流式计算(二)-Kafka Stream
前面说了Java8的流,这里还说流处理,既然是流,比如水流车流,肯定得有流的源头,源可以有多种,可以自建,也可以从应用端获取,今天就拿非常经典的Kafka做源头来说事,比如要来一套应用日志实时分析框架,或者是高并发实时流处理框架,正是Kafka的拿手好戏。
环境:Idea2019.03/Gradle6.0.1/JDK11.0.4/Lambda/RHEL8.0/VMWare15.5/Springboot2.2.1.RELEASE/Zookeeper3.5.5/Kafka2.3.1
难度:新手--战士--老兵--大师
目标:
- 理解kafka原理
- Linux下kafka集群安装
- 使用kafka操作流式处理
说明:
为了遇见各种问题,同时保持时效性,我尽量使用最新的软件版本。代码地址:其中的day23,https://github.com/xiexiaobiao/dubbo-project.git
第一部分——原理
1.先看看Kafka,目前kafka的发展已超出消息中间件的范畴,趋于向流平台靠拢,先总结如下:
1.1 Scala语言编写,若作为消息中间件,并发10W+级别,大于其他MQ;
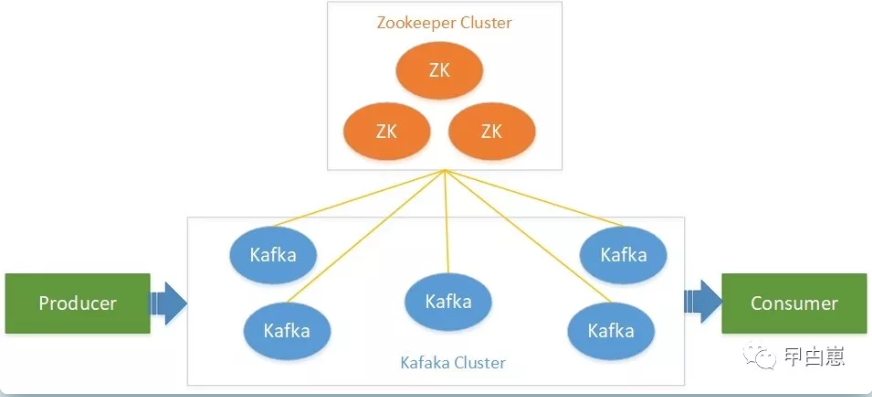
1.2 必须有Zookeeper做协调,ZK保存消费者/生产者状态信息,使得两端非常轻量化;使用发布/订阅模式,所有消息按主题(topic)分类,使用pull模式消费消息;
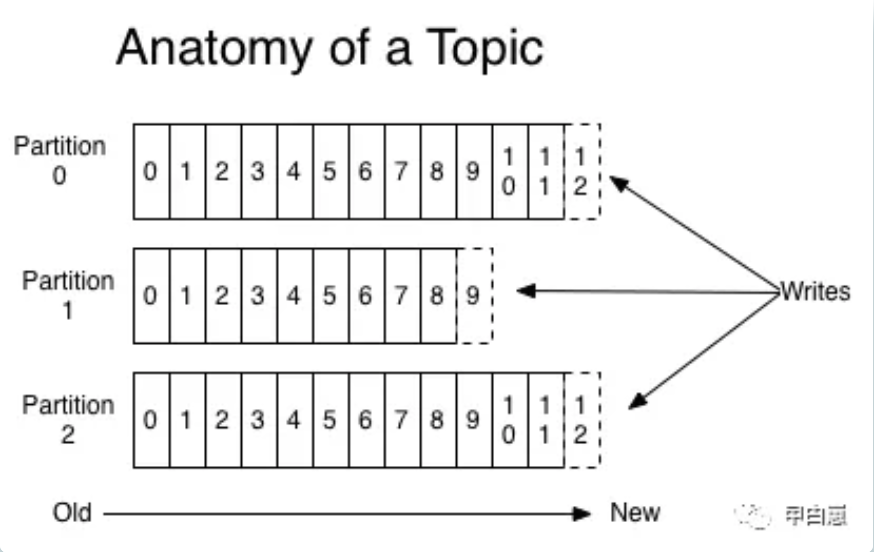
1.3 每条消息由key + value + timestamp构成,其中key用于计算目的发送分区(partition),消息记录由不可变(immutable)的顺序式Append log文件持久化消息,Append写方式是高吞吐率的重要支撑之一!偏移量(offset)标识消息在文件中的位置,下图来自官网:
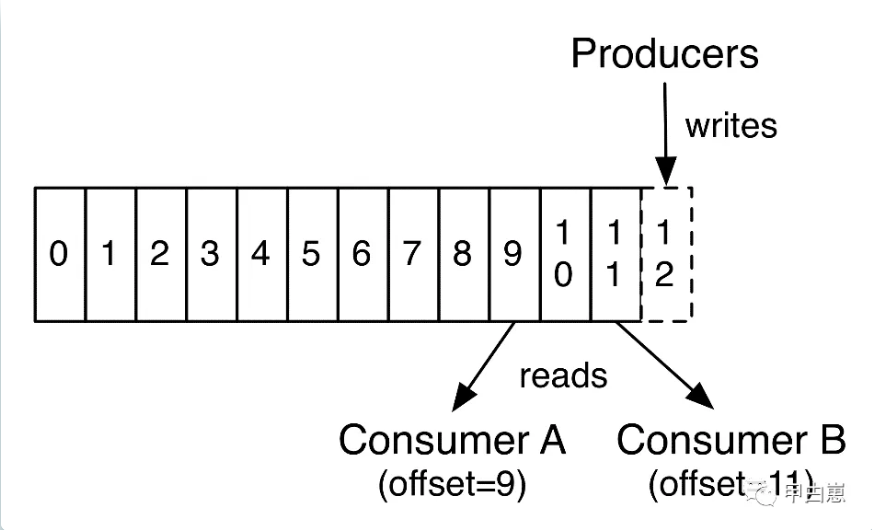
1.4 每条消息不论是否已被消费都将保存一个设定的时间,这是和RabbitMQ的显著差异;消费者仅需保存消息offset信息,可按顺序消费(一个topic只有一个partition),也能进行非顺序式回溯,但随机读写性能差;多个consumer消费互不影响,这也是高并发的支撑之一!下图来自官网:
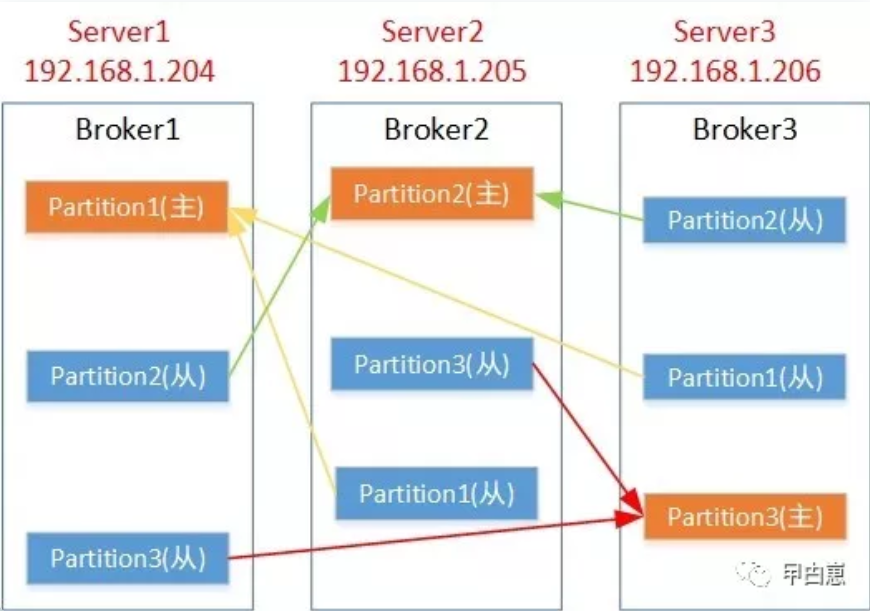
1.5 每个topic的所有消息,均衡(或指定)写入多个分区(partition),分区分布在不同的broker上,每个分区使用主(Leader)+从(Follower)多节点,这样的好处,一是分区文件大小和负载可控,增强单个topic的数据承载量,二是适应并行处理;Leader负责读/写,Followers仅复制备份,Leader不可用时,自动选举Follower转为主:
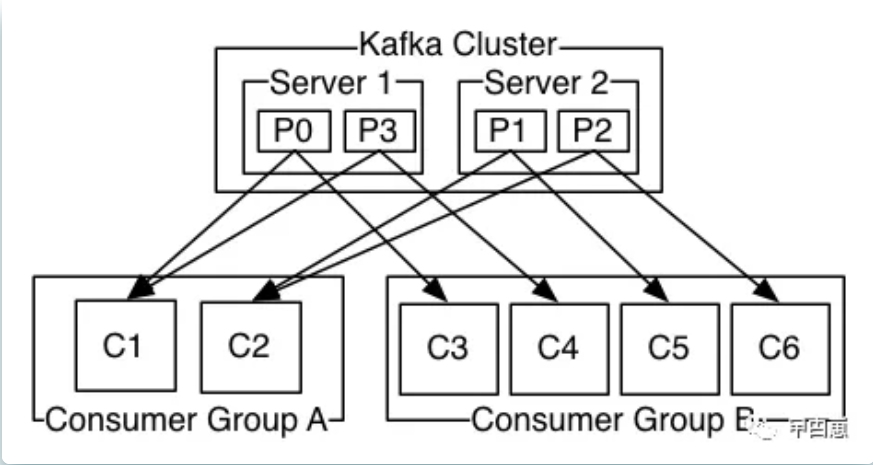
1.6 每个Consumer实例都属于一个消费者组(consumer group),多个Consumer实例可以存在于不同的进程或机器上(Consumer实例可类比于java类的实例对象),一个消息记录只会发送给有对应主题订阅的消费者组中的一个Consumer实例!在一个消费者组中,每个分区至多只能发送到同一消费者的一个实例上,但一个消费者实例可以消费多个分区,因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息,所以分区(partition)数必须大于等于消费者组中的实例数量。下图中,具有2个server的kafka集群,拥有同一个topic的4个分区,并对接2个消费者组,如果A或B组中Consumer都是同一消费者的实例,则轮询均衡消费,若同组都是不同的消费者实例,则相当于广播消息,下图来自官网:
1.7 缺少事务特性,没有接收确认和消费确认ACK机制,也没有RocketMQ的二阶段提交。
1.8 使用场景,下图来自官网,这也让我想起了kafka的几个圈圈的图标:
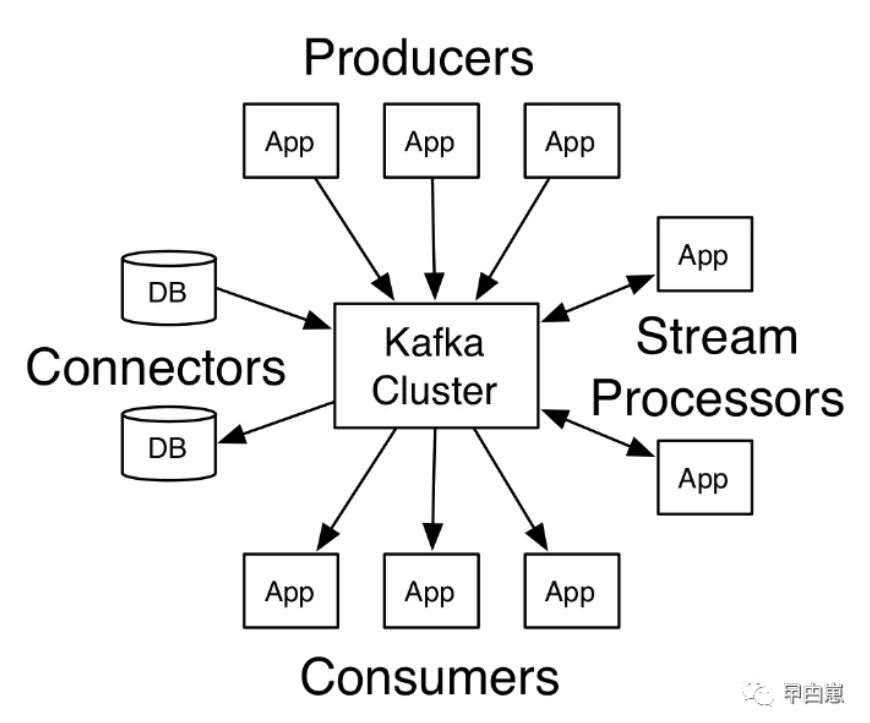
- 常规消息系统:消息系统一般有
queue和publish-subscribe两种模式,queue模式下,多个consumer可以并行地各自处理一部分消息,增加吞吐量和速度,但不能一个消息多分发,因为消息被消费掉就不存在了。publish-subscribe模式下,可以广播一个消息给多个订阅者,但无法扩大吞吐量,kafka的consumer group概念下既能并行也能分发!我认为事实上kafka并没有使用队列这个数据结构,因没有先进先出的概念! - 实时流处理 :对接KstreamAPI,可以实现流式处理,状态计算。
- 分布式流式数据储存:分区+副本的磁盘存储方式可以实现高可用,低延时,大数据量下无性能衰减,kafka还具有仅当所有主从复制全部完成时才算写入成功的确认机制,从而可作为commit log存储系统。
第二部分——安装
虽然window下也可使用kafka,但我想生产环境下都是使用linux,我使用RHEL8.0虚拟机,JDK11的安装,略!

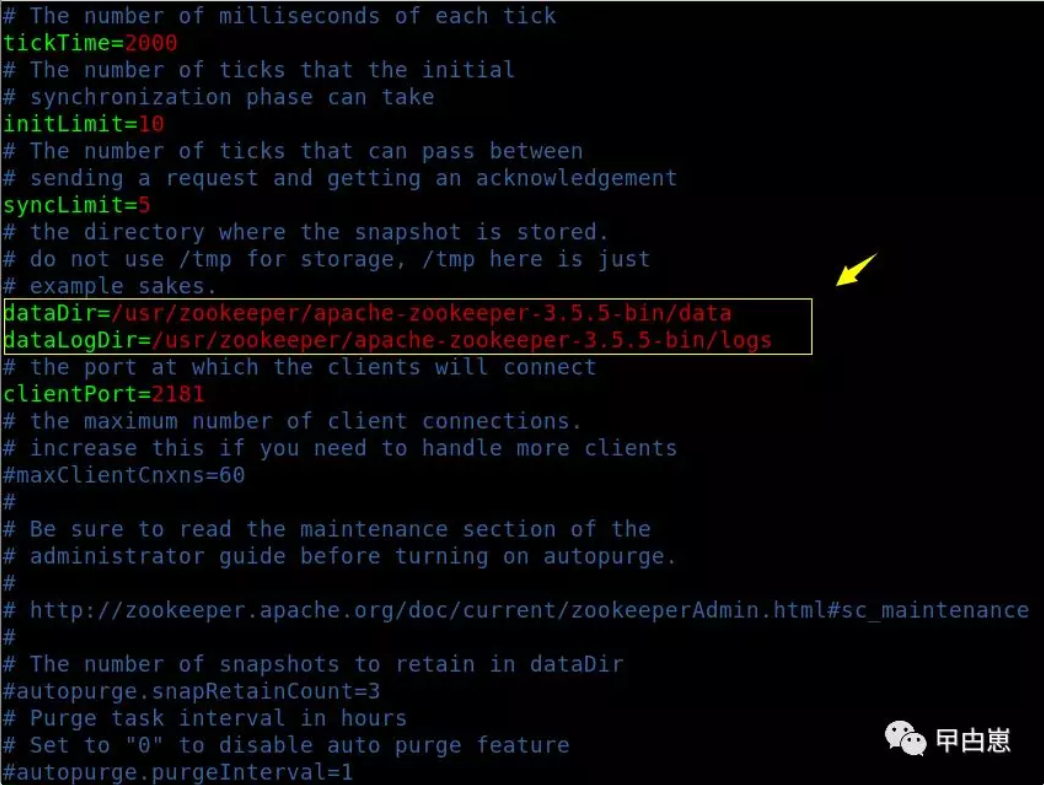
2.1 先进行Zookeeper安装,虽然kafka新版本已经自带ZK,但我还是推荐单独安装ZK,配置和功能独立,步骤比较清晰,且如果是ZK集群,更建议单独配置,为节省篇幅,此部分非重点我就简述了,下载apache-zookeeper-3.5.5-bin.tar.gz,创建/usr/zookeeper目录,cp到该目录,tar命令解压,创建data和logs目录,用于保存zk的数据和log日志,根据zoo_sample.cfg复制一个zoo.cfg文件,并vim编辑如下图,顺带研究下zk的配置:
然后配置linux环境变量,
[root@localhost ~]# vim /etc/profile

保存后使用source命令,使配置生效:
[root@localhost ~]# source /etc/profile
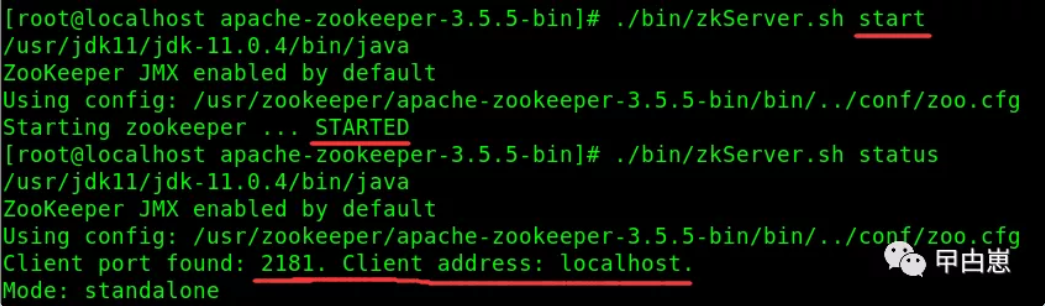
ZK启动命令,会自动使用zoo.cfg配置文件:
[root@localhost apache-zookeeper-3.5.-bin]# ./bin/zkServer.sh start
成功后状态:
其他ZK管理命令:
- /查看服务状态: ./zkServer.sh status
- /停止服务: ./zkServer.sh stop
- /重启服务: ./zkServer.sh restart
- /使用ZKCli连接服务器: ./zkCli.sh -server 127.0.0.1:2181,
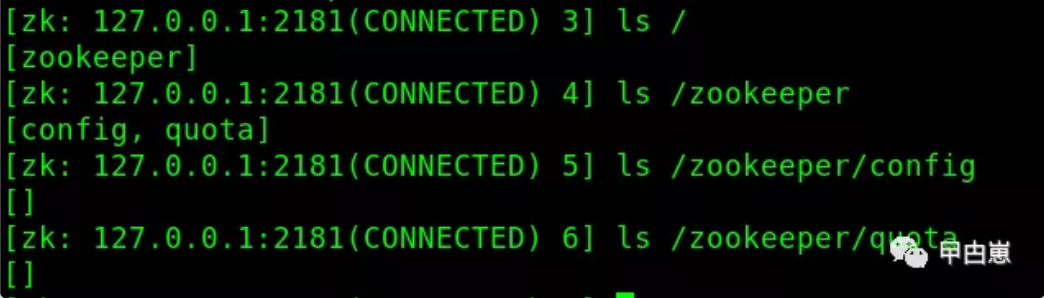
我本地zkCli实例如下:
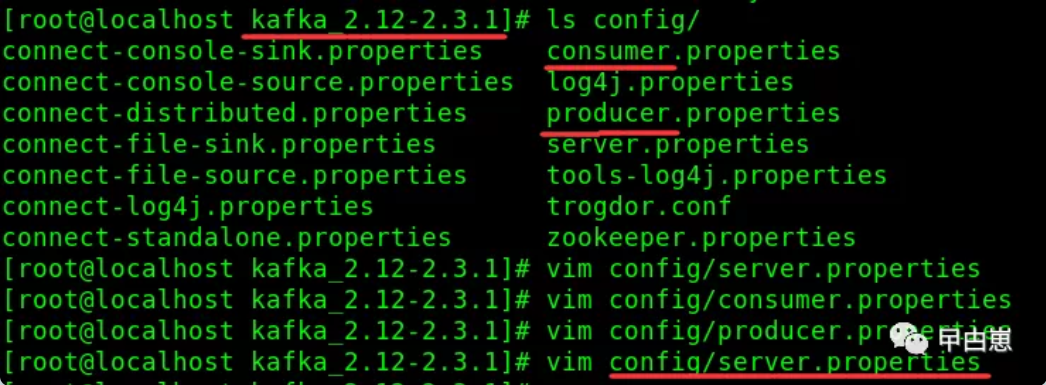
2.2 安装kafka,下载kafka_2.12-2.3.1.tgz,创建/usr/kafka目录,cp到此目录,解压,得到kafka_2.12-2.3.1目录,进入此目录,先看配置,这里有consumer、producer和server三个properties配置文件:
使用命令启动:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-server-start.sh config/ server.properties
如下为启动kafka成功:

再回到zkCli下ls命令查看下,发现创建了很多node,用于保存kafka运行上下文信息:

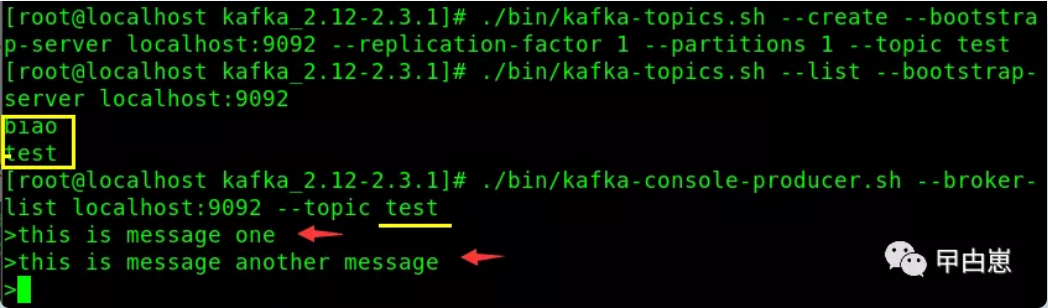
新开一个terminal,创建一个topic,指定replication副本因子为1,即复制0份,分区partitions数量指定为 1:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic biao
列出存在的topic:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-topics.sh --list --zookeeper localhost:

创建另一个topic :
[root@localhost kafka_2.-2.3.]# ./bin/kafka-topics.sh --create --bootstrap-server localhost: --replication-factor --partitions --topic test
下图中创建了一个topic:test,使用本机kafka做集群识别,前面使用zk做集群识别,--bootstrap-server和--zookeeper参数效果一样。再模拟producer,该topic下发送两行消息,默认条件下,每行为一个消息记录:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-console-producer.sh --broker-list localhost: --topic test
再另开一个terminal,模拟consumer,此terminal输出将会和producer输入一致:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-console-consumer.sh --bootstrap-server localhost: --topic test --from-beginning

Ctrl + C 退出程序。

2.3 以上为单ZK单kafka搭建,下面搭建单ZK多kafka实例环境:复制出3份配置文件:
[root@localhost kafka_2.-2.3.]# cp config/server.properties config/server-.properties
[root@localhost kafka_2.-2.3.]# cp config/server.properties config/server-.properties
[root@localhost kafka_2.-2.3.]# cp config/server.properties config/server-.properties
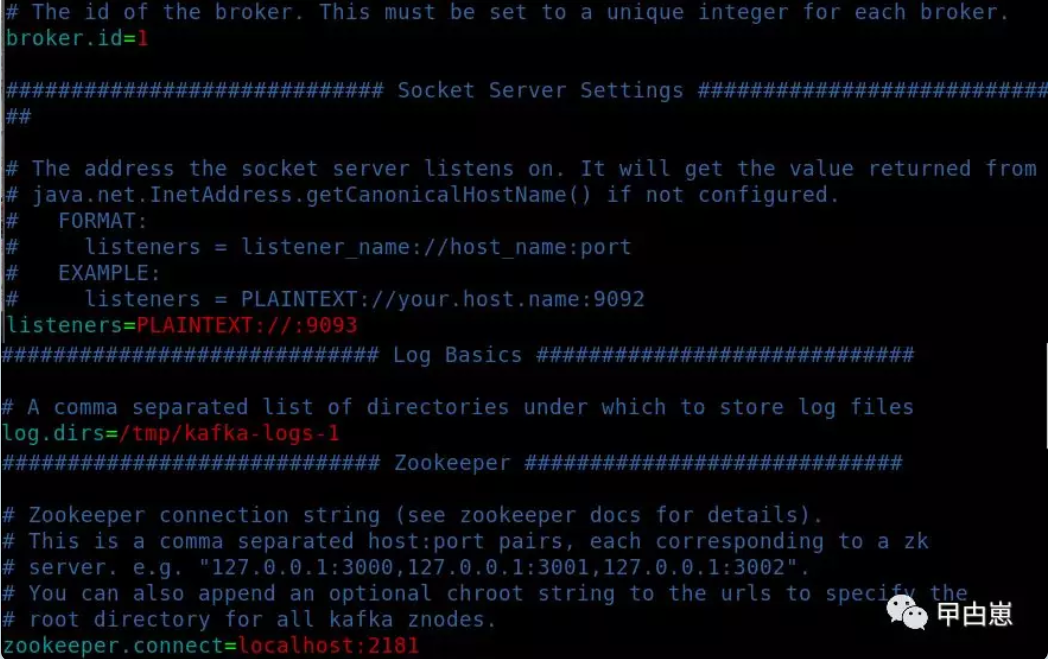
以server-1.properties为例,其他数字依次修改即可:
broker.id= #集群内必须唯一
listeners=PLAINTEXT://:9093 #Socket监听地址,没写hostname/IP即为listen所有IP
log.dirs=/tmp/kafka-logs- #log目录,每个实例独立,防止互相覆盖
zookeeper.connect #ZK注册地址,因为是单ZK,三个实例一样
单独的terminal下创建topic:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-topics.sh --create --bootstrap-server localhost: --replication-factor --partitions --topic my-replicated-topic
这里:指定replication副本因子为3,即复制2份,分区partitions数量指定为1,
查看topic的详细信息:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-topics.sh --describe --bootstrap-server localhost: --topic my-replicated-topic

另一个例子:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-topics.sh --create --bootstrap-server localhost: --replication-factor --partitions --topic replicated-xiao
[root@localhost kafka_2.-2.3.]# ./bin/kafka-topics.sh --describe --bootstrap-server localhost: --topic replicated-xiao

以上每行说明一个partition,
- "Leader":leader节点,负责读写,一个partition下的leader是随机选取的;
- "replicas":列出所有同步保存append log文件的节点,不论主从角色和状态是否有效;
- "isr" :意为"in-sync",即当前有主从同步的有效节点列表;
模拟producer,并输入几行信息:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-console-producer.sh --broker-list localhost: --topic replicated-xiao
>xie
>xiaobiao
>hell world

新terminal下,模拟consumer:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-console-consumer.sh -bootstrap-server localhost: --from-beginning --topic replicated-xiao
Consumer窗口输出内容会和producer窗口输入内容保持一致:

容错测试,关闭broker-1实例:
[root@localhost ~]# ps -aux | grep server-.properties

[root@localhost ~]# kill
或者直接到server-1界面CTRL+C关闭,效果一样:

对比上面的图,可以看到Leader发生变化,Isr 里都没有1了:

再使用consumer读取记录,效果一样,可见容错机制启用了主从替代:

如果再启动server-1,可见主从替换后,不会恢复:

第三部分——应用
创建一个Springboot+gradle项目,命名为kafka-stream02,
3.1 应用测试01:位于包com.biao.kafka下,实现kafka消息的发送和消费:
build.gradle中的核心依赖为:
compile group: 'org.springframework.boot', name: 'spring-boot-starter', version: '2.2.1.RELEASE'
compile group: 'org.springframework.kafka', name: 'spring-kafka', version: '2.3.3.RELEASE'
创建消息发送者com.biao.kafka.Producer:
@Component
//@Slf4j
public class Producer {
@Autowired
private KafkaTemplate<String,String> kafkaTemplate; private Logger log = LoggerFactory.getLogger(Producer.class);
private String time = LocalDateTime.now().toString();
private final String msg = "THIS IS MESSAGE CONTENT " + time; public void send() throws InterruptedException {
log.info("send message is {}",this.msg);
Thread.sleep(1000L);
// kafkaTemplate.sendDefault() 为异步方法,返回 ListenerFuture<T>,
kafkaTemplate.send("HelloWorld","test-key",this.msg);
}
}
以上核心为kafkaTemplate的API, 可以使用kafkaTemplate.send(topic,key,value)同步方法发送消息,或者kafkaTemplate. sendDefault()异步方法发送,
再创建消费者com.biao.kafka.Consumer,使用@KafkaListener注解标识一个topic的监听方法:
@Component
//@Slf4j
public class Consumer { private Logger log = LoggerFactory.getLogger(Consumer.class); @KafkaListener(id = "foo",groupId = "test-consumer-group",topics = "HelloWorld")
public void listen(ConsumerRecord<?,?> records){
Optional<?> msg = Optional.ofNullable(records.value());
if (msg.isPresent()){
Object data = msg.get();
log.info("ConsumerRecord >>>>>> {}", records);
log.info("Record Data >>>>>> {}", data);
}
}
}
创建入口类 com.biao.kafka.KafkaApplication:
@SpringBootApplication
public class KafkaApplication {
public static void main(String[] args) throws InterruptedException {
System.out.println("KafkaApplication started >>>>>>");
ConfigurableApplicationContext context = SpringApplication.run(KafkaApplication.class,args);
Producer producer = context.getBean(Producer.class);
producer.send();
}
}
配置文件application.properties,请关注下Serializer和Deserializer:
#以下这些值也可以在运行时通过参数指定
#============== kafka ===================
# 指定kafka 代理地址,可以多个,用逗号隔开
spring.kafka.bootstrap-servers=192.168.1.204:9092
# 运行com.biao.wordcount.WordCountApplication时使用,我换了一个linux虚拟机
#spring.kafka.bootstrap-servers=192.168.1.221:9092 #=============== provider =======================
spring.kafka.producer.retries=2
# 每次批量发送消息的数量,kafka是使用流模拟批量处理,每次提交都是批处理方式
spring.kafka.producer.batch-size=16384
spring.kafka.producer.buffer-memory=33554432 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer #=============== consumer =======================
spring.kafka.consumer.group-id=test-consumer-group
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=100 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
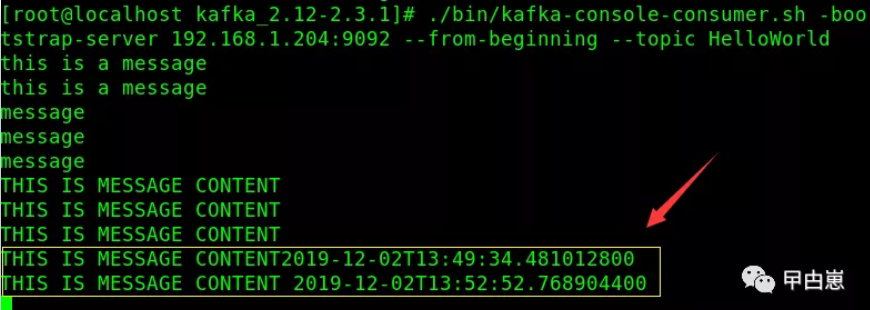
运行程序即可看到结果,这里使用Springboot的DI机制启动运行了consumer和producer,注意关闭linux的防火墙或打开9092端口:

再到kafka服务器上验证一下是否真的发送成功:
[root@localhost kafka_2.12-2.3.1]# ./bin/kafka-console-consumer.sh -bootstrap-server 192.168.1.204:9092 --from-beginning --topic HelloWorld
3.2 应用测试02,包com.biao.pipe下,实现一个流处理逻辑,开启一个流传输管道,将一个topic的内容传输到另一个topic中,代码com.biao.pipe.PipeApplication:
public class PipeApplication {
public static void main(String[] args) {
System.out.println("PipeApplication starting .........");
Properties props = new Properties();
// StreamsConfig已经预定义了很多参数名称,运行时console会输出所有StreamsConfig values
// 这里没有使用springboot的application.properties来配置
props.put(StreamsConfig.APPLICATION_ID_CONFIG,"streams-pipe");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.221:9092");
// kafka流都是byte[],必须有序列化,
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
// kafka流计算是一个各broker连接的拓扑结构,以下使用builder来构造拓扑
final StreamsBuilder builder = new StreamsBuilder();
// 构建一个KStream流对象,元素是<String, String>类型的key-value对值,
KStream<String, String> source = builder.stream("streams-plaintext-input");
// 将前面的topic:"streams-plaintext-input"写入另一个topic:"streams-pipe-output"
source.to("streams-pipe-output");
// 以上两行等同以下一行
// builder.stream("streams-plaintext-input").to("streams-pipe-output");
// 查看具体构建的拓扑结构
final Topology topology = builder.build();
System.out.println(topology.describe());
final KafkaStreams streams = new KafkaStreams(topology,props);
// 控制运行次数,一次后就结束
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try{
streams.start();
latch.await();
}catch (Throwable e){
System.exit(1);
}
System.exit(0);
}
}
注意:以上即使用kafka topic构建了一个KStream流源头,运行输出以下,即为成功,进一步可以在kafka中进行topic写入,再到另一个topic验证输出,我就不演示了。注意配置/usr/kafka2.3/kafka_2.12-2.3.1/config/server.properties中的listeners地址(见后记1):

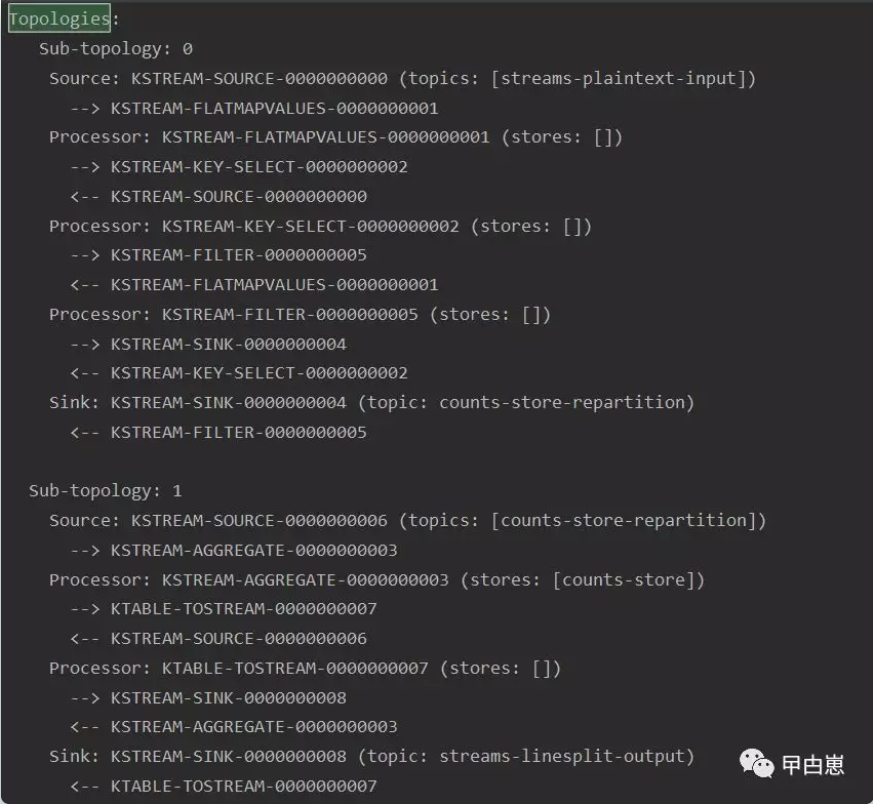
解释:以上构造了有2个处理节点的kafka流计算拓扑结构,源节点:KSTREAM-SOURCE-0000000000,汇聚(Sink)节点:KSTREAM-SINK-0000000001,源节点持续的读取topic为streams-plaintext-input的有序记录并输送到下游Sink节点,Sink节点再将记录写入topic为streams-pipe-output的流,--> 和 <-- 指示左右端对象的上游和下游关系,图中有换行,导致显示不连贯拓扑展示如下:

3.3 应用测试03,包com.biao.linesplit下,创建一个无状态的流处理逻辑,读取一个topic的记录,并将文本行按空格分开,再传输到另一个topic,代码 com.biao.linesplit.LineSplitApplication:
public class LineSplitApplication {
public static void main(String[] args) {
System.out.println("LineSplitApplication starting .........");
Properties props = new Properties();
// StreamsConfig已经预定义了很多参数名称,运行时console会输出所有StreamsConfig values
// 这里没有使用springboot的application.properties来配置
props.put(StreamsConfig.APPLICATION_ID_CONFIG,"streams-line-split");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.221:9092");
// kafka流都是byte[],必须有序列化,不同的对象使用不同的序列化器
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
// kafka流计算是一个各broker连接的拓扑结构,以下使用builder来构造拓扑
final StreamsBuilder builder = new StreamsBuilder();
// 构建一个KStream流对象,元素是<String, String>类型的key-value对值,
KStream<String, String> source = builder.stream("streams-plaintext-input");
/*
// 以source为输入,产生一条新流words,这里使用了流的扁平化语法,我的前篇文章有讲此基础
KStream<String, String > words = source.flatMapValues(value -> Arrays.asList("\\W+"));
// 将前面的topic:"streams-plaintext-input"写入另一个topic:"streams-pipe-output"
words.to("streams-pipe-output");*/
// 以上两行使用stream链式语法+lambda等同以下一行,我的前篇文章有讲此基础
source.flatMapValues(value -> Arrays.asList(value.split("\\W+")))
.to("streams-linesplit-output");
// 查看具体构建的拓扑结构
final Topology topology = builder.build();
System.out.println(topology.describe());
final KafkaStreams streams = new KafkaStreams(topology,props);
// 控制运行次数,一次后就结束
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try{
streams.start();
latch.await();
}catch (Throwable e){
System.exit(1);
}
System.exit(0);
}
}
运行输出以下,即为成功,也可以进一步在kafka上直接进行topic写入和另一个topic输出验证,演示,略!注意配置/usr/kafka2.3/kafka_2.12-2.3.1/config/server.properties中的listeners地址(见后记1):

解释:以上构造了有3个处理节点的kafka流计算拓扑结构,源节点:KSTREAM-SOURCE-0000000000,处理节点:KSTREAM-FLATMAPVALUES-0000000001,汇聚节点:KSTREAM-SINK-0000000002,处理节点从源节点取得流元素,进行处理,再将结果传输给汇聚节点,注意这个过程是无状态的,拓扑展示如下:

3.4 应用测试04,包com.biao.wordcount下,构建一个无限流处理逻辑,读取一个topic,统计文本单词数,最终输出到另一个topic,代码com.biao.wordcount.WordApplication:
public class WordCountApplication {
public static void main(String[] args) {
System.out.println("WordCountApplication starting .........");
Properties props = new Properties();
// StreamsConfig已经预定义了很多参数名称,运行时console会输出所有StreamsConfig values
// 这里没有使用springboot的application.properties来配置
props.put(StreamsConfig.APPLICATION_ID_CONFIG,"streams-word-count");
// kafka虚拟机linux地址
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.221:9092");
// kafka流都是byte[],必须有序列化,不同的对象使用不同的序列化器
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
// kafka流计算是一个各broker连接的拓扑结构,以下使用builder来构造拓扑
final StreamsBuilder builder = new StreamsBuilder();
// 构建一个KStream流对象,元素是<String, String>类型的key-value对值,topic:streams-plaintext-input
KStream<String, String> source = builder.stream("streams-plaintext-input");
// 以下使用stream链式语法+lambda,具体分开的过程语句我就不写了
// flatMapValues将text line使用空格分隔成words
source.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy(((key, value) -> value))
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"))
.toStream()
.to("streams-wordcount-output", Produced.with(Serdes.String(),Serdes.Long()));
// 查看具体构建的拓扑结构
final Topology topology = builder.build();
System.out.println(topology.describe());
final KafkaStreams streams = new KafkaStreams(topology,props);
// 控制运行次数,一次后就结束
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try{
streams.start();
latch.await();
}catch (Throwable e){
System.exit(1);
}
System.exit(0);
}
}
运行输出以下内容,即为成功,注意配置/usr/kafka2.3/kafka_2.12-2.3.1/config/server.properties中的listeners地址(见后记1):
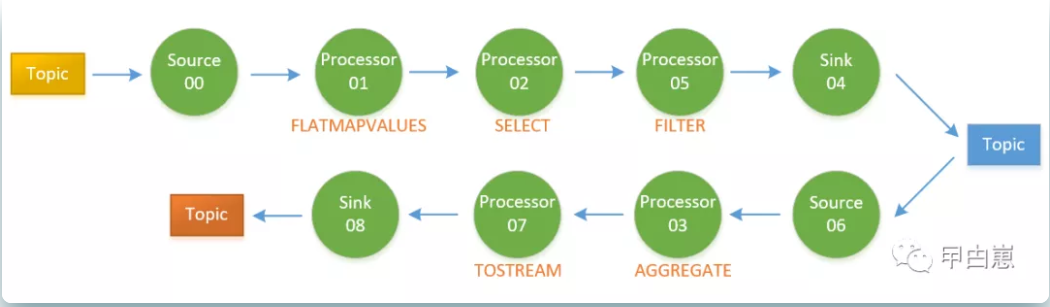
解释:最重要一点即此WordCountApplication仅是一个逻辑处理单元,可以理解为一个流水线车间,里面有两条流水线对来料加工再输出加工品。以上可以看出,有两个不连通的拓扑结构,第一个拓扑无状态,其汇聚节点KSTREAM-SINK-0000000005写入到topic: counts-store-repartition,这个topic又作为第二个拓扑的源,此中间topic的作用是因分组聚合运算”打乱”流元素的顺序。插入的节点Processor: KSTREAM-FILTER-0000000005是过滤掉分组聚合key值为空的记录。
第二个拓扑有状态,即生成并保存了计算中间值,因为要做分组统计,分组聚合运算节点KSTREAM-AGGREGATE-0000000003保存状态使用了counts-store,即程序中指定的值。对流中每个元素统计时,会先去保存的状态数据中去查找匹配,如果有则累加一,然后再写入counts-store。每个被更新的统计值都再传输到处理节点KTABLE-TOSTREAM-0000000007,此节点作用是将统计更新的值再解析成新流。最后传输给汇聚节点KSTREAM-SINK-0000000008。以上可见流处理的思想和逻辑,内部迭代确实很强大!拓扑图如下:
应用04运行步骤:
第一步,启动ZK,再启动kafka,注意先修改config/server.properties 中listeners=PLAINTEXT:// 192.168.1.221:9092:
[root@localhost kafka_2.12-2.3.1]# ./bin/kafka-server-start.sh config/server.properties
第二步,运行com.biao.wordcount.WordCountApplication,启动kafka流处理车间。
topic数据写入放在包com.biao.wordcount.producer,当然也可以直接在kafka server中使用命令行写入,我这里是为了演示多种代码操作模式。配置类com.biao.wordcount.producer.KafkaConfig,这里使用了kafka的API配置方式,分别配置了topic,producer和consumer的相应参数,并生成Bean对象,请对比application.properties方式:
@Configuration
@EnableKafka
public class KafkaConfig { @Bean
public KafkaTemplate<Integer,String > kafkaTemplate(){
return new KafkaTemplate<>(this.producerFactory());
} // topic
@Bean
public KafkaAdmin admin(){
Map<String,Object> configs = new HashMap<>(16);
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.221:9092");
return new KafkaAdmin(configs);
} @Bean
// NewTopic(String name, int numPartitions, short replicationFactor)
// kafka中每个topic只需创建一次,
public NewTopic topic(){
return new NewTopic("streams-plaintext-input",1, (short) 1);
} @Bean
// NewTopic(String name, int numPartitions, short replicationFactor)
// kafka中每个topic只需创建一次,
public NewTopic topic2(){
return new NewTopic("streams-wordcount-output",1, (short) 1);
} // producer
@Bean
public Map<String,Object> producerConfigs(){
Map<String, Object> props = new HashMap<>(16);
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.221:9092");
props.put("acks","all");
props.put("retries",2);
props.put("batch.size",16384);
props.put("linger.ms",1);
props.put("buffer.memory",33554432);
props.put("key.serializer","org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// props.put("key.converter","org.apache.kafka.connect.storage.IntegerConverter");
// props.put("value.converter","org.apache.kafka.connect.storage.StringConverter");
return props;
} @Bean
public ProducerFactory<Integer,String> producerFactory(){
return new DefaultKafkaProducerFactory<>(this.producerConfigs());
} // consumer
@Bean
public Map<String,Object> consumerConfigs(){
HashMap<String,Object> props = new HashMap<>(16);
props.put("bootstrap.servers","192.168.1.221:9092");
props.put("group.id","foo");
props.put("enable.auto.commit","true");
// WordCountApplication 的consumer消费对象是统计的结果 key-value
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.LongDeserializer");
props.put("formatter","kafka.tools.DefaultMessageFormatter");
props.put("print.key","true");
props.put("value.key","true");
// props.put("key.converter","org.apache.kafka.connect.storage.IntegerConverter");
// props.put("value.converter","org.apache.kafka.connect.storage.StringConverter");
return props;
} @Bean
public ConsumerFactory<Integer,String> consumerFactory(){
return new DefaultKafkaConsumerFactory<>(this.consumerConfigs());
} @Bean
public ConcurrentKafkaListenerContainerFactory<Integer,String> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<Integer,String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(this.consumerFactory());
return factory;
} @Bean
public SimpleConsumer simpleConsumerLister(){
return new SimpleConsumer();
}
}
定义消费者,com.biao.wordcount.producer.SimpleConsumer:
@Component
public class SimpleConsumer {
private Logger log = LoggerFactory.getLogger(SimpleConsumer.class);
private final CountDownLatch countDownLatch = new CountDownLatch(1); @KafkaListener(id = "foo",topics = "streams-wordcount-output")
public void listen(byte[] records){
System.out.println("records is >>>> "+ records);
this.countDownLatch.countDown();
log.debug("consume successfully!");
}
//在WordCountApplication实例中,无法打印流结果,因为需要格式化
/* public void listen(ConsumerRecord<?,?> records){
Optional<?> msg = Optional.ofNullable(records.value());
if (msg.isPresent()){
Object data = msg.get();
log.info("Consumer Record >>>>>> {}", records);
log.info("Record Data >>>>>> {}", data);
}
}*/
}
定义生产者,并作为启动类,com.biao.wordcount.producer.KafakaProducer:
@SpringBootApplication
public class KafakaProducer {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(KafkaConfig.class);
// KafkaTemplate<Integer,String> kafkaTemplate = (KafkaTemplate<Integer, String>) context.getBean(KafkaTemplate.class);
KafkaTemplate<Integer,String> kafkaTemplate = (KafkaTemplate<Integer, String>) context.getBean(KafkaTemplate.class);
LocalDateTime time = LocalDateTime.now();
String data = "MSG CONTENT -> " + time ;
// send(String topic, K key, @Nullable V data)
ListenableFuture<SendResult<Integer,String>> send = kafkaTemplate.send("streams-plaintext-input", 1, data);
send.addCallback(new ListenableFutureCallback<SendResult<Integer, String>>() {
@Override
public void onFailure(Throwable ex) {
System.out.println(">>>>>>> kafka message send failure");
} @Override
public void onSuccess(SendResult<Integer, String> result) {
System.out.println(">>>>>>> kafka message send successfully");
}
});
}
}
第三步,运行com.biao.wordcount.producer.KafakaProducer, 启动topic数据写入,kafka中验证如下:

如果多次运行导致测试数据太多,影响结果查看,可以先删除topic及其数据,若当前topic有使用过即有传输过信息:并没有真正删除topic只是把这个topic标记为删除(marked for deletion),要彻底删除需到ZK中删除相应的目录:
[root@localhost kafka_2.12-2.3.1]# ./bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic HelloWorld
Topic HelloWorld is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
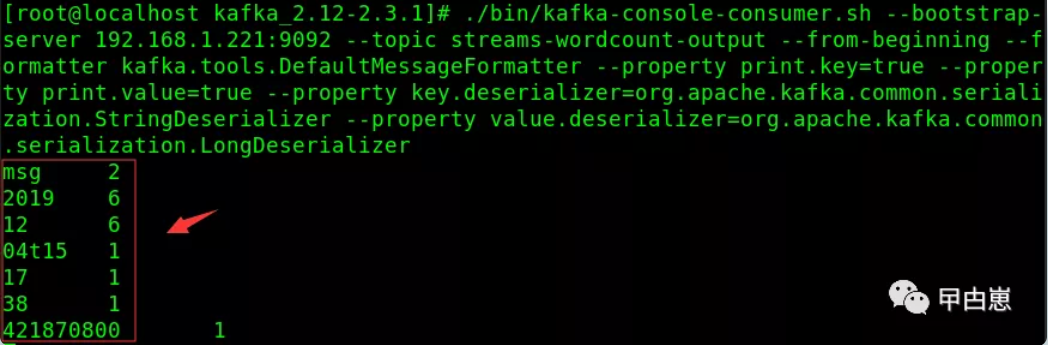
第四步,在kafka server上查看最终word统计结果,命令:
[root@localhost kafka_2.-2.3.]# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.221: --topic streams-wordcount-output --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
后记:
1.关于有状态和无状态,复杂问题简单化!无状态对象本身只是个纯粹的处理逻辑,不依赖上下文信息,也不改变上下文信息,比如FUNC(x+y),只要有输入x和y,就输出相加值,对程序“无害”;有状态指会保留上下文,如统计单词数,必须保留每次计算的中间结果,用于下次累加,有状态对象会破坏程序运行现场,不利于并发和共享。
2.如遇到程序出错:
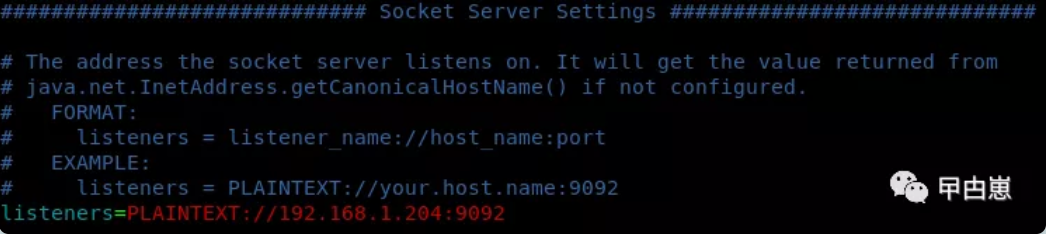
[AdminClient clientId=adminclient-1] Error connecting to node dubbo204.domain:9092 (id: 0 rack: null)
这是因为linux的监听hosts配置引起的,直接修改 config/server.properties中listeners为linux的虚机IP地址即可,并注意关闭linux的防火墙或打开9092端口:
3.添加lombok依赖
providedCompile group: 'org.projectlombok', name: 'lombok', version: '1.18.10'
遇到编译错误:
Could not find method providedCompile() for arguments [{group=org.projectlombok, name=lombok, version=1.18.10}]
因providedCompile必须配合 war插件,修改build.gradle:

4.运行WordCountApplication 报错:
org.apache.kafka.common.errors.SerializationException: Size of data received by IntegerDeserializer is not 4
这是序列化问题,必须使用正确的序列化器处理对应的数据,如IntegerDeserializer只能反序列化Integer对象,StringSerializer用于序列化String对象。
5.RHEL8.0版本可用性还是不错的,比7要流畅很多,很多命令都变了,我开的共享:https://pan.baidu.com/s/19gkx07hQ6TuN9UyNWHmChQ 提取码:bg69,绝对保证可用,之前我也下载了几次都是损坏的,每次6.62G大小,快哭了。
总结:kafka API,分为Producer,Consumer,Stream,Connect和AdminClient。Producer/Consumer分别用于管理生产者和消费者,Stream则是自带的KStream,可以类比JDK8的Stream来理解,即在输出到最终sink前进行流式计算,且很多方法使用类似,Connect是用于kafka连接到输入/输出,支持很多类型,如DB,file,redis,ELK等。AdminClient则管理topic/broker等。KStream+kafka强强联手,可以预计未来会干出一番大事!
推荐阅读:

流式计算(二)-Kafka Stream的更多相关文章
- 流式计算新贵Kafka Stream设计详解--转
原文地址:https://mp.weixin.qq.com/s?__biz=MzA5NzkxMzg1Nw==&mid=2653162822&idx=1&sn=8c4611436 ...
- 第46天学习打卡(四大函数式接口 Stream流式计算 ForkJoin 异步回调 JMM Volatile)
小结与扩展 池的最大的大小如何去设置! 了解:IO密集型,CPU密集型:(调优) //1.CPU密集型 几核就是几个线程 可以保持效率最高 //2.IO密集型判断你的程序中十分耗IO的线程,只要大于 ...
- 流式计算(三)-Flink Stream 篇一
原创文章,谢绝任何形式转载,否则追究法律责任! 流的世界,有点乱,群雄逐鹿,流实在太多,看完这个马上又冒出一个,也不知哪个才是真正的牛,据说Flink是位重量级选手,能流计算,还能批处理, 和其他伙 ...
- kafka 流式计算
http://www.infoq.com/cn/articles/kafka-analysis-part-7/ Kafka设计解析(七)- 流式计算的新贵 Kafka Stream
- 【流处理】Kafka Stream-Spark Streaming-Storm流式计算框架比较选型
Kafka Stream-Spark Streaming-Storm流式计算框架比较选型 elasticsearch-head Elasticsearch-sql client NLPchina/el ...
- jdk8的stream流式计算的操作
jdk8之后增加了流式计算,现在根据学习了流式计算,并把过程记录下来: Person.java的bean package com.zhang.collectordemo; /** * @program ...
- Stream流式计算
Stream流式计算 集合/数据库用来进行数据的存储 而计算则交给流 /** * 现有5个用户,用一行代码 ,一分钟按以下条件筛选出指定用户 *1.ID必须是偶数 *2.年龄必须大于22 *3.用户名 ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- Others-阿里专家强琦:流式计算的系统设计和实现
阿里专家强琦:流式计算的系统设计和实现 更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud 阿里云数据事业部强琦为大家带来题为“流式计算的系统设计与实现”的演讲,本 ...
随机推荐
- error Couldn't find a package.json file in
error Couldn't find a package.json file in解决方法:首先初始化,再安装相应的文件 (1). npm init -f //强迫初始化文件 (2). npm in ...
- 转:关于java.lang.ClassNotFoundException: org.springframework.boot.SpringApplication的解决
在这个控制板中,出现了这个问题 java.lang.ClassNotFoundException: org.springframework.boot.SpringApplication 虽然明显知道是 ...
- 链接脚本(Linker Script)用法解析(一) 关键字SECTIONS与MEMORY
1.MEMORY关键字用于描述一个MCU ROM和RAM的内存地址分布(Memory Map),MEMORY中所做的内存描述主要用于SECTIONS中LMA和VMA的定义. 2.SECTIONS关键字 ...
- 0-N-0计数的优化写法
采用取余%的写法: int i = 0; while( 1 ) { printf( "%d\n", i ); i = ( i + 1 ) % ( N + 1 );}
- (h,v) represent (horizontal,vertical)
函数名h,v 代表 行和列 (horizontal,vertical) numpy 中 hstack 表示横向拼接两个行数相同的数组 In [42]: np.hstack((arr3,arr4)) ...
- 普通莫队--洛谷P1997 【faebdc的烦恼】
离散化+莫队 cnt数组表示某个颜色出现的次数 sum数组表示某个数量出现的颜色种类 其它细节问题就按照莫队的模板来的 #include<cstdio> #include<algor ...
- iOS 音频开发之CoreAudio
转自:http://www.cnblogs.com/javawebsoa/archive/2013/05/20/3089511.html 接 触过IOS音频开发的同学都知道,Core Audio 是I ...
- cd732D Exams 二分
题目:http://codeforces.com/problemset/problem/732/D 题意:给你n,m,n个数,m个数,n天,m场考试,给出n天每天能考第几场考试(如果是0则那天考不了试 ...
- 2018HDU多校二 -F 题 Naive Operations(线段树)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6315 In a galaxy far, far away, there are two integer ...
- 【Go入门学习】理解区分数组和切片
一.前言 学过 Go 的都知道在 Go 语言中有四种复合数据类型:数组.切片(Slice).哈希表(Map)和结构体(Struct),而很多 Go 初学者也很容易把数组和切片弄混淆,所以要怎么把这两个 ...