Non-local Neural Networks 原理详解及自注意力机制思考
Author:Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He (CMU, FAIR)
1 创新点
这篇文章非常重要,个人认为应该算是cv领域里面的自注意力机制的核心文章,语义分割里面引入的各种自注意力机制其实都可以认为是本文的特殊化例子。分析本文的意义不仅仅是熟悉本文,而是了解其泛化思想。
不管是cv还是NLP任务,都需要捕获长范围依赖。在时序任务中,RNN操作是一种主要的捕获长范围依赖手段,而在CNN中是通过堆叠多个卷积模块来形成大感受野。目前的卷积和循环算子都是在空间和时间上的局部操作,长范围依赖捕获是通过重复堆叠,并且反向传播得到,存在3个不足:
(1) 捕获长范围依赖的效率太低;
(2) 由于网络很深,需要小心的设计模块和梯度;
(3) 当需要在比较远位置之间来回传递消息时,这是局部操作是困难的.
故作者基于图片滤波领域的非局部均值滤波操作思想,提出了一个泛化、简单、可直接嵌入到当前网络的非局部操作算子,可以捕获时间(一维时序信号)、空间(图片)和时空(视频序列)的长范围依赖。这样设计的好处是:
(1) 相比较于不断堆叠卷积和RNN算子,非局部操作直接计算两个位置(可以是时间位置、空间位置和时空位置)之间的关系即可快速捕获长范围依赖,但是会忽略其欧式距离,这种计算方法其实就是求自相关矩阵,只不过是泛化的自相关矩阵
(2) 非局部操作计算效率很高,要达到同等效果,只需要更少的堆叠层
(3) 非局部操作可以保证输入尺度和输出尺度不变,这种设计可以很容易嵌入到目前的网络架构中。
2 核心思想
由于我主要做2d图片的CV需求,故本文的大部分分析都是针对图片而言,而不是时间序列或者视频序列。
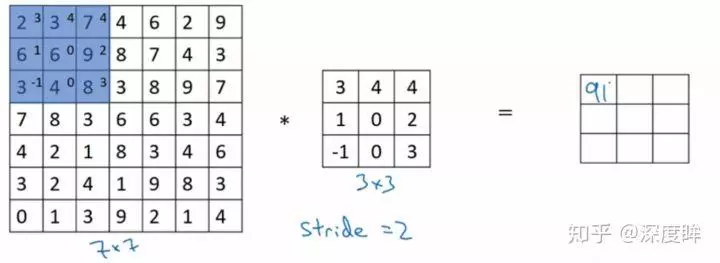
本文的非局部操作算子是基于非局部均值操作而提出的,故很有必要解释下非局部均值操作。我们在CNN或者传统图片滤波算子中涉及的都是局部操作,例如Sobel算子,均值滤波算子等等,其计算示意图如下:
可以看出每个位置的输出值都是kernel和输入的局部卷积计算得到的,而非局部均值滤波操作是: computes a weighted mean of all pixels in an image,非常简单。核心思想是在计算每个像素位置输出时候,不再只和邻域计算,而是和图像中所有位置计算相关性,然后将相关性作为一个权重表征其他位置和当前待计算位置的相似度。可以简单认为采用了一个和原图一样大的kernel进行卷积计算。下图表示了高斯滤波,双边滤波和非局部均值处理过程:
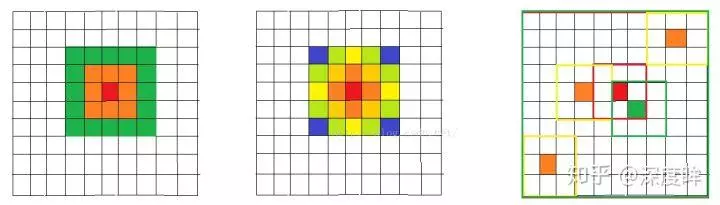
可以看出对于待计算的中心红色点,前两种局部操作都是在邻域计算,而非局部均值是和整个图片进行计算的。但是实际上如果采用逐点计算方式,不仅计算速度非常慢,而且抗干扰能力不太好,故非局部均值操作是采用Block的思想,计算block和block之间的相关性。

可以看出,待计算的像素位置是p,故先构造block,然后计算其他位置block和当前block的相关性,可以看出q1和q2区域和q非常相似,故计算时候给予一个大权重,而q3给予一个小的权重。这样的做法可以突出共性(关心的区域),消除差异(通常是噪声)。

上面的所有分析都是基于非局部操作来讲的,但是实际上在深度学习时代,可以归为自注意力机制Self-attention。在机器翻译中,自我注意模块通过关注所有位置并在嵌入空间中取其加权平均值来计算序列(例如,句子)中的位置处的响应,在CV中那就是通过关注图片中(可以是特征图)所有位置并在嵌入空间中取其加权平均值来表示图片中某位置处的响应。嵌入空间可以认为是一个更抽象的图片空间表达,目的是汇聚更多的信息,提高计算效率。听起来非常高级的样子,到后面可以看出,是非常简单的。
3 网络结构
下面开始给出非局部操作的具体公式。首先在深度学习中非局部操作可以表达为:

i是输出特征图的其中一个位置,通用来说这个位置可以是时间、空间和时空。j是所有可能位置的索引,x是输入信号,可以是图像、序列和视频,通常是特征图。y是和x尺度一样的输出图,f是配对计算函数,计算第i个位置和其他所有位置的相关性,g是一元输入函数,目的是进行信息变换,C(x)是归一化函数,保证变换前后整体信息不变。以上是一个非常泛化的公式,具体细节见下面。在局部卷积算子中,一般的
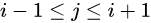
由于f和g都是通式,故结合神经网络特定,需要考虑其具体形式。
首先g由于是一元输出,比较简单,我可以采用1x1卷积,代表线性嵌入,其形式为:

对于f,前面我们说过其实就是计算两个位置的相关性,那么第一个非常自然的函数是Gaussian。
(1) Gaussian
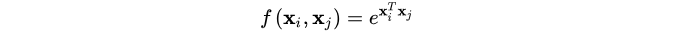
对两个位置进行点乘,然后通过指数映射,放大差异。
(2) Embedded Gaussian
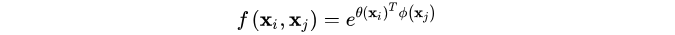
前面的gaussian形式是直接在当前空间计算,而(2)更加通用,在嵌入空间中计算高斯距离。这里:


前面两个:
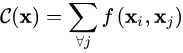
仔细观察,如果把C(x)考虑进去,那么
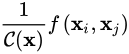
其实就是softmax形式,完整考虑是:
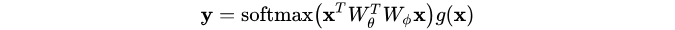
这个就是目前常用的位置注意力机制的表达式,所以说语义分割中大部分通道注意力机制都是本文的特殊化。
(3) Dot product
考虑一种最简单的非局部操作形式:
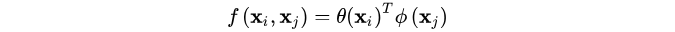
其中C(x)=N,像素个数。可以看出(2) (3)的主要区别是是否含有激活函数softmax。
(4) Concatenation
参考 Relation Networks可以提出:
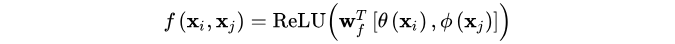
前面是基本的非局部操作算子,利用这些算子,下面开始构造成模块。

可以看出,上面构造成了残差形式。上面的做法的好处是可以随意嵌入到任何一个预训练好的网络中,因为只要设置W_z初始化为0,那么就没有任何影响,然后在迁移学习中学习新的权重。这样就不会因为引入了新的模块而导致预训练权重无法使用。
下面结合具体实例分析:
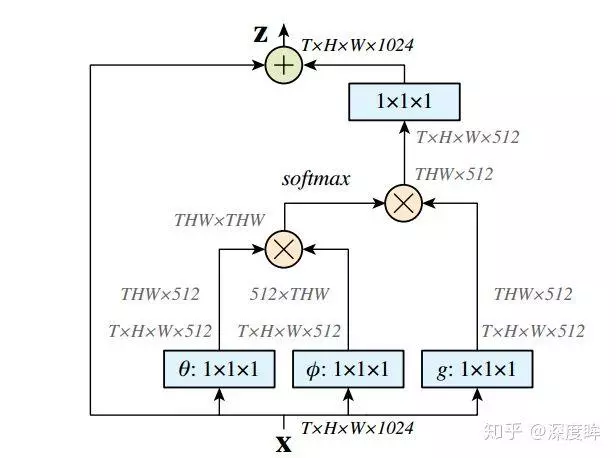
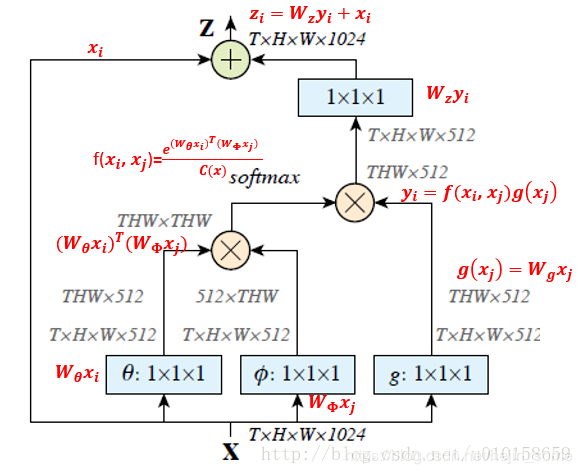
由于我们考虑的是图片,故可以直接设置T=1,或者说不存在。首先网络输入是X= (batch, h, w, 1024) ,经过Embedded Gaussian中的两个嵌入权重变换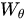 ,
, 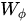 得到(batch, h, w, 512), (batch, h, w, 512), 其实这里的目的是降低通道数,减少计算量;然后分别对这两个输出进行reshape操作,变成(batch, hw, 512),后对这两个输出进行矩阵乘(其中一个要转置),计算相似性,得到(batch, hw, hw),
得到(batch, h, w, 512), (batch, h, w, 512), 其实这里的目的是降低通道数,减少计算量;然后分别对这两个输出进行reshape操作,变成(batch, hw, 512),后对这两个输出进行矩阵乘(其中一个要转置),计算相似性,得到(batch, hw, hw),
然后在第2个维度即最后一个维度上进行softmax操作,得到(batch, hw, hw), 意这样做就是通道注意力,相当于找到了当前图片或特征图中每个像素与其他所有位置像素的归一化相关性;然后将g也采用一样的操作,先通道降维,然后reshape;然后和 (batch, hw, hw)进行矩阵乘,得到(batch, h, w, 512), 即将通道注意力机制应用到了所有通道的每张特征图对应位置上,本质就是输出的每个位置值都是其他所有位置的加权平均值,通过softmax操作可以进一步突出共性。最后经过一个1x1卷积恢复输出通道,保证输入输出尺度完全相同。
4 核心代码实现

拷贝的代码来源:https://github.com/AlexHex7/Non-local_pytorch
可以看出,具体实现非常简单,就不细说了。
5 扩展
通读全文,你会发现思路非常清晰,模块也非常简单。其背后的思想其实是自注意力机制的泛化表达,准确来说本文只提到了位置注意力机制(要计算位置和位置之间的相关性,办法非常多)。
个人认为:如果这些自注意模块的计算开销优化的很小,那么应该会成为CNN的基础模块。既然位置和位置直接的相关性那么重要,那我是不是可以认为graph CNN才是未来?因为图卷积网络是基于像素点和像素点之间建模,两者之间的权重是学习到的,性能肯定比这种自监督方式更好,后面我会写文章分析。
本文设计的模块依然存在以下的不足:
(1) 只涉及到了位置注意力模块,而没有涉及常用的通道注意力机制
(2) 可以看出如果特征图较大,那么两个(batch,hxw,512)矩阵乘是非常耗内存和计算量的,也就是说当输入特征图很大存在效率底下问题,虽然有其他办法解决例如缩放尺度,但是这样会损失信息,不是最佳处理办法。
6 实验
Non-local Blocks的高效策略。我们设置Wg,Wθ,Wϕ的channel的数目为x的channel数目的一半,这样就形成了一个bottleneck,能够减少一半的计算量。Wz再重新放大到x的channel数目,保证输入输出维度一致。
还有一个subsampling的trick可以进一步使用,就是将(1)式变为:yi=1C(x^)∑∀jf(xi,x^j)g(x^j),其中x^是x下采样得到的(比如通过pooling),我们将这个方式在空间域上使用,可以减小1/4的pairwise function的计算量。这个trick并不会改变non-local的行为,而是使计算更加稀疏了。这个可以通过在图2中的ϕ和g后面增加一个max pooling层实现。
我们在本文中的所有non-local模块中都使用了上述的高效策略。
6.1. 视频分类模型
为了理解non-local networks的操作,我们在视频分类任务上进行了一系列的ablation experiments。
2D ConvNet baseline (C2D)。为了独立开non-local nets中时间维度的影响vs 3D ConvNets,我们构造了一个简单的2D baseline结构。
Table 1给出了ResNet-50 C2D backbone。输入的video clip是32帧,大小为224*224。Table 1中的所有卷积都是用的2D的kernel,即逐帧对输入视频进行计算。唯一和temporal有关的计算就是pooling,也就是说这个baseline模型简单地在时间维度上做了一个聚合的操作。 
Inflated 3D ConvNet (I3D)。 Table 1中的C2D模型可以通过inflate的操作转换成一个3D卷积的结构。具体地,一个2D k*k大小的kernel可以inflate成3D t*k*k大小的kernel,只要将其权重重复t次,再缩小t倍即可。
我们讨论2种inflate的方式。一种是将residual block中的3*3的kernel inflate成3*3*3的,另一种是将residual block中的1*1的kernel inflate成3*1*1的。这两种形式我们分别用I3D3∗3∗3和I3D3∗1∗1表示。因为3D conv的计算量很大,我们只对每2个residual blocks中的1个kernel做inflate。对更多的kernel做inflate发现效果反而变差了。另外conv1层我们inflate成5*7*7。
Non-local network。 我们将non-local block插入到C2D或I3D中,就得到了non-local nets。我们研究了插入1,5,10个non-local blocks的情况,实现细节将在后面给出。
6.2 Non-local Network实现细节
Training。 我们的模型是在ImageNet上pretrain的,没有特殊说明的话我们使用32帧的输入。32帧是通过从原始长度的视频中随机选择1个位置取出64个连续帧,然后每隔1帧取1帧得到的最终的32帧。spatial size是224*224大小,是将原始视频rescale到短边为[256,320]区间的随机值,然后再random crop 224*224大小。我们在8卡GPU上进行训练,每卡上有8 clips(也就是说总的batchsize是64 clips)。我们一共迭代了400k iterations,初始lr为0.01,然后每150k iterations lr下降1/10。momentum设为0.9,weight decay设为0.0001。dropout在global pooling层后面使用,dropout ratio设为0.5。
我们finetune模型的时候 BN是打开的,这和常见的finetune ResNet的操作不同,它们通常是frozen BN。我们发现在我们的实验中enable BN有利于减少过拟合。
在最后一个1*1*1 conv层(表示Wz)的后面我们加了一个BN层,其他位置我们没有增加BN。这个BN层的scale参数初始化为0,这是为了保证整个non-local block的初始状态相当于一个identity mapping,这样插入到任何预训练网络中在一开始都能保持其原来的表现。
Inference。 推理时,在我们将视频rescale到短边256进行推理。时域上我们从整个视频中平均采样10个clip,然后分别计算他们的softmax scores,最后做平均得到整个视频的score。
6.3 实验
关于视频分类的实验,我们在Kinetics上进行全面的实验,另外也给出了Charades上的实验结果,显示出我们的模型的泛化性。这里只给出Kinetics上的结果,更多的请看原文。
Table 2给出了ablation results。 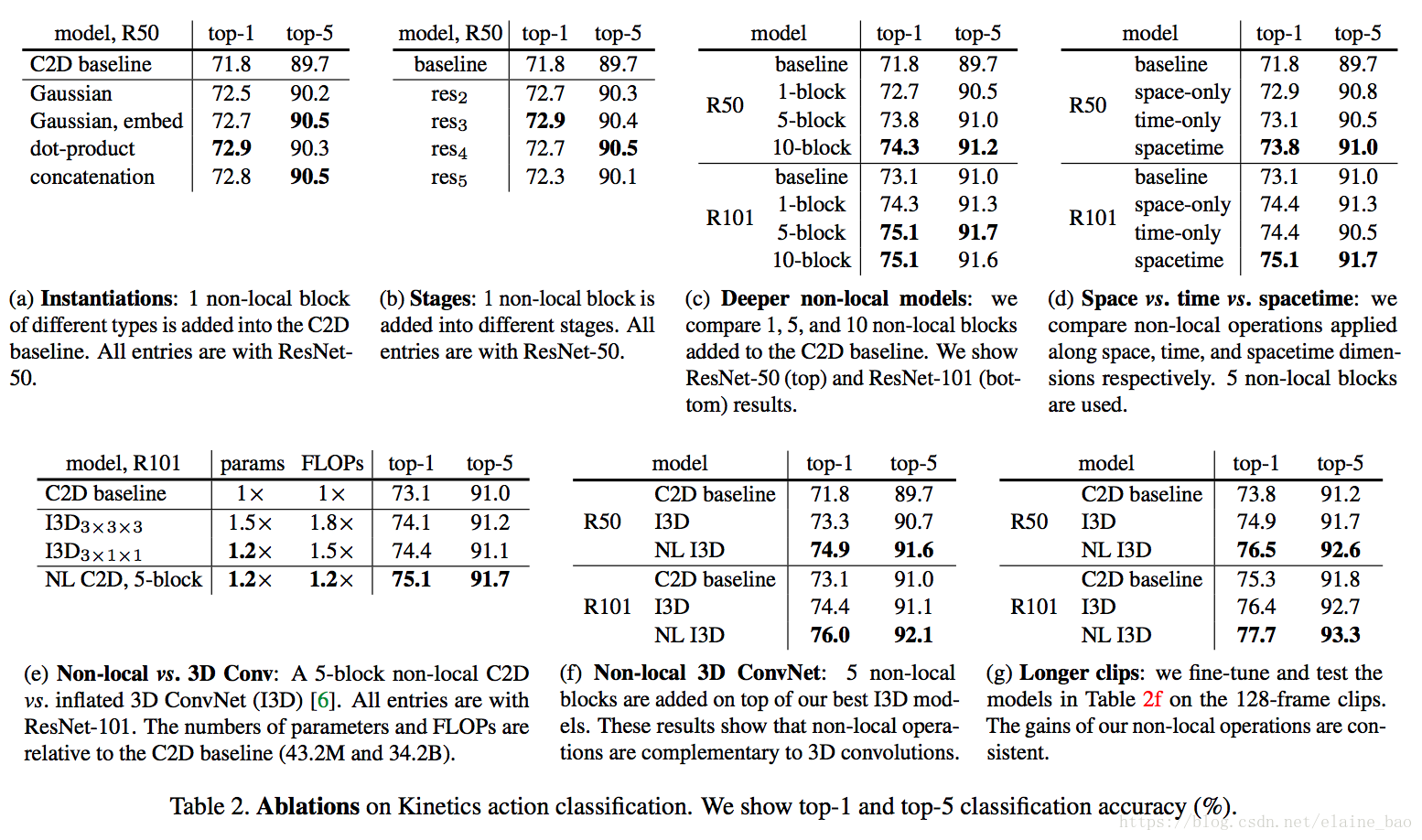
f的表现形式的影响。表2a比较了不同的non-local block的形式插入到C2D得到的结果(插入位置在res4的最后一个residual block之前)。发现即使只加一个non-local block都能得到~1%的提高。
有意思的是不同的non-local block的形式效果差不多,说明是non-local block的结构在起作用,而对具体的表达方式不敏感。本文后面都采用embedded Gaussian进行实验,因为这个版本有softmax,可以直接给出[0,1]之间的scores。
哪个阶段加入non-local blocks?表2b比较了一个non-local block加在resnet的不同stage的效果,具体加在不同stage的最后一个residual block之前。发现在res2,res3,res4层上加non-local block效果类似,加在res5上效果稍差。这个的可能原因是res5的spatial size比较小,只有7*7,可能无法提供精确的spatial信息了。
加入更多的non-local blocks。表2c给出了加入更多non-local block的结果,我们在resnet-50上加1 block(在res4),加5 block(3个在res4,2个在res3,每隔1个residual block加1个non-local block),加10 block(在res3和res4每个residual block都加non-local block)。在resnet101的相同位置加block。发现更多non-local block通常有更好的结果。我们认为这是因为更多的non-local block能够捕获长距离多次转接的依赖。信息可以在时空域上距离较远的位置上进行来回传递,这是通过local models无法实现的。
另外需要提到的是增加non-local block得到的性能提升并不只是因为它给base model增加了深度。为了说明这一点,表2c中resnet50 5blocks能够达到73.8的acc,而resnet101 baseline是73.1,同时resnet50 5block只有resnet101的约70%的参数量和80%的FLOPs。说明non-local block得到的性能提升并不只是因为它增加了深度。
时空域上做non-local。我们的方法也可以处理时空域的信息,这一特性非常好,在视频中相关的物体可能出现在较远的空间和较长的时间,它们的相关性也可以被我们的模型捕获。表2d给出了在时间维度,空间维度和时空维度分别做non-local的结果。仅在空间维度上做就相当于non-local的依赖仅在单帧图像内部发生,也就是说在式(1)上仅对index i的相同帧的index j做累加。仅在时间维度上做也类似。表2d显示只做时间维度或者只做空间维度的non-local,都比C2D baseline要好,但是没有同时做时空维度的效果好。
Non-local net vs. 3D ConvNet。表2e比较了我们的non-local C2D版本和inflated 3D ConvNets的性能。Non-local的操作和3D conv的操作可以看成是将C2D推广到时间维度的两种方式。
表2e也比较了param的数量,FLOPs等。我们的non-local C2D模型比I3D更加精确(75.1 vs 74.4),并且有更小的FLOPs(1.2x vs 1.5x)。说明单独使用时non-local比3D conv更高效。
Non-local 3D ConvNet. 不管上面的比较,其实non-local操作和3D conv各有各的优点:3D conv可以对局部依赖进行建模。表2f给出了在I3D3∗1∗1上插入5个non-local blocks的结果。发现NL I3D都能够在I3D的基础上提升1.6个点的acc,说明了non-local和3D conv是可以相互补充的。
更长的输入序列。 最后我们也实验了更长输入序列的情况下模型的泛化性。输入clip包含128帧连续帧,没有做下采样,是一般情况下取的32帧的4倍长度。为了将这个模型放入显存中,每个GPU上只能放下2 clips。因为这么小的batchsize的原因,我们freeze所有的BN层。我们从32帧训练得到的模型作为初始化模型,然后用128帧进行finetune,使用相同的iterations数目(虽然batchsize减小了),初始lr为0.0025,其他设置和之前保持一致。
表2g给出了128帧的实验结果,和表2f的32帧的结果相比,所有模型都表现得更好,说明我们的模型在长序列上的效果也很好。
和state-of-the-art的比较。表3给出了Kinetics上各个方法的结果。 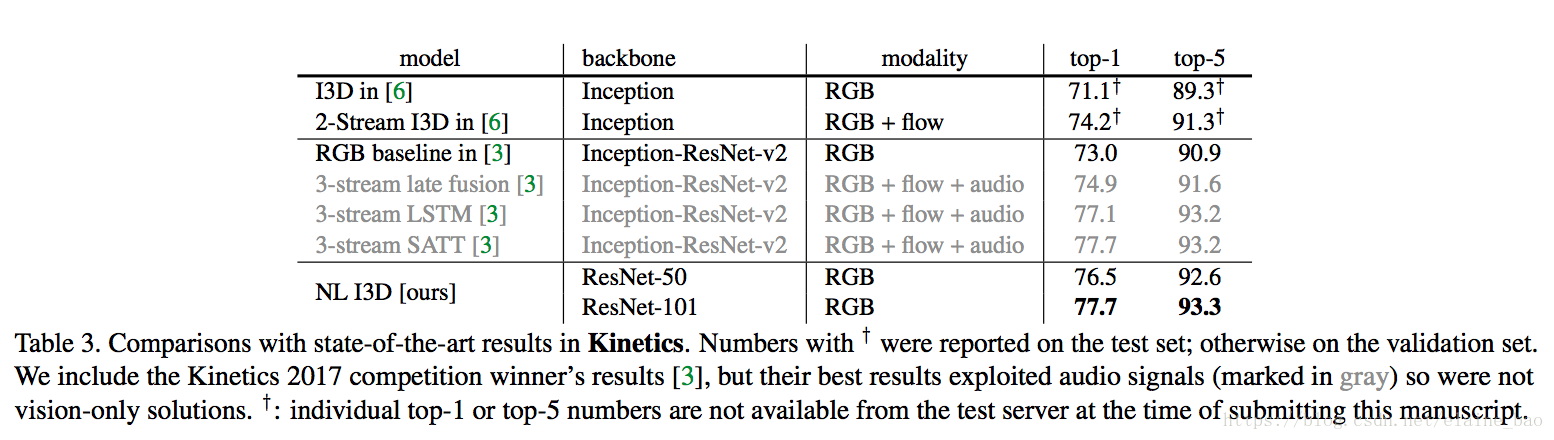
https://www.jianshu.com/p/a9771abedf50
Non-local Neural Networks 原理详解及自注意力机制思考的更多相关文章
- Docker Kubernetes 服务发现原理详解
Docker Kubernetes 服务发现原理详解 服务发现支持Service环境变量和DNS两种模式: 一.环境变量 (默认) 当一个Pod运行到Node,kubelet会为每个容器添加一组环境 ...
- [No0000126]SSL/TLS原理详解与WCF中的WS-Security
SSL/TLS作为一种互联网安全加密技术 1. SSL/TLS概览 1.1 整体结构 SSL是一个介于HTTP协议与TCP之间的一个可选层,其位置大致如下: SSL:(Secure Socket La ...
- Storm概念、原理详解及其应用(一)BaseStorm
本文借鉴官文,添加了一些解释和看法,其中有些理解,写的比较粗糙,有问题的地方希望大家指出.写这篇文章,是想把一些官文和资料中基础.重点拿出来,能总结出便于大家理解的话语.与大多数“wordcount” ...
- NFS原理详解
NFS原理详解 摘自:http://atong.blog.51cto.com/2393905/1343950 2013-12-23 12:17:31 标签:linux NFS nfs原理详解 nfs搭 ...
- 通过 JFR 与日志深入探索 JVM - TLAB 原理详解
全系列目录:通过 JFR 与日志深入探索 JVM - 总览篇 什么是 TLAB? TLAB(Thread Local Allocation Buffer)线程本地分配缓存区,这是一个线程专用的内存分配 ...
- I2C 基础原理详解
今天来学习下I2C通信~ I2C(Inter-Intergrated Circuit)指的是 IC(Intergrated Circuit)之间的(Inter) 通信方式.如上图所以有很多的周边设备都 ...
- Zigbee组网原理详解
Zigbee组网原理详解 来源:互联网 作者:佚名2015年08月13日 15:57 [导读] 组建一个完整的zigbee网状网络包括两个步骤:网络初始化.节点加入网络.其中节点加入网络又包括两个 ...
- 块级格式化上下文(block formatting context)、浮动和绝对定位的工作原理详解
CSS的可视化格式模型中具有一个非常重要地位的概念——定位方案.定位方案用以控制元素的布局,在CSS2.1中,有三种定位方案——普通流.浮动和绝对定位: 普通流:元素按照先后位置自上而下布局,inli ...
- SSL/TLS 原理详解
本文大部分整理自网络,相关文章请见文后参考. SSL/TLS作为一种互联网安全加密技术,原理较为复杂,枯燥而无味,我也是试图理解之后重新整理,尽量做到层次清晰.正文开始. 1. SSL/TLS概览 1 ...
随机推荐
- Java并发编程总结(一)Syncronized解析
Syncronized解析 作用: )确保线程互斥的访问同步代码 )保证共享变量的修改能够及时可见 )有效解决重排序问题. 用法: )修饰普通方法(锁是当前实例对象) )修饰静态方法(锁是当前对象的C ...
- git基础命令详解
一些必须要知道的概念 git的三个工作区域:工作目录.暂存区.git仓库. 工作目录:其实就是本地文件磁盘上的文件或目录: 暂存区:是一个文件,保存了下次提交的文件列表信息,一般在git仓库目录中: ...
- Bran的内核开发教程(bkerndev)-01 介绍
介绍 内核开发不是件容易的事,这是对一个程序员编程能力的考验.开发内核其实就是开发一个能够与硬件交互和管理硬件的软件.内核也是一个操作系统的核心,是管理硬件资源的逻辑. 处理器或是CPU是内核 ...
- Qt5教程: (4) 带参数信号与槽
在subwidget.h中声明一个signal. 和之前的信号函数重名但是有参数: void backSignal(QString); 之后在subwidget.cpp的槽函数sendSignal() ...
- VPS虚拟专用服务器
目录 0x00 VPS服务器概述 0x01 VPS工作原理 0x02 VPS用途 0x03 VPS优势 0x04 VPS特点 0x00 VPS服务器概述 VPS服务器(虚拟专用服务器)(" ...
- Unix 线程改变创建进程中变量的值(2)
执行环境:Linux ubuntu 4.4.0-31-generic #50-Ubuntu SMP Wed Jul 13 00:07:12 UTC 2016 x86_64 x86_64 x86_64 ...
- Java匹马行天下之新手学习目录
Java匹马行天下之新手学习目录 学习路线 [Java匹马行天下——Java学习路线] [Java匹马行天下——开篇学习计划] 基础篇 [Java匹马行天下之学编程的起点——编程常识知多少] [Jav ...
- 页面离开前提示用户(onbeforeunload 事件)
window.onbeforeunload = function (e) { var evt = e || window.event; evt.returnValue = '离开会使编写的内容丢失'; ...
- TwoHandleSlider/RangeSlider
项目需求:双滑块slider,可以实现选择一个范围 (一)添加两个slider,并把背景以及fill设置为透明,并去除RaycastTarget (二)在背景下添加个一个image,背景图为滑块划过后 ...
- iOS 应用签名原理&重签名
在苹果的日常开发中,真机测试与打包等很多流程都会牵扯到各种证书,CertificateSigningRequest,p12等.但是很多相应的开发者并不理解iOS App应用签名的原理和流程.今天着重讲 ...