SpringDataJpa入门案例及查询详细解析
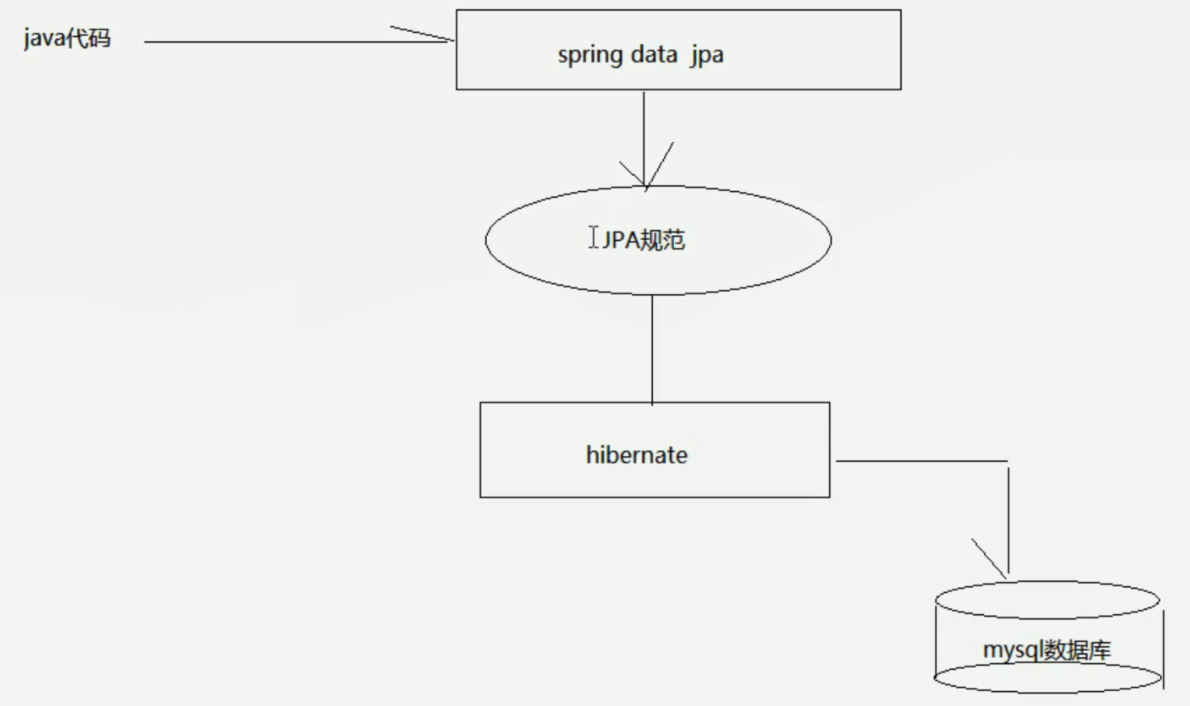
SpringDataJpaSpring Data JPA
让我们解脱了DA0层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA+ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
把JPA规范的代码封装起来,真正进行查询的还是hibernate或mybatis >>(封装了jdbc操作),然后进行查询或操作数据库。
SpringDataJpa入门操作(搭建环境)
创建工程,导入坐标
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>cn.itcast</groupId>
<artifactId>jpa-day02</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<spring.version>5.0.2.RELEASE</spring.version>
<hibernate.version>5.0.7.Final</hibernate.version>
<s1f4j.version>1.6.6</s1f4j.version>
<log4j.version>1.2.12</log4j.version>
<c3pe.version>0.9.1.2</c3pe.version>
<mysql.version>5.1.6</mysql.version>
</properties> <dependencies>
<!--junit单元测试-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
<scope>test</scope>
</dependency>
<!--spring beg-->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.6.8</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
<!--spring对ORm框架的支持包-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency> <!--spring end--> <!--hibernate beg-->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.2.1.Final</version>
</dependency> <!--hibernate end--> <!--c3p0 beg-->
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.1.2</version>
</dependency> <!--log end-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.6</version>
</dependency>
<!--log end--> <dependency>
<groupId>mysq1</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<!-- spring data jpa 的坐标 -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.9.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.2.4.RELEASE</version>
</dependency> <!--el beg 使用spring data jpa必须引入-->
<dependency>
<groupId>javax.el</groupId>
<artifactId>javax.el-api</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>javax.el</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.22</version>
</dependency>
</dependencies>
</project>
项目所需的依赖坐标
配置Spring的配置文件
<!--创建entityManagerFactory对象交给Spring容器管理-->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> (权限定位类名)
<property name="dataSource" ref="dataSource"/> (依赖注入)
<property name="packagesToScan " value="cn.itcast.domain"/> (配置的扫描的包,实体类所在的包)
<property name="persistenceProvider"> (JPA的实现厂家)
<bean class="org.hibernate.jpa.HibernatePersistenceProvider"/>
</property> <!--jpa的供应商适配器-->
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<!--配置是否自动创建数据库表-->
<property name="generateDdl" value="false"/>
<!--指定数据库类型-->
<property name="database" value="MYSQL"/>
<!--数据库方言:支持的特有语法(不同数据库有不同的语法)-->
<property name="databasePlatform" value="org.hibernate.dialect.MySQLDialect"/>
<!--是否显示sql-->
<property name="showSql" value="true"/>
</bean>
</property> <!--jpa的方言 :高级特性(配置了谁就拥有了谁的高级特性)-->
<property name="jpaDialect">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect"></bean>
</property>
</bean>
<!--2.创建数据库连接池-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="root"></property>
<property name="password" value="123456"></property>
<property name="jdbcUrl" value="jdbc:mysq1:///jpa"></property>
<property name="driverClass" value="com.mysql.jdbc.Driver"></property>
</bean>
(以下的不需要特别记忆)>>>
<!--3.整合spring dataJpa-->
<jpa:repositories base-package="cn.itcast.dao" transaction-manager-ref="transactionManager"
entity-manager-factory-ref="entityManagerFactory"></jpa:repositories>
<!--4.配置事务管理器-->
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory"></property>
</bean>
<!--5.声明式事务-->
<!--6.配置 包扫描-->
<context:component-scan base-package="cn.itcast"></context:component-scan>
</beans>
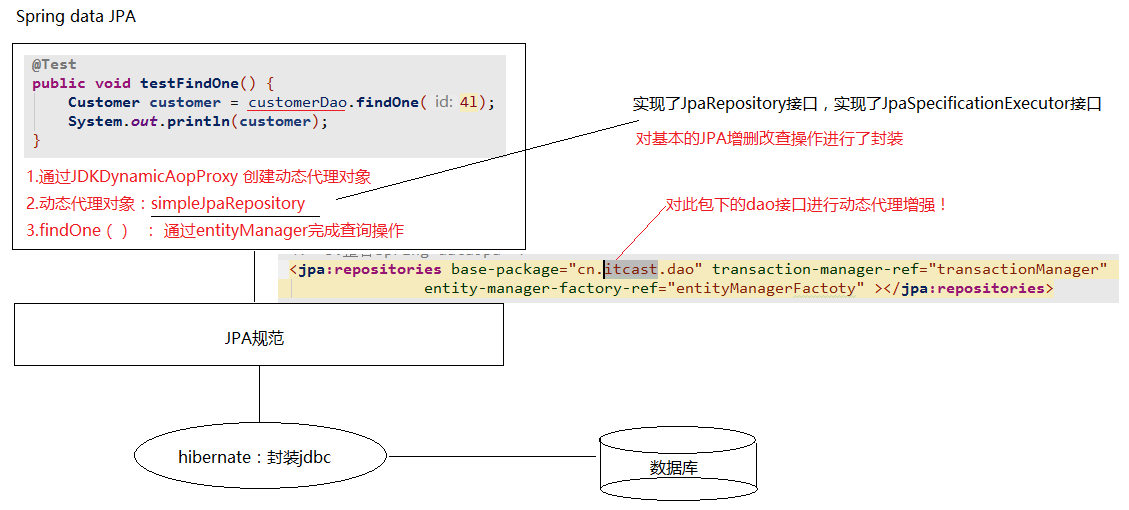
编写符合SpringDataJpa规范的dao层接口
package cn.itcast.dao; import cn.itcast.domain.Customer; import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
/**
* 符合springDataJpa的dao层接口规范
* JpaRepository<操作的实体类类型,实体类中主键属性的类型) >>>封装了基本的CRUD操作
* JpaSpecificationExecutor<操作的实体类类型> >>>封装了复杂查询()
*/
public interface CustomerDao extends JpaRepository<Customer, Long>, JpaSpecificationExecutor<Customer> {}
完成客户的增删改查操作
根据id查询
- findOne
em.find() 立即加载
- getOne
@Transactional:保证getOne正常运行
em.getReference() 延迟加载 >>返回的是一个客户的动态代理对象,什么时候用、什么时候查询
@Test
public void testFindOne() {
Customer customer = customerDao.findOne(3l);
System.out.println(customer);
}
保存和更新(sava)
- 如果没有id主键属性:>> 保存
@Test
public void testSave() {
Customer customer = new Customer();
customer.setCustname("黑马程序员");
customer.setCustaddress("北京");
customer.setCustindustry("IT教育");
customerDao.save(customer);
}
- 存在id主键属性: >> 根据id查询数据,更新数据
@Test
public void testUpdate() {
Customer customer = new Customer();
customer.setCustid(1l);
customer.setCustname("播客");
customer.setCustindustry("黑马程序员很厉害");
customerDao.save(customer);
}
根据id删除(delete)
@Test
public void testDelete() {
Customer customer = new Customer();
customerDao.delete(1l);
}
查询所有客户(findAll)
@Test
public void findAll(){
List<Customer> list = customerDao.findAll();
for (Customer customer : list) {
System.out.println(customer);
}
SpringDataJpa的运行过程和原理剖析
1. 通过JdkDynamicAopProxy的 invoke 方法创建了一个动态代理对象
2. simpleJpaRepository当中封装了 JPA的操作(借助JPA的api完成数据库的CRUD)
3. 通过 hibernate完成数据库操作(封装了jdbc)
复杂查询
借助接口中的定义好的方法完成查询
findone(id):根据id查询
测试统计查询:查询客户的总数量
@Test
public void testdount() {
long count = customerDao.count();//查询全部的客户数量System.out.println(count);
System.out.println(count);
}
测试:判断id为3的客户是否存在
- 可以查询以下id为3的客户
如果值为空,代表不存在,如果不为空,代表存在
- 判断数据库中id为3的客户的数量
如果数量为0,代表不存在(false),如果大于0,代表存在(true)
@Test
public void testExists() {
boolean exists = customerDao.exists(3l);
System.out.println(exists);
}
jpql的查询方式♦♦
jpql:jpa query language( jpq查询语言 )
特点:语法或关键字和sql语句类似
查询的是类和类中的属性
需要将JPQL语句配置到接口方法上
1 .特有的查询:需要在dao接口上配置方法
2. 在新添加的方法上,使用注解的形式配置jpql查询语句
3. 注解:@Query
案例:根据客户名称查询名称 >> 使用Jpql的形式查询
CustomerDao
public interface CustomerDao extends JpaRepository<Customer, Long>, JpaSpecificationExecutor<Customer> {
/**
* 案例:根据客户名称查询名称
* 使用Jpql的形式查询
* jpql: from Customer where custName = ?
*/
@Query(value = "from Customer where custname = ?")
public Customer findJpql(String custname);
}
JpqlTest
@Test
public void testFindJpql(){
Customer customer = customerDao.findJpql("传智");
System.out.println(customer);
}
案例:根据客户名称和客户id查询客户 >> 使用Jpql的形式查询
- 对于多个占位符参数: 赋值的时候,默认的情况下,占位符的位置需要和方法参数中的位置保持一致 [ custName >> String name custId >> Long id ]
@Query(value="from Customer where custName=? and custId=?")
public Customer findCustNameAndId (String name , Long id );
- 也可以指定占位符参数的位置 : ?索引的方式,指定此占位的取值来源
@Query (value=" from Customer where custName = ?2 and custId = ?1 ")
public Customer findCustNameAndId ( Long id , String name );
CustomerDao
@Query(value = "from Customer where custname = ? and custid = ?")
public Customer findCustNameAndId(String custname, long id);
JpqlTest
@Test
public void testCustNameAndId(){
Customer customer = customerDao.findCustNameAndId("黑马",2l);
System.out.println(customer);
}
使用jpql完成更新操作案例:根据id更新更新2号客户的名称,将名称改为“黑马程序员”
CustomerDao
@Query(value = " update Customer set custname = ?2 where custid = ?1 ") //代表的是进行查询
@Modifying //当前执行的是一个更新操作
//更新不需要返回值 选择void
public void UpdateCustomer( long custid,String custname);
JpqlTest
@Test
@Transactional //添加对事务的支持
@Rollback(value = false) //设置是否自动回滚
public void testUpdateCustomer(){
customerDao.UpdateCustomer(2l,"黑马程序员");
}
执行结束后,默认回滚事务,可以通过@Rollback 设置是否自动回滚 >> false | true
SQL查询方式.
1 .特有的查询:需要在dao接口上配置方法
2. 在新添加的方法上,使用注解的形式配置sql查询语句
3. 注解:@Query
value: jsql | sql
nativeQuery : fals(使用jpql查询) l true(使用本地查询:sql查询)
CustomerDao
@Query(value = "select * from cst_customer",nativeQuery = true)
public List<Object[]>findSql();
JpqlTest
@Test
public void testfindSql(){
List<Object[]> list = customerDao.findSql();
for (Object[] obj : list) {
System.out.println(Arrays.toString(obj));//每一个里面都还是object数组,所以需要借助Arrays.toString()方法打印数组
}
方法命名规则查询
>> 1: findBy +属性名(首字母大写)
public Customer findByCustname(String custname);
@Test
public void testNaming(){
Customer customer = customerDao.findByCustname("传智");
System.out.println(customer);
}
>> 2: findBy + 属性名(首字母大写)+ “查询方式”
public List<Customer> findByCustnameLike(String custname);
@Test
public void testfindByCustnameLike(){
List<Customer> list = customerDao.findByCustnameLike("黑马%");
for (Customer customer : list) {
System.out.println(customer);
} }
>> 3: findBy + 属性名(首字母大写)+ “查询方式” + “多条件的连接符(and | or)” + 属性名 + “查询方式”
使用客户名称模糊匹配和客户所属行业精准匹配的查询
public List<Customer> findByCustnameLikeAndCustindustry(String custname, String custindustry); //结果可能是一个或多个,所以选择List<Customer>
@Test
public void testFindByCustnameLikeAndCustindustry(){
List<Customer> list = customerDao.findByCustnameLikeAndCustindustry("黑马%","it教育");
for (Customer customer : list) {
System.out.println(customer);
} }
Specifications动态查询
- root :查询的根对象(查询的任何属性都可以从根对象中获取)
- cirteriaQuery:顶层查询对象,自定义查询方式(了解,一般不用)
- cirteriaBuilder:查询的构造器,封装了很多查询条件
public Predicate toPredicate(Root<Customer> root , CriteriaQuery<?> query , CriteriaBuilder cb) { } //封装查询条件
查询客户名为 “传智” 的客户
@Test
public void testSpec() {
实现Specification接口( 提供泛型 :查询的对象属性)
Specification<Customer> spec = new Specification<Customer>() {
实现toPredicate方法(构造查询条件)
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//1.获取比较的属性
Path<Object> custname = root.get("custname");
//2.构造查询条件
Predicate predicate = cb.equal(custname, "传智"); //进行精准的匹配(custname:比较的属性 , “传智”:比较的属性取值)
return predicate;
}};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
查询客户名为 “黑马2” 并且行业为 "it教育" 的的客户
@Test
public void testSpec1() {
Specification<Customer> spec = new Specification<Customer>() {
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//1.获取比较的属性
Path<Object> custname = root.get("custname");
Path<Object> custindustry = root.get("custindustry");
//2.构造查询条件
Predicate p1 = cb.equal(custname, "黑马2");
Predicate p2 = cb.equal(custindustry, "it教育");
and(与关系):满足条件1并且满足条件2 or(或关系):满足条件1或满足条件2
Predicate and = cb.and(p1, p2);
return and;
}
};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
案例:完成根据客户名称的模糊匹配,返回客户列表 >>客户名称以 “传智播客” 开头
默认: equal:直接得到 path对象(属性),然后进行比较即可
gt(大于),lt(小于),ge(大于等于),le(小于等于),like:得到path对象,根据path指定比较的参数类型,再去进行比较
指定参数类型:path.as(类型的字节码对象)
@Test
public void testSpec2() {
Specification<Customer> spec = new Specification<Customer>() {
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
Path<Object> custname = root.get("custname"); //查询属性:客户名
Predicate predicate = cb.like(custname.as(String.class), "传智播客%"); //查询方式:模糊匹配
return predicate;
}
};
List<Customer> list = customerDao.findAll(spec);
for (Customer customer : list) {
System.out.println(customer);
} }
添加排序 >>创建排序对象,需要调用构造方法实例化sort对象
第一个参数:排序的顺序(倒序,正序)
- Sort.Direction.DESC:倒序
- Sort.Direction.ASC:升序
第二个参数:排序的属性名称
Sort sort = new Sort(Sort.Direction.DESC, "custid");
List<Customer> list = customerDao.findAll(spec, sort);
分页查询
- 不带参数的分页查询
创建PageRequest的过程中,需要调用他的构造方法传入两个参数
第一个参数:当前查询的页数(从e开始)
第二个参数:每页查询的数量
@Test
public void testSpec3() {
Specification spec = null; //不带参数
Pageable pageable = new PageRequest(0, 2);
//分页查询
Page<Customer> page = customerDao.findAll(null, pageable);
System.out.println(page.getContent());//得到数据集合列表
System.out.println(page.getTotalElements());//得到总条数
System.out.println(page.getTotalPages());//得到总页数
}
- 带参数分页查询
@Test
public void testSpec4() {
Specification spec = new Specification() {
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder criteriaBuilder) {
Path custname = root.get("custname");
Predicate predicate = criteriaBuilder.equal(custname, "传智播客");
return predicate;
}};
Pageable pageable = new PageRequest(0, 2);
//分页查询
Page<Customer> page = customerDao.findAll(spec, pageable);
System.out.println(page.getContent());//得到数据集合列表
System.out.println(page.getTotalElements());//得到总条数
System.out.println(page.getTotalPages());//得到总页数
}
SpringDataJpa入门案例及查询详细解析的更多相关文章
- Java开发学习(二十三)----SpringMVC入门案例、工作流程解析及设置bean加载控制
一.SpringMVC概述 SpringMVC是隶属于Spring框架的一部分,主要是用来进行Web开发,是对Servlet进行了封装.SpringMVC是处于Web层的框架,所以其主要的作用就是用来 ...
- 目标检测从入门到精通—R-CNN详细解析(二)
R-CNN目标检测详细解析 <Rich feature hierarchies for Accurate Object Detection and Segmentation> Author ...
- Java开发学习(十五)----AOP入门案例及其工作流程解析
一.AOP简介 1.1 什么是AOP AOP(Aspect Oriented Programming)面向切面编程,一种编程范式,指导开发者如何组织程序结构. OOP(Object Oriented ...
- Android简易实战教程--第二十七话《自定义View入门案例之开关按钮详细分析》
转载此博客请注明出处点击打开链接 http://blog.csdn.net/qq_32059827/article/details/52444145 对于自定义view,可能是一个比较大的 ...
- 干货 | 自适应大邻域搜索(Adaptive Large Neighborhood Search)入门到精通超详细解析-概念篇
01 首先来区分几个概念 关于neighborhood serach,这里有好多种衍生和变种出来的胡里花俏的算法.大家在上网搜索的过程中可能看到什么Large Neighborhood Serach, ...
- 目标检测从入门到精通—SPP-Net详细解析(三)
SPP-Net网络结构分析 Author:Mr. Sun Date:2019.03.18 Loacation: DaLian university of technology 论文名称:<Spa ...
- Java开发学习(二十八)----拦截器(Interceptor)详细解析
一.拦截器概念 讲解拦截器的概念之前,我们先看一张图: (1)浏览器发送一个请求会先到Tomcat的web服务器 (2)Tomcat服务器接收到请求以后,会去判断请求的是静态资源还是动态资源 (3)如 ...
- SpringMVC入门案例及请求流程图(关于处理器或视图解析器或处理器映射器等的初步配置)
SpringMVC简介:SpringMVC也叫Spring Web mvc,属于表现层的框架.Spring MVC是Spring框架的一部分,是在Spring3.0后发布的 Spring结构图 Spr ...
- 项目一:项目第二天 Jquery ztree使用展示菜单数据 2、 基础设置需求分析 3、 搭建项目框架环境--ssh(复习) 4、 SpringData-JPA持久层入门案例(重点) 5、 Easyui menubutton菜单按钮使用 6、 Easyui messager消息框使用
1. Jquery ztree使用展示菜单数据 2. 基础设置需求分析 3. 搭建项目框架环境--ssh(复习) 4. SpringData-JPA持久层入门案例(重点) 5. Easyui menu ...
随机推荐
- Linux 常用命令及详解
1. type :查询命令 是否属于shell解释器2. help : 帮助命令3. man : 为所有用户提供在线帮助4. ls : 列表显示目录内的文件及目录-l 以长格式显 ...
- Jmeter 接口测试参数处理
问题: 一.签名参数sign算法由文字描述,算法需自己编写 二. 参数param_json为变化的json串(json串内订单号唯一) 解决: 一. 签名sign: 1. 手动拼接后在https:// ...
- SpringMVC学习笔记之---深入使用
SpringMVC深入使用 (一)基于XML配置的使用 (1)配置 1.SpringMVC基础配置 2.XML配置Controller,HandlerMapping组件映射 3.XML配置ViewRe ...
- git bash 初始化配置
这里只针对 windows 下,使用git 时的一些初始配置 1. git bash 安装 下载地址: https://git-for-windows.github.io/ 根据提示,一步步安装即可 ...
- 第十五章 LVM管理和ssm存储管理器使用 随堂笔记
第十五章 LVM管理和ssm存储管理器使用 本节所讲内容: 15.1 LVM的工作原理 15.2 创建LVM的基本步骤 15.3 实战-使用SSM工具为公司的邮件服务器创建可动态扩容的存储池 LVM的 ...
- Git使用(码云)
1.安装git软件(码云/GitHub) 2.码云注册,保存代码 3.创建代码托管仓库,仓库名相当于码云上的文件夹 4.写作业并提交 在作业文件夹上,右键选择‘get bash here’ 在黑框里输 ...
- 前端插件之Datatables使用--下篇
工欲善其事,必先利其器 本系列文章介绍我在运维系统开发过程中用到的那些顺手的前端插件,上一篇文章介绍了Datatables插件的基本使用,这一篇文章作为上一篇的延续,会介绍Databases的一些高级 ...
- Appium+python自动化(三十二)- 代码写死一时爽,框架重构火葬场 - PageObject+unittest(超详解)
简介 江湖有言:”代码写死一时爽,框架重构火葬场“,更有人戏言:”代码动态一时爽,一直动态一直爽
- ZooKeeper系列(三)—— Zookeeper 常用 Shell 命令
一.节点增删改查 1.1 启动服务和连接服务 # 启动服务 bin/zkServer.sh start #连接服务 不指定服务地址则默认连接到localhost:2181 zkCli.sh -serv ...
- linux环境下测试环境搭建
一.linux环境下测试环境搭建过程简述: 1.前端后台代码未分离情况下: 主要步骤为:安装jdk,安装mysql,安装tomcat,将项目代码部署到tomcat/webapps/下. 2.前端后台代 ...