6.InfluxDB-InfluxQL基础语法教程--GROUP BY子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/)
GROUP BY子句通过用户自己制定的tags set或time区间,来将查询结果进行分组。
一、GROUP BY tags
GROUP BY 通过用户指定的tag set,来对查询结果进行分组。
语法:
SELECT_clause FROM_clause [WHERE_clause]
GROUP BY [* | <tag_key>[,<tag_key]]
| GROUP BY子句 | 意义 |
|---|---|
| GROUP BY * | 使用所有tag对查询结果进行分组 |
| GROUP BY <tag_key> | 使用指定tag对查询结果进行分组 |
| GROUP BY <tag_key>,<tag_key> | 使用指定的多个tag对查询结果进行分组,其中tag之间的顺序是无关的。 |
注 :如果在sql中同时存在WHERE子句和GROUP BY子句,则GROUP BY子句一定要在WHERE子句之后!
Other supported features: Regular Expressions
GROUP BY tags 示例sql
Group query results by a single tag
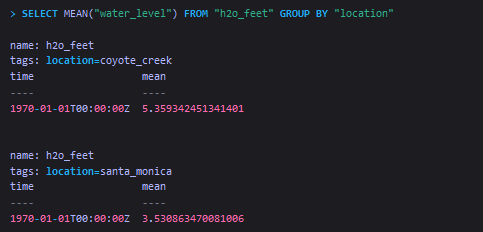
上面的sql使用了MEAN函数,来对h2o_feet这个measurement中的location这个tag进行分组求平均值。
注:在InfluxDB中,0纪元1970-01-01T00:00:00Z这个时间经常被用来表示timestamp的NULL值。如果你的查询中没有显示指定返回一个timestamp,比如上面在调用聚合函数时,就没有指定时间区间,因此InfluxDB最后返回0纪元来作为timestamp。Group query results by more than one tag

Group query results by all tags

二、基础GROUP BY time intervals
GROUP BY time() 查询会将查询结果按照用户指定的时间区间来进行分组。
语法:
SELECT <function>(<field_key>) FROM_clause
WHERE <time_range>
GROUP BY time(<time_interval>),[tag_key] [fill(<fill_option>)]
基本的 GROUP BY time() 查询用法需要在SELECT子句中调用相关函数,并且在WHERE子句中调用time时间区间。
time(time_interval)
在GROUP BY time()子句中的time_interval是个连续的时间区间,该时间区间决定了InfluxDB如何通过时间来对查询结果进行分组。比如,如果time_interval为5m,那么它会将查询结果分为5分钟一组(如果在WHERE子句中指定了time区间,那么就是将WHERE中指定的time区间划分为没5分钟一组)。fill(<fill_option>)
fill(<fill_option>) 是可选的。它可以填充那些没有数据的时间区间的值。 从 [GROUP BY time intervals and fill() ] (https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/#group-by-time-intervals-and-fill) 部分可查看到关于这部分的更多信息。注:基本的GROUP BY time()查询通过当前InfluxDB数据库的预设时间边界来确定每个时间间隔中包含的原始数据和查询返回的时间戳。
基本用法示例sql
先看一个WHERE查询

下面的GROUP BY time(time_interval)示例是在上面的sql基础上进行改进的,sql为:
SELECT COUNT("water_level") FROM "h2o_feet"
WHERE "location"='coyote_creek'
AND time >= '2015-08-18T00:00:00Z'
AND time <= '2015-08-18T00:30:00Z'
GROUP BY time(12m)
查询结果:
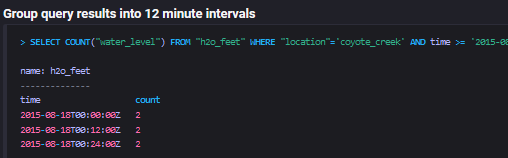
该sql将h2o_feet表中tag=“coyote_creek”,且在'2015-08-18T00:00:00Z'和'2015-08-18T00:30:00Z'时间区间内的数据查询出来,并对其划分为每12分钟一组,对water_level值进行count计算。
注意:在查询结果中,时间区间是左闭右开的。拿第一行查询结果数据来说,2015-08-18T00:00:00Z表示的时间区间是[2015-08-18T00:00:00, 2015-08-18T00:12:00Z )
常见问题
问题:查询结果中有预期之外的时间区间和值。
在基本用法中,GROUP BY time()查询通过当前InfluxDB数据库的预设时间边界来确定每个时间间隔中包含的原始数据和查询返回的时间戳,这有可能会导致预期之外的结果值。
比如,通过如下sql:
SELECT "water_level" FROM "h2o_feet"
WHERE "location"='coyote_creek'
AND time >= '2015-08-18T00:00:00Z'
AND time <= '2015-08-18T00:18:00Z'
我们查询到原始数据如下所示:
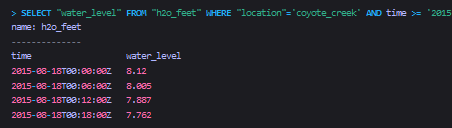
在接下来的查询中,我们通过WHERE子句,指定查询12分钟内的数据,并通过GROUP BY子句,将查询结果按12分钟的时间区间进行分组。
SELECT COUNT("water_level") FROM "h2o_feet"
WHERE "location"='coyote_creek'
AND time >= '2015-08-18T00:06:00Z'
AND time < '2015-08-18T00:18:00Z'
GROUP BY time(12m)
按照预想,因为查询的是12分钟内的数据,并且group by时是按照12分钟来进行分组的,所以最后的查询结果应该只有一行而已。然后实际的查询结果却有两行:

解释 :
influxdb使用预设的整数时间边界来作为GROUP BY的时间间隔,这些间隔独立于WHERE子句中的任何时间条件。在计算结果时,所有返回的数据都必须出现在WHERE查询的显式时间范围内,但当按间隔作为GROUP BY分组时是基于预设的时间边界。
(这里翻译的不好,下面是原版英文:
InfluxDB uses preset round-number time boundaries for GROUP BY intervals that are independent of any time conditions in the WHERE clause. When it calculates the results, all returned data must occur within the query’s explicit time range but the GROUP BY intervals will be based on the preset time boundaries.
)
高级的GROUP BY time()语法允许用户自定义预设时间边界的开始时间。在高级语法小节的示例sql3中,将展示这种用法,它查询的结果如下:

三、高级GROUP BY time() 语法
语法如下:
SELECT <function>(<field_key>)
FROM_clause
WHERE <time_range>
GROUP BY time(<time_interval>,<offset_interval>),[tag_key] [fill(<fill_option>)]
在GROUP BY time()高级语法中,需要在SELECT子句中调用InfluxDB的函数,并在WHERE子句中指定时间区间。并且需要注意到的是,GROUP BY子句必须在WHERE子句之后!
time(time_interval,offset_interval)
在GROUP BY time()子句中的通过time_interval和offset_interval来表示一个连续的时间区间,该时间区间决定了InfluxDB如何通过时间来对查询结果进行分组。比如,如果时间区间为5m,那么它会将查询结果分为5分钟一组(如果在WHERE子句中指定了time区间,那么就是将WHERE中指定的time区间划分为没5分钟一组)。
offset_interval是持续时间文本。它向前或向后移动InfluxDB数据库的预设时间边界。offset_interval可以为正或负。fill(<fill_option>)
fill(<fill_option>)是可选的。 它可以填充那些没有数据的时间区间的值。 从 GROUP BY time intervals and fill() 部分可查看到关于这部分的更多信息。注:高级 GROUP BY time() 语法依赖于time_interval、offset_interval、以及 InfluxDB 数据库的预设时间边界来确定每组内的数据条数、以及查询结果的时间戳。
高级用法示例sql
先看如下查询sql
SELECT "water_level" FROM "h2o_feet"
WHERE "location"='coyote_creek'
AND time >= '2015-08-18T00:00:00Z'
AND time <= '2015-08-18T00:54:00Z'
查询结果:
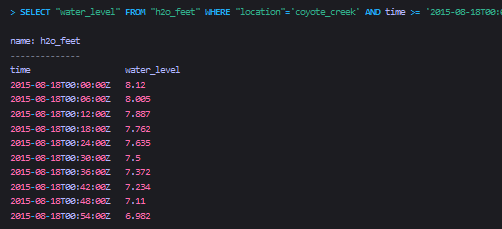
接下来将使用上面的样例数据的子集来进行演示。以下sql将按照每18m对数据进行进组,并将预设的时间界限前移。
ELECT MEAN("water_level") FROM "h2o_feet"
WHERE "location"='coyote_creek'
AND time >= '2015-08-18T00:06:00Z'
AND time <= '2015-08-18T00:54:00Z'
GROUP BY time(18m,6m)
查询结果:

可见上面sql将查询结果按照每18m为一组进行了分组,并且将预设的时间界限偏移了6分钟。
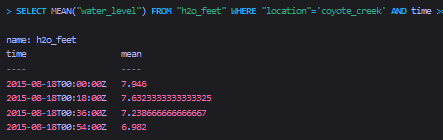
注意,对于没有offset_interval的group by time(),它的查询结果的时间边界和返回的时间戳遵循influxdb数据库的预设时间边界。下面我们看offset_interval的group by time()的查询结果:
SELECT MEAN("water_level") FROM "h2o_feet"
WHERE "location"='coyote_creek'
AND time >= '2015-08-18T00:06:00Z'
AND time <= '2015-08-18T00:54:00Z'
GROUP BY time(18m)
再看如下sql:
SELECT MEAN("water_level") FROM "h2o_feet"
WHERE "location"='coyote_creek'
AND time >= '2015-08-18T00:06:00Z'
AND time <= '2015-08-18T00:54:00Z'
GROUP BY time(18m,-12m);
查询结果
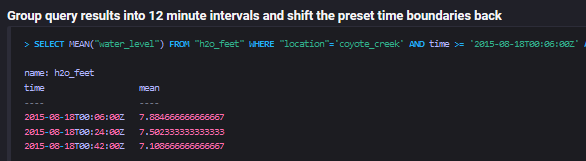
注 :该sql使用的是time(18m,-12m),offset_interval是负数,它的查询结果跟使用time(18m,6m)是一样的。因此在决定正负偏移间隔时,请随意选择最直观的选项。
GROUP BY time intervals and fill()
Fill() 可以填充那些没有数据的时间区间的值。
语法:
SELECT <function>(<field_key>) FROM_clause
WHERE <time_range>
GROUP BY time(time_interval,[<offset_interval])[,tag_key] [fill(<fill_option>)]
默认情况下,在GROUP BY time()查询结果中,若某个时间区间没有数据,则该时间区间对应的值为null。通过fill(),就可以填充那些没有数据的时间区间的值。
需要注意的是,fill()必须出现在GROUP BY子句的最后。
Fill选项
- 任何数学数值
使用给定的数学数值进行填充 - linear
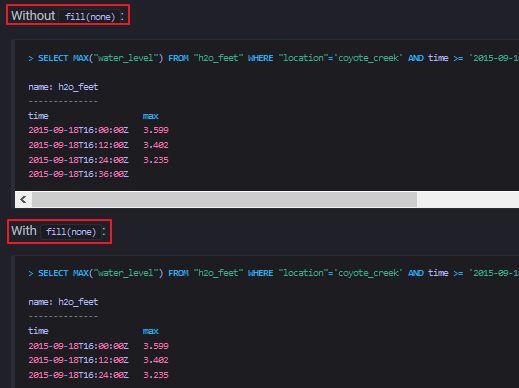
为没有数据值的时间区间线性插入数值,使得插入之后的数值,跟其他本来就有数据的区间的值成线性。(这里翻译的不是很好,看示例就能明白了) - none
若某个时间区间内没有数据,则在查询结果中该区间对应的时间戳将不显示出来 - null
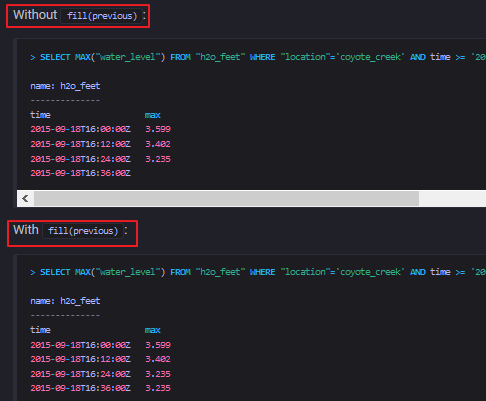
没有值的区间,显示为null。这也是默认的选项。 - previous
用前一个区间的数值来填充当前没有数据的区间的值。
示例:
fill(100)

fill(linear)

fill(none)
fill(null)

fill(previous)
6.InfluxDB-InfluxQL基础语法教程--GROUP BY子句的更多相关文章
- 8.InfluxDB-InfluxQL基础语法教程--ORDER BY子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) 在InfluxDB中 ...
- 2.InfluxDB-InfluxQL基础语法教程--目录
本文翻译自官网,官方文档地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) InfluxQL ...
- 7.InfluxDB-InfluxQL基础语法教程--INTO子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) 通过INTO子句,可 ...
- 前端开发利器 Emmet 介绍与基础语法教程
在前端开发的过程中,编写 HTML.CSS 代码始终占据了很大的工作比例.特别是手动编写 HTML 代码,效率特别低下,因为需要敲打各种“尖括号”.闭合标签等.而现在 Emmet 就是为了提高代码编写 ...
- 10.InfluxDB-InfluxQL基础语法教程--OFFSET 和SOFFSET子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) OFFSET 和SO ...
- 5.InfluxDB-InfluxQL基础语法教程--WHERE子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) WHERE子句 语法 ...
- 9.InfluxDB-InfluxQL基础语法教程--LIMIT and SLIMIT 子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) LIMIT和SLIM ...
- 4.InfluxDB-InfluxQL基础语法教程--基本select语句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) 基本语法如下: SE ...
- 3.InfluxDB-InfluxQL基础语法教程--数据说明
下面是本次演示的示例数据 表名:h2o_feet 数据示例: 数据描述 : 表h2o_feet中所存储的是6分钟时间区间内的数据. 该表有一个tag,即location,该tag有两个值,分别为coy ...
随机推荐
- Go语言标准库之net_http
Go语言内置的net/http包十分的优秀,提供了HTTP客户端和服务端的实现. net/http介绍 Go语言内置的net/http包提供了HTTP客户端和服务端的实现. HTTP协议 超文本传输协 ...
- Maven工程读取properties文件过程
1.创建需要读取的properties文件 2.在xml文件中加载配置文件 <!-- 加载配置文件 --> <context:property-placeholder locatio ...
- tarjan缩点(洛谷P387)
此题解部分借鉴于九野的博客 题目分析 给定一个 \(n\) 个点 \(m\) 条边有向图,每个点有一个权值,求一条路径,使路径经过的点权值之和最大.你只需要求出这个权值和. 允许多次经过一条边或者一个 ...
- Centos7 C++ 安装使用googletest单元测试
废话不多说,直接开始吧. 环境说明 系统环境:centos7.0 g++ 版本: g++ (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36) 查看方法: g++ -vers ...
- DevExpress的TextEdit限制输入内容的格式,比如只能输入数字
场景 Winform控件-DevExpress18下载安装注册以及在VS中使用: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/1 ...
- 解决在Filter中读取Request中的流后,后续controller或restful接口中无法获取流的问题
首先我们来描述一下在开发中遇到的问题,场景如下: 比如我们要拦截所有请求,获取请求中的某个参数,进行相应的逻辑处理:比如我要获取所有请求中的公共参数 token,clientVersion等等:这个时 ...
- eclipse下mybatis-generator-config插件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE generatorConfiguration ...
- Mysql数据处理/行转列/列转行/分割/拼接/数据复制汇总
mysql数据处理记录(使用的 Workbench) 生成随机数 逗号或分号拼接的字符串分割成多行 多行数据转化成用逗号拼接的字符串 将A表的数据添加到B表 一.生成随机数 生成18位:(19位就加颗 ...
- localStorage详细总结
一.localStorage简介: 在HTML5中,新加入了一个localStorage特性,这个特性主要是用来作为本地存储来使用的,解决了cookie存储空间不足的问题(cookie中每条cooki ...
- charles 自动存储/auto_save
本文参考:charles 自动存储 自动保存工具 auto_save "自动保存"工具会在你设定的间隔后,自动保存并清除抓取到的内容.假设你设置了3分钟,则每隔三分钟会保存一次, ...