sklearn学习 第一篇:knn分类
K临近分类是一种监督式的分类方法,首先根据已标记的数据对模型进行训练,然后根据模型对新的数据点进行预测,预测新数据点的标签(label),也就是该数据所属的分类。
一,kNN算法的逻辑
kNN算法的核心思想是:如果一个数据在特征空间中最相邻的k个数据中的大多数属于某一个类别,则该样本也属于这个类别(类似投票),并具有这个类别上样本的特性。通俗地说,对于给定的测试样本和基于某种度量距离的方式,通过最靠近的k个训练样本来预测当前样本的分类结果。例如,借用百度的一张图来说明kNN算法过程,要预测图中Xu的分类结果,先预设一个距离值,只考虑以Xu为圆心以这个距离值为半径的圆内的已知训练样本,然后根据这些样本的投票结果来预测Xu属于w1类别,投票结果是4:1。
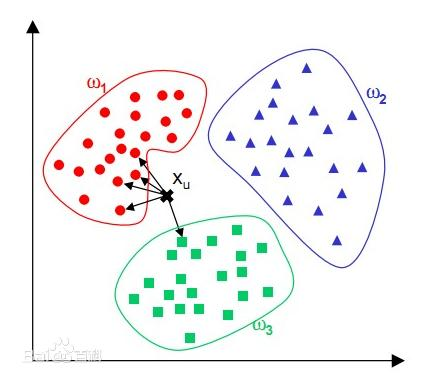
kNN算法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。kNN算法在类别决策时,只与极少量的相邻样本有关。由于kNN算法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
1,kNN算法的计算步骤
kNN算法就是根据距离待分类样本A最近的k个样本数据的分类来预测A可能属于的类别,基本的计算步骤如下:
- 对数据进行标准化,通常是进行归一化,避免量纲对计算距离的影响;
- 计算待分类数据与训练集中每一个样本之间的距离;
- 找出与待分类样本距离最近的k个样本;
- 观测这k个样本的分类情况;
- 把出现次数最多的类别作为待分类数据的类别。
2,kNN算法如何计算距离?
在计算距离之前,需要对每个数值属性进行规范化,这有助于避免较大初始值域的属性比具有较小初始值域的属性的权重过大。
- 对于数值属性,kNN算法使用距离公式来计算任意两个样本数据之间的距离。
- 对于标称属性(如类别),kNN算法使用比较法,当两个样本数据相等时,距离为0;当两个样本数据不等时,距离是1。
- 对于缺失值,通常取最大的差值,假设每个属性都已经映射到[0,1]区间,对于标称属性,设置差值为1;对于数值属性,如果两个元组都缺失值,那么设置差值为1;如果只有一个值缺失,另一个规范化的值是v,则取差值为 1-v 和 v 的较大者。
3,kNN算法如何确定k的值?
k的最优值,需要通过实验来确定。从k=1开始,使用检验数据集来估计分类器的错误率。重复该过程,每次k增加1,允许增加一个近邻,选取产生最小错误率的k。一般而言,训练数据集越多,k的值越大,使得分类预测可以基于训练数据集的较大比例。在应用中,一般选择较小k并且k是奇数。通常采用交叉验证的方法来选取合适的k值。
二,KNeighborsClassifier函数
使用KNeighborsClassifier创建K临近分类器:
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30,
p=2, metric=’minkowski’, metric_params=None, n_jobs=None, **kwargs)
参数注释:
1,n_neighbors
临近的节点数量,默认值是5
2,weights
权重,默认值是uniform,
- uniform:表示每个数据点的权重是相同的;
- distance:离一个簇中心越近的点,权重越高;
- callable:用户定义的函数,用于表示每个数据点的权重
3,algorithm
- auto:根据值选择最合适的算法
- ball_tree:使用BallTree
- kd_tree:KDTree
- brute:使用Brute-Force查找
4,leaf_size
leaf_size传递给BallTree或者KDTree,表示构造树的大小,用于影响模型构建的速度和树需要的内存数量,最佳值是根据数据来确定的,默认值是30。
5,p,metric,metric_paras
- p参数用于设置Minkowski 距离的Power参数,当p=1时,等价于manhattan距离;当p=2等价于euclidean距离,当p>2时,就是Minkowski 距离。
- metric参数:设置计算距离的方法
- metric_paras:传递给计算距离方法的参数
6,n_jobs
并发执行的job数量,用于查找邻近的数据点。默认值1,选取-1占据CPU比重会减小,但运行速度也会变慢,所有的core都会运行。
三,观察数据
由于knn分类是监督式的分类方法之前,在构建一个复杂的分类模型之前,首先需要已标记的数据集。我们可以从sklearn的数据集中加载已有的数据进行学习:
from sklearn.datasets import load_iris
iris_dataset=load_iris()
查看iris_dataset的数据,该对象的结构和字典非常类型:
>>> iris_dataset.keys()
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
1,样本数据
data 是样本数据,共4列150行,列名是由feature_names来确定的,每一列都叫做矩阵的一个特征(属性),前4行的数据是:
>>> iris_dataset.data[0:4]
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2]])
2,标签
target是标签,用数字表示,target_names是标签的文本表示
>>> iris_dataset.target[0:4]
array([0, 0, 0, 0]) >>> iris_dataset.target_names
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
3,查看数据的散点图
查看数据的散点图矩阵,按照数据的类别进行着色,观察数据的分布:
import pandas as pd
import mglearn iris_df=pd.DataFrame(x_train,columns=iris_dataset.feature_names)
pd.plotting.scatter_matrix(iris_df,c=y_train,figsize=(15,15),marker='o',hist_kwds={'bins':20}
,s=60,alpha=.8,cmap=mglearn.cm3)

四,创建模型
我们使用sklearn数据集中的鸢尾花测量数据来构建一个复杂的分类模型,并根据输入的数据点来预测鸢尾花的类别。
1,拆分数据
把鸢尾花数据拆分为训练集和测试集:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)
使用函数把已标记的数据拆分成训练集和测试集:
sklearn.model_selection.train_test_split(*arrays, test_size ,train_size ,random_state ,shuffle ,stratify )
test_size:拆分的测试集数据所占的百分比,如果test_size和train_size都是none,那么默认值是test_size=0.25
train_size:拆分的训练集数据所占的百分比,
random_state:如果是int,那么参数用于指定随机数产生的种子;如果是None,使用np.random作为随机数产生器
shuffle:布尔值,默认值是True,表示在拆分之前对数据进行洗牌;如果shuffle = False,则分层必须为None。
stratify:如果不是None,则数据以分层方式拆分,使用此作为类标签。
2,创建分类器
使用KNeighborsClassifier创建分类器,设置参数n_neighbors为1:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
3,使用训练集来构建模型
对于监督学习,训练数据集包括两部分:输入和结果(Lable),每一行输入都对应一行结果,结果是输入的正确分类(标签)。
通常,记X_train是训练的输入数据集,X_train对应的结果是y_train,是训练数据集的输出,通过fit()函数来训练模型,构建模型:
knn.fit(x_train, y_train)
4,预测新数据
对于训练之后的模型,使用predict()函数来预测数据的结果。
x_new=np.array([[5, 2.9, 1, 0.2]]) prediction= knn.predict(x_new)
print("prediction :{0} ,classifier:{1}".format(prediction,iris_dataset["target_names"][prediction]))
五,模型评估
knn分类有2个重要的参数:邻居个数和数据点之间距离的度量方法。在实践中,使用较小的奇数个邻居,比如,3和5,往往可以得到比较好的结果,但是,这是经验之谈,你应该根据数据来调节这个参数。
1,模型的正确率
在使用模型之前,应该使用测试集来评估模型,所谓模型的正确率,就是使用已标记的数据,根据数据预测的结果和标记的结果进行比对,计算比对成功的占比:
assess_model_socre=knn.score(x_test,y_test)
print('Test set score:{:2f}'.format(assess_model_socre))
使用模型的score()函数,使用测试集进行评分,分数越高,模型越好。
2,邻居个数
如何确定邻居的个数,下面使用枚举法,逐个测试邻居的个数,并根据模型的score()函数查看模型的正确率。
import mglearn
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier cancer=load_breast_cancer() x_train,x_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=66) training_accuracy=[]
test_accuracy=[] neighbors_settings=range(1,11) for n_neighbors in neighbors_settings:
knn=KNeighborsClassifier(n_neighbors)
knn.fit(x_train,y_train)
training_accuracy.append(knn.score(x_train,y_train))
test_accuracy.append(knn.score(x_test,y_test)) plt.plot(neighbors_settings,training_accuracy,label='Training Accuracy')
plt.plot(neighbors_settings,test_accuracy,label='Test Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('n_neighbors')
plt.legend()
3,距离选择
数据点之间的距离,计算距离的方法有:"euclidean"(欧氏距离),”minkowski”(明科夫斯基距离), "maximum"(切比雪夫距离), "manhattan"(绝对值距离),"canberra"(兰式距离), 或 "minkowski"(马氏距离)等。
4,预测的不确定度估计
查看分类的不确定度估计,使用模型的predict_prob()函数来查看模型预测的概率。
参考文档:
sklearn.neighbors.KNeighborsClassifier
sklearn学习 第一篇:knn分类的更多相关文章
- sklearn 学习 第一篇:分类
分类属于监督学习算法,是指根据已有的数据和标签(分类)进行学习,预测未知数据的标签.分类问题的目标是预测数据的类别标签(class label),可以把分类问题划分为二分类和多分类问题.二分类是指在两 ...
- LINQ to XML LINQ学习第一篇
LINQ to XML LINQ学习第一篇 1.LINQ to XML类 以下的代码演示了如何使用LINQ to XML来快速创建一个xml: public static void CreateDoc ...
- 从.Net到Java学习第一篇——开篇
以前我常说,公司用什么技术我就学什么.可是对于java,我曾经一度以为“学java是不可能的,这辈子不可能学java的.”结果,一遇到公司转java,我就不得不跑路了,于是乎,回头一看N家公司交过社保 ...
- Java并发包下锁学习第一篇:介绍及学习安排
Java并发包下锁学习第一篇:介绍及学习安排 在Java并发编程中,实现锁的方式有两种,分别是:可以使用同步锁(synchronized关键字的锁),还有lock接口下的锁.从今天起,凯哥将带领大家一 ...
- JVM学习第一篇思考:一个Java代码是怎么运行起来的-上篇
JVM学习第一篇思考:一个Java代码是怎么运行起来的-上篇 作为一个使用Java语言开发的程序员,我们都知道,要想运行Java程序至少需要安装JRE(安装JDK也没问题).我们也知道我们Java程序 ...
- Python学习第一篇
好久没有来博客园了,今天开始写自己学习Python和Hadoop的学习笔记吧.今天写第一篇,Python学习,其他的环境部署都不说了,可以参考其他的博客. 今天根据MachineLearning里面的 ...
- Golang学习-第一篇 Golang的简单介绍及Windows环境下安装、部署
序言 这是本人博客园第一篇文章,写的不到位之处,希望各位看客们谅解. 本人一直从事.NET的开发工作,最近在学习Golang,所以想着之前学习的过程中都没怎么好好的将学习过程记录下来.深感惋惜! 现在 ...
- Android基础学习第一篇—Project目录结构
写在前面的话: 1. 最近在自学Android,也是边看书边写一些Demo,由于知识点越来越多,脑子越来越记不清楚,所以打算写成读书笔记,供以后查看,也算是把自己学到所理解的东西写出来,献丑,如有不对 ...
- ImageJ 学习第一篇
ImageJ是世界上最快的纯Java的图像处理程序.它可以过滤一个2048x2048的图像在0.1秒内(*).这是每秒40万像素!ImageJ的扩展通过使用内置的文本编辑器和Java编译器的Image ...
随机推荐
- 如何理解<T extends Comparable<? super T>>
在看java容器类的时候经常可以看到<T extends Comparable<? super T>>,感觉十分不解? 我们觉得<T extends Comparable ...
- shell多线程(3)while循环
start="2018-06-17" end="2018-07-01" min=`date -d "${start}" +%Y%m%d` m ...
- C#最新功能(6.0、7.0)
一直用C#开发程序,.NET的功能越来越多,变化也挺大的,从最初的封闭,到现在的开源,功能不断的增加,一直在进步.作为C#的强烈支持者,C#的变化,我不能不关注,这篇文章主要介绍,C#6.0和C#7. ...
- express 中间件的理解
nodejs(这指express) 中间件 铺垫: 一个请求发送到服务器,要经历一个生命周期,服务端要: 监听请求-解析请求-响应请求,服务器在处理这一过程的时候,有时候就很复杂了,将这些复杂的业务拆 ...
- 区块狗开发可以做出APP吗
区块狗系统开发林生▉l8l加4896微9698电同步▉,区块狗奖励系统开发,区块狗平台系统开发,区块狗系统开发软件,区块狗系统开发案例,区块狗源码系统开发. 本公司是软件开发公司,华登区块狗/十二生肖 ...
- 精通并发与 Netty (一)如何使用
精通并发与 Netty Netty 是一个异步的,事件驱动的网络通信框架,用于高性能的基于协议的客户端和服务端的开发. 异步指的是会立即返回,并不知道到底发送过去没有,成功没有,一般都会使用监听器来监 ...
- (Demo分享)利用JavaScript(JS)做一个可输入分钟的倒计时钟功能
利用JavaScript(JS)实现一个可输入分钟的倒计时钟功能本文章为 Tz张无忌 原创文章,转载请注明来源,谢谢合作! 网络各种利用JavaScript做倒计时的Demo对新手很不友好,这里我亲手 ...
- 使用git提交时报错:error: RPC failed; HTTP 413 curl 22 The requested URL returned error: 413 Request Entity Too Large
Delta compression using up to 4 threads.Compressing objects: 100% (2364/2364), done.Writing objects: ...
- CI框架中的奇葩
今天在win下开发,使用ci框架,本来是没有任何问题,然后转向了mac上开发,结果出现了个奇葩的问题,就是在ci框架中,控制器命名以"Admin_"为前缀的,在url中,控制器也必 ...
- 浅谈Invoke 和 BegionInvoke的用法
很多人对Invoke和BeginInvoke理解不深刻,不知道该怎么应用,在这篇博文里将详细阐述Invoke和BeginInvoke的用法: 首先说下Invoke和BeginInvoke有两种用法: ...