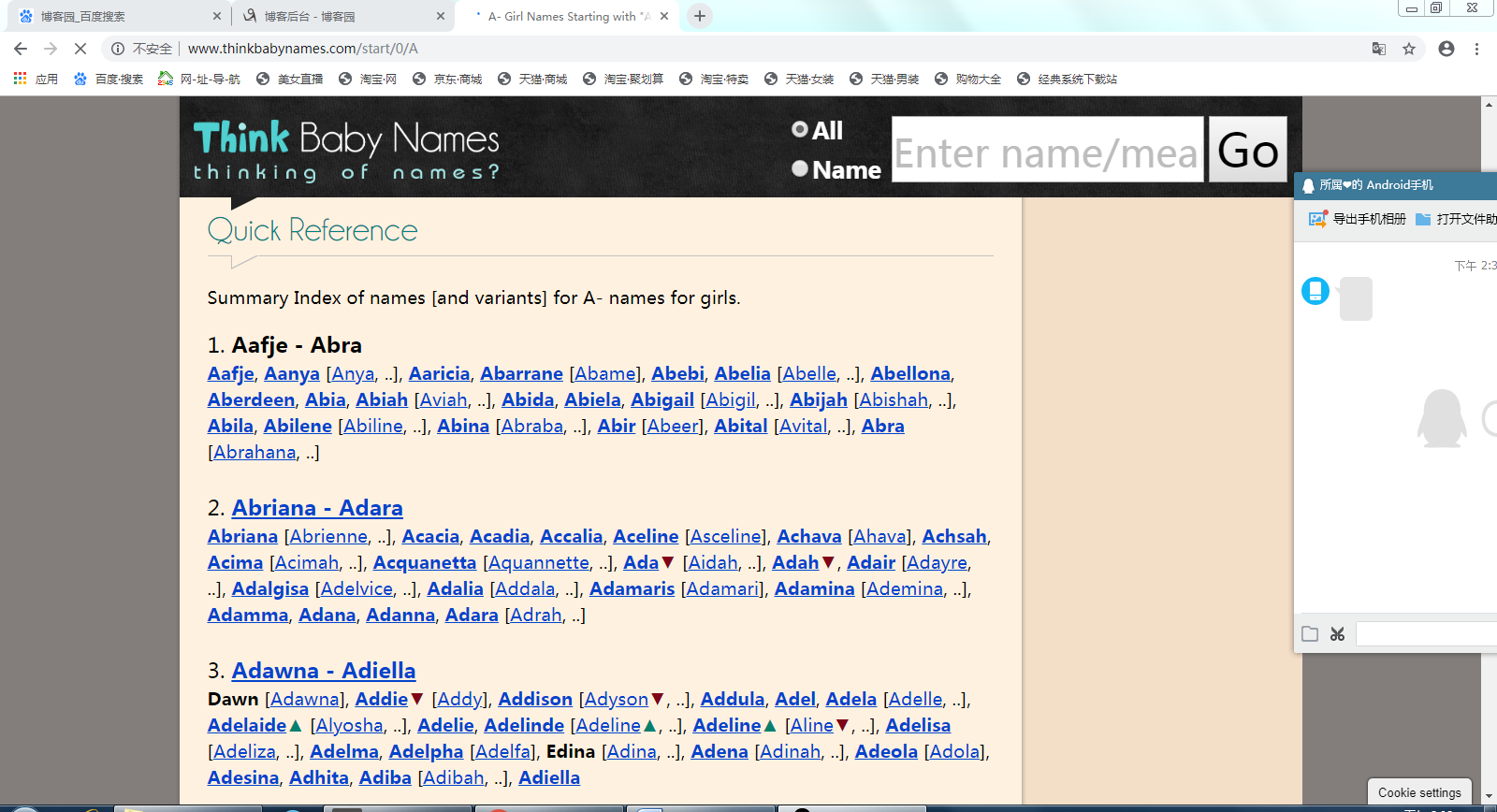

二、题目分析以及解答
首先要获得从A-Z网页连接,规律为只有最后一个字母改变,所以代码如下:
def get_url():#得到A-Z所有网站
urls=[]
for i in range(1, 27):
i = chr(i+96)
urls.append('http://www.thinkbabynames.com/start/0/%s'%i)
return urls
pass
利用循环得到从A-Z所有网页链接,然后再爬取所有名字,名字详情页的连接以及所需内容,代码如下:
def parse_html(url):#得到所有名字以及连接,爬取所需内容
docx=requests.get(url)
soup=BeautifulSoup(docx.content,'html.parser')
c_txt1=soup.find('section',{'id':'index'}).findAll('b')
url=[]
for x in c_txt1:
if x.find('a'):
i=x.find('a')['href'].split("/")[-1]#使用正则表达式获得所有名字
url.append('http://www.thinkbabynames.com/meaning/0/%s'%i)#获得所有名字详情页链接
r=requests.get('http://www.thinkbabynames.com/meaning/0/%s'%i)
result=r.text
bs=BeautifulSoup(result,'html.parser')
li=bs.find('div',class_='content').find('h1')
print("EnNama:")
Enname=li.text[8::1]#使用切片语法获得详情页名字(s[x:y:z]x为起始,y为终止,z为步长)
print(Enname)
print("Gender:")
Gender=li.text[1:8:1]#使用切片语法获得详情页名字
print(Gender)
li1=bs.find('section',id='meaning').find('p')
print("Description:")
Description=li1.text
print(Description)
print()
pass
运行结果部分截图:
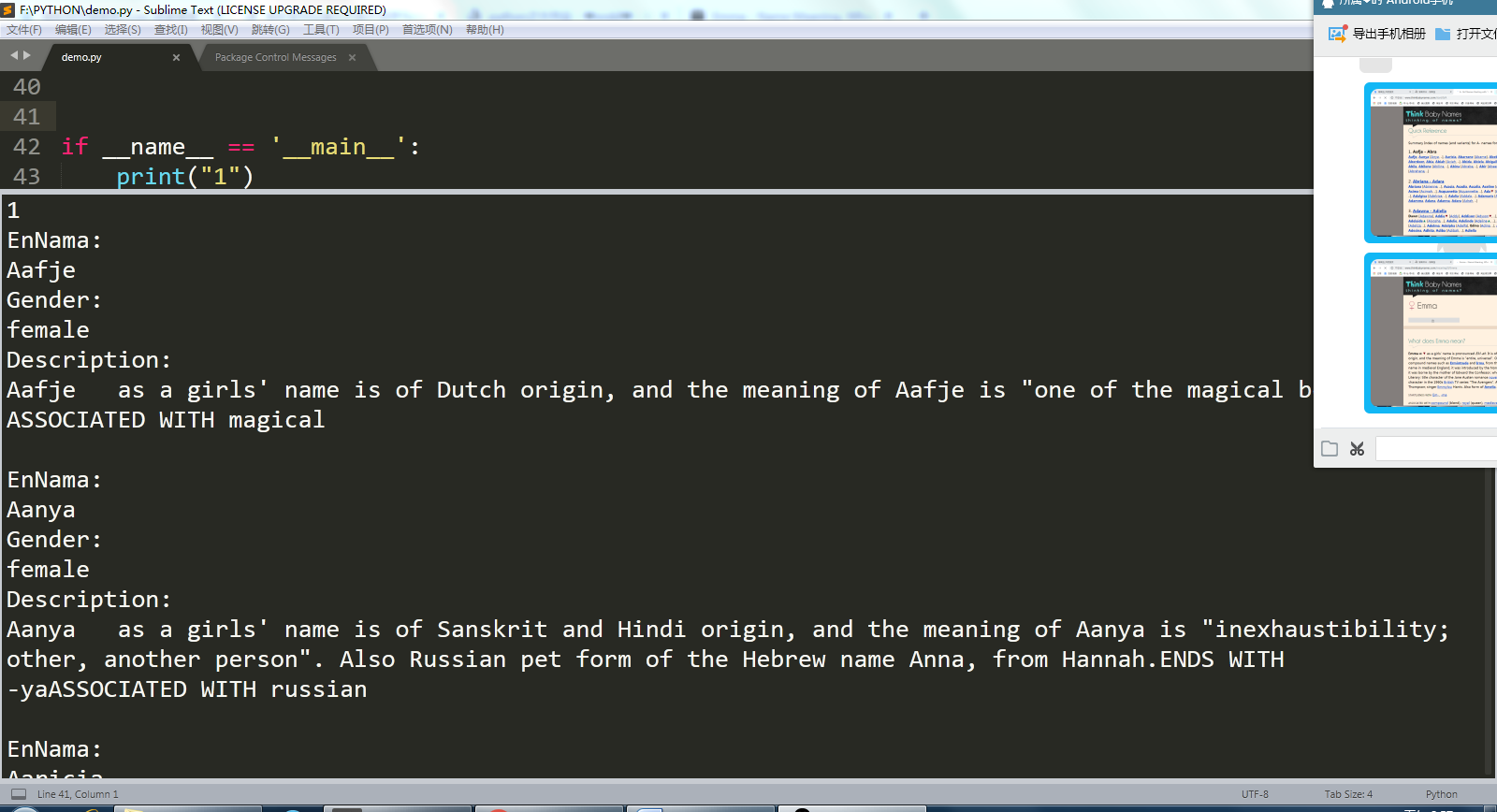
下一步操作是把爬取到的信息存到csv中,正在努力中。
python之大作业的更多相关文章
- python ATM大作业之alex思路
一 ATM alex想了一个思路,就是定义一个函数,这个函数可以实现所有的atm的功能:取款,转账,消费等等. 为了实现这个想法,alex构建了一个两级字典,厉害了.我发现,厉害的人都喜欢用字典.这里 ...
- Python爬虫大作业
一.题目: 获取并保存目标网站的下图所示的所有英文名,网页转换通过点击more names刷新名字并将各个英文名子目录下,去获取并保存每一个英文名的名字.性别.寓意.简介如下图所示内容红色标记框内的内 ...
- 数据库大作业--由python+flask
这个是项目一来是数据库大作业,另一方面也算是再对falsk和python熟悉下,好久不用会忘很快. 界面相比上一个项目好看很多,不过因为时间紧加上只有我一个人写,所以有很多地方逻辑写的比较繁琐,如果是 ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 爬虫综合大作业——网易云音乐爬虫 & 数据可视化分析
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 爬虫综合大作业 选择一个热点或者你感兴趣的主题. 选择爬取的对象 ...
- 基于python复制蓝鲸作业平台
前言 去年看武sir代码发布的视频无意中听到了蓝鲸平台但是一直没深究,前一段时间公司要搞一个代码发布平台,但是需求变化很多一直找不到一个很好的参考 模板,直到试用了一下蓝鲸作业平台发现“一切皆作业”的 ...
- 【大数据应用技术】作业十二|Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 前言 本次作业是在<爬虫大作业>的基础上进行的 ...
- 程设大作业xjb写——魔方复原
鸽了那么久总算期中过[爆]去[炸]了...该是时候写写大作业了 [总不能丢给他们不会写的来做吧 一.三阶魔方的几个基本定义 ↑就像这样,可以定义面的称呼:上U下D左L右R前F后B UD之间的叫E,LR ...
- 大作业NABC分析结果
大作业NABC分析结果 这次的大作业计划制作一款关于七巧板的游戏软件.关于编写的APP的NABC需求分析: N:需求 ,本款软件主要面向一些在校的大学生,他们在校空闲时间比较多,而且热衷于一些益智类游 ...
随机推荐
- Git实战指南----跟着haibiscuit学Git(第三篇)
笔名: haibiscuit 博客园: https://www.cnblogs.com/haibiscuit/ Git地址: https://github.com/haibiscuit?tab=re ...
- sqlserver默认隔离级别下并发批量update同一张表引起的死锁
提到死锁,最最常规的场景之一是Session1 以排它锁的方式锁定A表,请求B表,session2以排它锁的方式锁定B表,请求A表之类的,访问顺序不一致导致死锁的情况本文通过简化,测试这样一种稍显特殊 ...
- Chrome 开发者工具实用操作
Chrome 开发者工具实用操作 https://umaar.com/dev-tips/
- centos8 yum 安装 rabbitmq
进入/etc/yum.repos.d/ 文件夹创建rabbitmq-erlang.repo 文件内容如下[rabbitmq-erlang] name=rabbitmq-erlangbaseurl=ht ...
- Node接口实现HTTPS版的
最近由于自己要做一个微信小程序,接口地址只能是https的,这就很难受了 于是乎,我租了个服务器,搞了个免费的ssl认证 可是呢,我不会搞https接口怎样实现 今天特意花了一天时间来学,来学习 &q ...
- Map随笔:最常用的Map——HashMap
目录 Map随笔:最常用的Map--HashMap 前言: 1,HashMap的结构 2,HashMap的一些属性(JDK8) 3,HashMap的构造函数(JDK8) 4,HashMap的一些方法( ...
- 划分为k个相等的子集
给定一个整数数组 nums 和一个正整数 k,找出是否有可能把这个数组分成 k 个非空子集,其总和都相等. 示例 1: 输入: nums = [4, 3, 2, 3, 5, 2, 1], k = 4 ...
- JQuery解决鼠标单双击冲突问题
转自链接:https://www.shuzhiduo.com/A/xl560MKrzr/ 在jQuery的事件绑定中,如果元素同时绑定了单击事件(click)和双击事件(dblclick),那么执行单 ...
- maxwell实时同步mysql中binlog
概述 Maxwell是一个能实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis.RabbitMQ.Redis.Google Cloud ...
- PHP 实现精确统计在线人数功能
有需要学习交流的友人请加入交流群的咱们一起,有问题一起交流,一起进步!前提是你是学技术的.感谢阅读! 点此加入该群jq.qq.com PHP对session对象的封装的很好,根据HTTP协议,每个范 ...