研究分布式唯一ID生成,看完这篇就够
很多大的互联网公司数据量很大,都采用分库分表,那么分库后就需要统一的唯一ID进行存储。这个ID可以是数字递增的,也可以是UUID类型的。
如果是递增的话,那么拆分了数据库后,可以按照id的hash,均匀的分配到数据库中,并且mysql数据库如果将递增的字段作为主键存储的话会大大提高存储速度。但是如果把订单ID按照数字递增的话,别人能够很容易猜到你有多少订单了,这种情况就可以需要一种非数字递增的方式进行ID的生成。
想到分布式ID的生成,大家可能想到采用Redis进行生成ID,使用Redis的INCR命令去生成和获取这个自增的ID,这个没有问题,但是这个INCR的生成QPS速度为200400(官网发布的测试结果),也就是20W这样子,如果QPS没有超过这些的话,显然使用Redis比较合适。
那么我们对于要达到高可用,高QPS,低延迟我们有没有更好的想法呢。接下来一起看一下snowflake算法,由twitter公司开源的雪花算法。
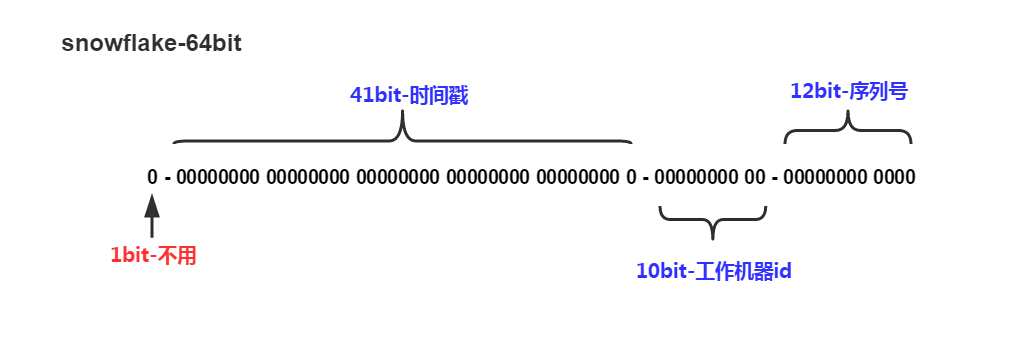
snowflake一共64位:
1. 第一位不用。
2. 41位是时间戳。 2^41以毫秒为单位的话,可得到69年,非常够用了。
3. 10位位工作机器,可以有2^10=1024个工作节点,有的公司将其拆分为5位工作中心编码,5位分给工作机器。
4. 最后12位用于生成递增数据共4096个数。
如果用这个理论上的QPS上的QPS为409W/S。
这种方式的优点为:
1. QPS非常高,性能也非常够。高性能条件也满足了。
2. 不需要依赖其他第三方的中间件,比如Redis。少了依赖,可用率提高了。
3. 可以根据自己定制进行调节。也就是里边的10位进行自由分配。
缺点:
1. 此种算法很依赖时钟,假如时钟进行回拨了,将有可能生成相同的ID。
UUID是采用32位二进制数据生成的,它生成的性能非常好,但是它是基于机器MAC地址生成的,而且不是分布式的,所以不是咱们讨论的范畴。
下面咱们看一下一些大公司的分布式ID实现机制,通过生成创建一张表,采用8个Byte, 64位进行存储使用,用这张表记录所产生ID的位置,比如ID从0开始,然后使用了1000个,那么数据库里边记录里边的最大值是一千,同时还有个步长值,比如1000,那么获取下一个值得时候最大值为2001,即最大的没有使用的值。
具体的实现步骤如下:
1. 提供一个生成分布式ID的服务,这个ID的服务是读取数据库里边的值和步长值计算生成需要的值和范围,然后服务消费方拿到后进行将号段存储到缓存中使用。
2.当给到服务调用方之后,数据库立即更新数据。
这种情况下的优点为:
1. 容灾性能好,如果DB出现问题,因为数据放到内存中,还是可以支撑一段时间。
2. 8个Byte可以满足业务生成ID使用。
3. 最大值可以自己定义,这样有些迁移的业务还可以自己定义最大值继续使用。
当然缺点也存在:
1. 当数据库挂了整个系统将不能使用。
2. 号段递增的,容易被其他人猜到。
3. 如果很多服务同时访问获取这个ID或者网络波动导致数据库IO升高的时候,系统稳定性会出现问题。
然后针对上述情况的解决方法是他们采用了双缓存机制,即将号码段读取到内存中之后开始使用,当使用到了10%的时候重新启动一个新线程,然后当一个缓存用完了之后去用另一块缓存的数据。当另一个缓存的数据达到10%的时候再重启激动一个新线程获取,依次反复。
这样做的好处是避免同时访问大量数据库,导致I/O增多。同时可以通过两个缓存段解决了单一缓存导致很快用完的情况。当然把这个号段设置成QPS大小的600倍,这样数据库挂了10-20分钟内还是可以继续提供服务的。
以上一直提到了一个问题,就是ID递增,咱们如何解决这个问题呢。就是采用snowflake,然后解决里边的时钟问题,有些公司采用ZK去比较当前workerId也就是节点ID使用的时间是否有回拨,如果有回拨就进行休眠固定时间,看是否能赶上时间,如果能赶上的话,继续生成ID,如果一直没有赶上达到某个值得话,那么就报错处理。因为中间10位是表示不同的节点,那么不同的节点生成的ID就不会存在递增的情况。
这些思路都是某公司已经实现了的,如果有兴趣继续研究的话,那么在GITHUB上搜索下开源的Leaf可以直接拿着使用的。
如果有不对的地方,还望指正。
研究分布式唯一ID生成,看完这篇就够的更多相关文章
- 开源项目|Go 开发的一款分布式唯一 ID 生成系统
原文连接: 开源项目|Go 开发的一款分布式唯一 ID 生成系统 今天跟大家介绍一个开源项目:id-maker,主要功能是用来在分布式环境下生成唯一 ID.上周停更了一周,也是用来开发和测试这个项目的 ...
- 分布式唯一ID生成算法-雪花算法
在我们的工作中,数据库某些表的字段会用到唯一的,趋势递增的订单编号,我们将介绍两种方法,一种是传统的采用随机数生成的方式,另外一种是采用当前比较流行的“分布式唯一ID生成算法-雪花算法”来实现. 一. ...
- 关于 Docker 镜像的操作,看完这篇就够啦 !(下)
紧接着上篇<关于 Docker 镜像的操作,看完这篇就够啦 !(上)>,奉上下篇 !!! 镜像作为 Docker 三大核心概念中最重要的一个关键词,它有很多操作,是您想学习容器技术不得不掌 ...
- 分布式唯一ID生成服务
SNService是一款基于分布式的唯一ID生成服务,主要用于提供大数量业务数据建立唯一ID的需要;服务提供最低10K/s的唯一ID请求处理.如果你部署服务的CPU资源达到4核的情况下那该服务最低可以 ...
- 【系统设计】分布式唯一ID生成方案总结
目录 分布式系统中唯一ID生成方案 1. 唯一ID简介 2. 全局ID常见生成方案 2.1 UUID生成 2.2 数据库生成 2.3 Redis生成 2.4 利用zookeeper生成 2.5 雪花算 ...
- 分布式唯一ID生成方案选型!详细解析雪花算法Snowflake
分布式唯一ID 使用RocketMQ时,需要使用到分布式唯一ID 消息可能会发生重复,所以要在消费端做幂等性,为了达到业务的幂等性,生产者必须要有一个唯一ID, 需要满足以下条件: 同一业务场景要全局 ...
- 分布式唯一ID生成方案是什么样的?(转)
一.前言 分布式系统中我们会对一些数据量大的业务进行分拆,如:用户表,订单表.因为数据量巨大一张表无法承接,就会对其进行分库分表. 但一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题, ...
- 一线大厂的分布式唯一ID生成方案是什么样的?
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取.传送门:h ...
- 常见分布式唯一ID生成策略
方法一: 用数据库的 auto_increment 来生成 优点: 此方法使用数据库原有的功能,所以相对简单 能够保证唯一性 能够保证递增性 id 之间的步长是固定且可自定义的 缺点: 可用性难以保证 ...
随机推荐
- shell多线程
a='a1' b='b1' c='c1' d='d1' e='e1' ARR=($a $b $c $d $e) rd=`date +%N` for i in ${ARR[*]} do { ;>& ...
- Python实现按键精灵(二)-找图找色
一.实现功能 判断在指定坐标范围内,是否存在相似度大于n的图片,并返回坐标. 二.基本思路 A=你需要寻找的图片 B=截取当前页面中指定范围的图片 利用opencv 判断A在B中的位置, 在该位置截取 ...
- C++程序设计1(侯捷video 7-13)
一.Big three(拷贝构造.拷贝赋值.析构函数)(video7) Big three指三个特殊函数,分别是拷贝构造函数.拷贝赋值和析构函数. 什么时候需要拷贝构造.拷贝赋值.析构函数: 当类中 ...
- HBase 学习之路(七)——HBase过滤器详解
一.HBase过滤器简介 Hbase提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predica ...
- java源码解析之String类(五)
/* * 切片函数,非常重要,这里一定要牢记beginIndex是开始位置,endIndex是结束位置,区别于以前学的offset是开始位置,而count或length是个数和长度 * 比如说,new ...
- docker命令总结
用 docker pull 拉取镜像 root@lishichao-virtual-machine:~# docker pull hello-world Using default tag: late ...
- 半小时学会V语言
半小时学会V语言 1. V语言简介 V是一个静态类型.编译型的编程语言,目标是构建可维护软件.与Go语言相似,并受Oberon,Rust和Swift语言影响.V语言非常简单,只需要半小时就能学会这门语 ...
- linux 多主机间快速跳转脚本
#!/usr/bin/env python #coding=utf8 ''' 用于多机器间相互跳转,如有新机器加入,需要更新ip_list文件 ''' from prettytable import ...
- seo外链发布之论坛外链
目前最常见的seo外链方式有5种,之前大发迹创业项目网写文章分享过,详情可以查看文章<[网站SEO优化]最常见的五种软文外链发布方式!>,这篇文章不说其他的几种发外链,就来讲讲通过论坛建设 ...
- POJ 2887:Big String(分块)
http://poj.org/problem?id=2887 题意:给出一个字符串,还有n个询问,第一种询问是给出一个位置p和字符c,要在位置p的前面插入c(如果p超过字符串长度,自动插在最后),第二 ...