Ceph 的 'MAX AVAIL' 和 数据平衡 - Storage 6
1. 客户环境
节点数量:4个存储节点
OSD数量:每个节点10块8GB磁盘,总共 40 块OSD
Ceph 版本: Storage 6
使用类型: CephFS 文件
CephFS 数据池: EC, 2+1
元数据池: 3 replication
客户端:sles12sp3
2. 问题描述
客户询问为什么突然少了那么多存储容量?
1) 客户在存储数据前挂载cephfs,磁盘容量显示185T
# df -Th
10.109.205.61,10.109.205.62,10.109.205.63:/ 185T 50G 184T % /SES
2) 但在客户存储数据后,发现挂载的存储容量少了8T,只有177T
# df -Th
10.109.205.61,10.109.205.62,10.109.205.63:/ 177T 50G 184T % /SES
3. 问题分析
从客户获取 “ceph df ”信息进行比较
(1)未存储数据前信息
# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 297 TiB TiB 5.9 TiB 5.9 TiB 1.99
TOTAL TiB TiB 5.9 TiB 5.9 TiB 1.99 POOLS:
POOL ID STORED OBJECTS USED %USED MAX AVAIL
cephfs_data B B TiB
cephfs_metadata 6.7 KiB 3.8 MiB TiB
(2)客户存储数据后信息输出
# ceph df RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd TiB TiB TiB TiB 19.37
TOTAL TiB TiB TiB TiB 19.37 POOLS:
POOL ID STORED OBJECTS USED %USED MAX AVAIL
cephfs_data 34 TiB 9.75M TiB 19.40 TiB
cephfs_metadata 1.0 GiB .23K 2.9 GiB TiB
我们发现客户端挂载显示的存储容量 MAX AVAIL + STORED
(1)存储数据前:185TB = 184 + 0
(2)存储数据后:177TB = 142 + 34 = 176
(3)从中可以发现少掉 7TB 数据量是由 ‘MAX AVAIL’引起的变化
(4)SUSE 知识库中对 MAX AVAIL 计算公式如下:
[min(osd.avail for osd in OSD_up) - ( min(osd.avail for osd in OSD_up).total_size * (1 - mon_osd_full_ratio)) ]* len(osd.avail for osd in OSD_up) /pool.size()
(5)命令 ceph osd df 输出信息
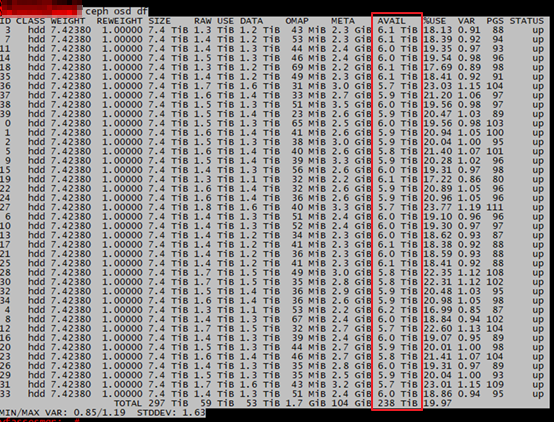
图1
因此可以推算出:
(1)未存储数据之前容量计算:
185 TB (Max avail) = min(osd.avail for osd in OSD_up) * num of OSD * 66.66% * mon_osd_full_ratio = 7.4 * 40 * 66.66% * 0.95= 195 TB * 0.95 =185
(2)存储数据后容量计算
142 TB (MAX avail)= min(osd.avail for osd in OSD_up) * num of OSD * 66.66% * mon_osd_full_ratio = 5.7 * 40 *66.66% * 0.95 = 151 TB * 0.95 = 143
公式解释
1) min(osd.avail for osd in OSD_up):从ceph osd df 中AVAIL一列选择最小值。
- 未存储数据时最小值是7.4TB
- 而存储数据后最小值是5.7TB
2) num of OSD :表示集群中UP状态的OSD数量,那客户新集群OSD数量就40
3) 66.66% : 因为纠删码原因,2+1 的比例
4) mon_osd_full_ratio = 95%
When a Ceph Storage cluster gets close to its maximum capacity (specifies by the mon_osd_full_ratio parameter), Ceph prevents you from writing to or reading from Ceph OSDs as a safety measure to prevent data loss. Therefore, letting a production Ceph Storage cluster approach its full ratio is not a good practice, because it sacrifices high availability. The default full ratio is .95, or 95% of capacity. This a very aggressive setting for a test cluster with a small number of OSDs.
ceph daemon osd. config get mon_osd_full_ratio
{
"mon_osd_full_ratio": "0.950000"
}
4. 解决方案
从上面公式分析,我们可以清楚的看到主要是 MAX AVAIL 的计算公式原因导致存储容量的变化,这是浅层次的分析问题所在,其实在图1中我们可以仔细的发现主要是OSD数据不均匀导致。
- 客户询问我如何才能让数据平衡,我的回答是PG数量计算 和 Storage6 自动平衡功能。
(1)开启ceph 数据平衡
# ceph balancer on
# ceph balancer mode crush-compat
# ceph balancer status
{
"active": true,
"plans": [],
"mode": "crush-compat"
}
(2)数据自动开始迁移
cluster:
id: 8038197f-81a2-47ae-97d1-fb3c6b31ea94
health: HEALTH_OK services:
mon: daemons, quorum yfasses1,yfasses2,yfasses3 (age 5d)
mgr: yfasses1(active, since 5d), standbys: yfasses2, yfasses3
mds: cephfs: {=yfasses4=up:active,=yfasses2=up:active} up:standby
osd: osds: up (since 5d), in (since 5d); remapped pgs data:
pools: pools, pgs
objects: 10.40M objects, TiB
usage: TiB used, TiB / TiB avail
pgs: / objects misplaced (4.243%)
active+clean
active+remapped+backfill_wait
active+remapped+backfilling io:
client: MiB/s rd, MiB/s wr, op/s rd, op/s wr
recovery: 1.0 GiB/s, objects/s
(3)等迁移后基本所有的OSD数据保持差不多数据量
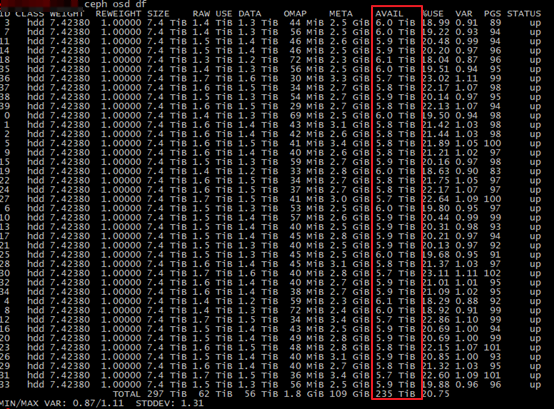
图2
注意:图2截屏时,数据还在迁移中,但可以发现 OSD 之间的数据差距逐渐变小
(4) 客户端挂载显示182TB
等数据迁移完成后,客户端挂载显示182TB
10.109.205.61,10.109.205.62,10.109.205.63:/ 182T 39T 143T % /SES

Ceph 的 'MAX AVAIL' 和 数据平衡 - Storage 6的更多相关文章
- HDFS数据平衡
一.datanode之间的数据平衡 1.1.介绍 Hadoop 分布式文件系统(Hadoop Distributed FilSystem),简称 HDFS,被设计成适合运行在通用硬件上的分布式文件 ...
- HDFS组件性能调优:数据平衡
生产系统中什么情况下会添加一个节点呢? 1 增加存储能力 disk 2 增加计算能力 cpu mem 如果增加是的是存储能力,说明存储已接近饱和或者说过段时间就会没有剩余的空间给作业来用.新加的节点存 ...
- 《Javascript权威指南》学习笔记之十七:BOM新成就(1)--client存储数据(Storage实现)
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/u011043843/article/details/30255899 数据构成了web网站的 ...
- 7.4 k8s结合ceph rbd、cephfs实现数据的持久化和共享
1.在ceph集群中创建rbd存储池.镜像及普通用户 1.1.存储池接镜像配置 创建存储池 root@u20-deploy:~# ceph osd pool create rbd-test-pool1 ...
- Ceph根据Crush位置读取数据
前言 在ceph研发群里面看到一个cepher在问关于怎么读取ceph的副本的问题,这个功能应该在2012年的时候,我们公司的研发就修改了代码去实现这个功能,只是当时的硬件条件所限,以及本身的稳定性问 ...
- vue开发chrome扩展,数据通过storage对象获取
开发chrome插件时遇到一个问题,那就是单文件组件的data数据需要从chrome提供的storage对象中获取,但是 chrome.storage.sync.get 方法是异步获取数据的,需要通过 ...
- ceph-deploy离线部署ceph集群及报错解决FAQ
ceph-deploy部署ceph集群 环境介绍 主机名 ip地址 操作系统 角色 备注 ceph-node1 10.153.204.13 Centos7.6 mon.osd.mds.mgr.rgw. ...
- CEPH集群操作入门--配置
参考文档:CEPH官网集群操作文档 概述 Ceph存储集群是所有Ceph部署的基础. 基于RADOS,Ceph存储集群由两种类型的守护进程组成:Ceph OSD守护进程(OSD)将数据作为对象 ...
- ceph mimic版本 部署安装
ceph 寻址过程 1. file --- object映射, 把file分割成N个相同的对象 2. object - PG 映射, 利用静态hash得到objectID的伪随机值,在 "位 ...
随机推荐
- babel-loader与babel-core的版本对应关系
babel-loader 8.x对应babel-core 7.xbabel-loader 7.x对应babel-core 6.x如何解决1. 卸载旧的babel-corenpm un babel-co ...
- Linux基础命令和文件权限
Linux命令与文件权限 Linux基础命令 reboot 重启 cd 切换目录 cd .. 回到上一级目录 cd ~ 回到主目录 cd / ...
- 洛谷 P2055 【假期的宿舍】
题库 :洛谷 题号 :2055 题目 :假期的宿舍 link :https://www.luogu.org/problem/P2055 首先明确一下:校内的每个学生都有一张床(只是校内的有) 思路 : ...
- NLP(二十) 利用词向量实现高维词在二维空间的可视化
准备 Alice in Wonderland数据集可用于单词抽取,结合稠密网络可实现其单词的可视化,这与编码器-解码器架构类似. 代码 from __future__ import print_fun ...
- 渗透之路基础 -- SQL进阶(盲注和报错注入)
SQL注入之盲注 实战过程中,大多情况下很少会有回显,这个时候就要去使用盲注技术 盲注,Blind SQL Injection,听这名字就感觉整个过程就是一个盲目的过程 当注入时,没有任何提示的时候, ...
- hdu-6579 Operation
题目链接 Operation Problem Description There is an integer sequence a of length n and there are two kind ...
- CodeForces-714B-Filya and Homework+思路
Filya and Homework 题意: 给定一串数字,任选一个数a,把若干个数加上a,把若干个数减去a,能否使得数列全部相同: 思路: 我开始就想找出平均数,以为只有和偶数的可以,结果wa在 1 ...
- 第一章(Kotlin:定义和目的)
实战Kotlin勘误 Kotlin 资源大全 Kotlin主要特征 目标平台 编写服务器端代码(典型的代表是Web应用后端) 创建Android设备上运行的移动应用(Android开发) 其他:可以让 ...
- 详细的漏洞复现:Shellshock CVE-2014-6271 CVE-2014-7169
目录 前言 漏洞原理 利用方式 复现过程 1. 环境准备 (1) 为容器配置固定IP地址 (2) 查看bash版本 2. 本地验证:测试镜像系统是否存在漏洞 3. 远程模拟验证(原理验证) (1) 查 ...
- java中父类子类静态代码块、构造代码块执行顺序
父类静态(代码块,变量赋值二者按顺序执行) 子类静态 父类构造代码块 父类构造方法 子类构造代码块 子类构造方法 普通方法在实列调用的时候执行,肯定位于上面之后了 //父类A public class ...