(转)深入解析TensorFlow中滑动平均模型与代码实现
指数加权平均算法的原理
TensorFlow中的滑动平均模型使用的是滑动平均(Moving Average)算法,又称为指数加权移动平均算法(exponenentially weighted average),这也是ExponentialMovingAverage()函数的名称由来。
先来看一个简单的例子,这个例子来自吴恩达老师的DeepLearning课程,个人强烈推荐初学者都看一下。
开始例子。首先这是一年365天的温度散点图,以天数为横坐标,温度为纵坐标,你可以看见各个小点分布在图上,有一定的曲线趋势,但是并不明显
接着,如果我们要看出这个温度的变化趋势,很明显需要做一点处理,也即是我们的主题,用滑动平均算法处理。
首先给定一个值v0,然后我们定义每一天的温度是a1,a2,a3·····
接着,我们计算出v1,v2,v3····来代替每一天的温度,也就是上面的a1,a2,a3
计算方法是:v1 = v0 * 0.9 + a1 (1-0.9),v2= v1 0.9 + a2 (1-0.9),v3= v2 0.9 + a3 (1-0.9)···,也就是说,每一天的温度改变为前一天的v值 0.9 + 当天的温度 * 0.1,vt = v(t-1) * 0.9 + at * 0.1,把所有的v计算完之后画图,红线就是v的曲线:
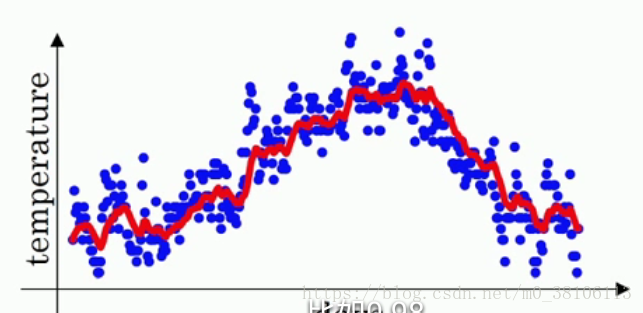
v值就是指数加权平均数,整个过程就是指数加权平均算法,它很好的把一年的温度曲线给拟合了出来。把0.9抽象为β,总结为vt = v(t-1) * β + at * (1-β)。
β这个值的意义是什么?实际上vt ≈ 1/(1 - β) 天的平均温度,例如:假设β等于0.9,1/(1 - β) 就等于10,也就是vt等于前十天的平均温度,这个说可能不太看得出来;假设把β值调大道接近1,例如,将β等于0.98,1/(1-β)=50,按照刚刚的说法也就是前50天的平均温度,然后求出v值画出曲线,如图所示:
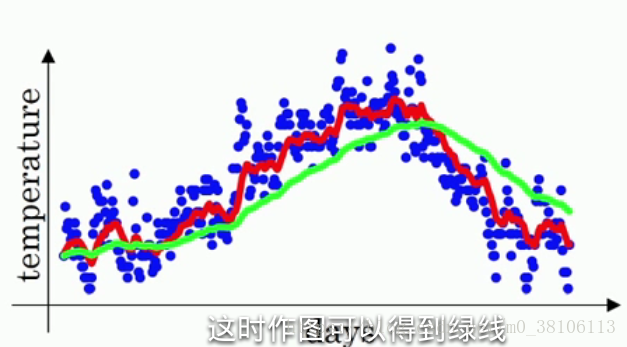
绿线就是β等于0.98时候的曲线,可以明显看到绿线比红线的变化更迟,红线达到某一温度,绿线要过一阵子才能达到相同温度。因为绿线是前50天的平均温度,变化就会更加缓慢,而红线是最近十天的平均温度,只要最近十天的温度都是上升,红线很快就能跟着变化。所以直观的理解就是,vt是前1/(1-β)天的平均温度。
再看看另一个极端情况:β等于0.5,意味着vt≈最近两天的平均温度,曲线如下黄线:
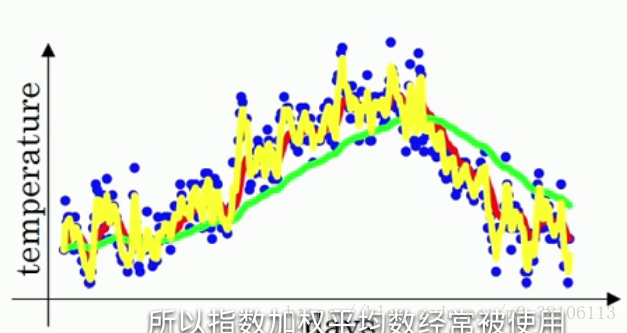
和原本的温度很相似,但曲线的波动幅度也相当大!
然后说一下这个滑动平均模型和深度学习有什么关系:通常来说,我们的数据也会像上面的温度一样,具有不同的值,如果使用滑动平均模型,就可以使得整体数据变得更加平滑——这意味着数据的噪音会更少,而且不会出现异常值。但是同时β太大也会使得数据的曲线右移,和数据不拟合。需要不断尝试出一个β值,既可以拟合数据集,又可以减少噪音。
滑动平均模型在深度学习中还有另一个优点:它只占用极少的内存
当你在模型中计算最近十天(有些情况下远大于十天)的平均值的时候,你需要在内存中加载这十天的数据然后进行计算,但是指数加权平均值约等于最近十天的平均值,而且根据vt = v(t-1) * β + at * (1-β),你只需要提供at这一天的数据,再加上v(t-1)的值和β值,相比起十天的数据这是相当小的数据量,同时占用更少的内存。
偏差修正
指数加权平均值通常都需要偏差修正,TensorFlow中提供的ExponentialMovingAverage()函数也带有偏差修正。
首先看一下为什么会出现偏差,再来说怎么修正。当β等于0.98的时候,还是用回上面的温度例子,曲线实际上不是像绿线一样,而是像紫线:
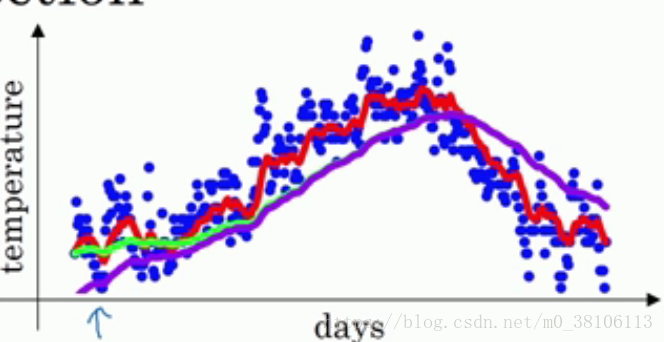
你可以注意到在紫线刚刚开始的时候,曲线的值相当的低,这是因为在一开始的时候并没有50天(1/(1-β)为50)的数据,而是只有寥寥几天的数据,相当于少加了几十天的数据,所以vt的值很小,这和实际情况的差距是很大的,也就是出现的偏差。
而在TensorFlow中的ExponentialMovingAverage()采取的偏差修正方法是:使用num_updates来动态设置β的大小
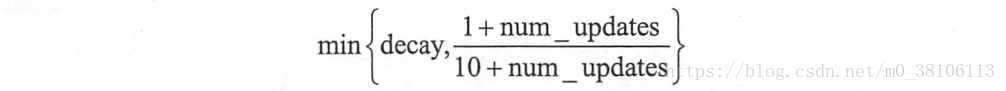
在数据迭代的前期,数据量比较少的时候,(1+num_updates)/(10+num_updates)的值比较小,使用这个值作为β来进行vt的计算,所以在迭代前期就会像上面的红线一样,和原数据更加接近。举个例子,当天数是第五天,β为0.98,那么(1+num_updates)/(10+num_updates) = 6/15 = 0.4,相当于最近1.6天的平均温度,而不是β=0.98时候的50天,这样子就做到了偏差修正。
滑动平均模型的代码实现
看到这里你应该大概了解了滑动平均模型和偏差修正到底是怎么回事了,接下来把这个想法对应到TensorFlow的代码中。
首先明确一点,TensorFlow中的ExponentialMovingAverage()是针对权重weight和偏差bias的,而不是针对训练集的。如果你现在训练集中实现这个效果,需要自己设计代码。
为什么要对w和b使用滑动平均模型呢?因为在神经网络中,
更新的参数时候不能太大也不能太小,更新的参数跟你之前的参数有联系,不能发生突变。一旦训练的时候遇到个“疯狂”的参数,有了滑动平均模型,疯狂的参数就会被抑制下来,回到正常的队伍里。这种对于突变参数的抑制作用,用专业术语讲叫鲁棒性,鲁棒性就是对突变的抵抗能力,鲁棒性越好,这个模型对恶性参数的提抗能力就越强。
在TensorFlow中,ExponentialMovingAverage()可以传入两个参数:衰减率(decay)和数据的迭代次数(step),这里的decay和step分别对应我们的β和num_updates,所以在实现滑动平均模型的时候,步骤如下:
1、定义训练轮数step
2、然后定义滑动平均的类
3、给这个类指定需要用到滑动平均模型的变量(w和b)
4、执行操作,把变量变为指数加权平均值
# 1、定义训练的轮数,需要用trainable=False参数指定不训练这个变量,
# 避免这个变量被计算滑动平均值
global_step = tf.Variable(0, trainable=False)
# 2、给定滑动衰减率和训练轮数,初始化滑动平均类
# 定训练轮数的变量可以加快训练前期的迭代速度
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,
global_step)
# 3、用tf.trainable_variable()获取所有可以训练的变量列表,也就是所有的w和b
# 全部指定为使用滑动平均模型
variables_averages_op = variable_averages.apply(tf.trainable_variables())
# 反向传播更新参数之后,再更新每一个参数的滑动平均值,用下面的代码可以一次完成这两个操作
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name="train")设置完使用滑动平均模型之后,只需要在每次使用反向传播的时候改为使用run.(train_op)就可以正常执行了。
(转)深入解析TensorFlow中滑动平均模型与代码实现的更多相关文章
- TensorFlow中的卷积函数
前言 最近尝试看TensorFlow中Slim模块的代码,看的比较郁闷,所以试着写点小的代码,动手验证相关的操作,以增加直观性. 卷积函数 slim模块的conv2d函数,是二维卷积接口,顺着源代码可 ...
- tensorflow笔记:多层LSTM代码分析
tensorflow笔记:多层LSTM代码分析 标签(空格分隔): tensorflow笔记 tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) ten ...
- tensorflow:实战Google深度学习框架第四章02神经网络优化(学习率,避免过拟合,滑动平均模型)
1.学习率的设置既不能太小,又不能太大,解决方法:使用指数衰减法 例如: 假设我们要最小化函数 y=x2y=x2, 选择初始点 x0=5x0=5 1. 学习率为1的时候,x在5和-5之间震荡. im ...
- Tensorflow 中的优化器解析
Tensorflow:1.6.0 优化器(reference:https://blog.csdn.net/weixin_40170902/article/details/80092628) I: t ...
- day-18 滑动平均模型测试样例
为了使训练模型在测试数据上有更好的效果,可以引入一种新的方法:滑动平均模型.通过维护一个影子变量,来代替最终训练参数,进行训练模型的验证. 在tensorflow中提供了ExponentialMovi ...
- 转:二十一、详细解析Java中抽象类和接口的区别
转:二十一.详细解析Java中抽象类和接口的区别 http://blog.csdn.net/liujun13579/article/details/7737670 在Java语言中, abstract ...
- CNN中的卷积核及TensorFlow中卷积的各种实现
声明: 1. 我和每一个应该看这篇博文的人一样,都是初学者,都是小菜鸟,我发布博文只是希望加深学习印象并与大家讨论. 2. 我不确定的地方用了"应该"二字 首先,通俗说一下,CNN ...
- TensorFlow中的通信机制——Rendezvous(二)gRPC传输
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 本篇是TensorFlow通信机制系列的第二篇文章,主要梳理使用gRPC网络传 ...
- TensorFlow中的通信机制——Rendezvous(一)本地传输
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 在TensorFlow源码中我们经常能看到一个奇怪的词——Rendezvous ...
随机推荐
- 分布式事物 - 基于RPC调用 - TCC模式
前提 前端业务(主服务)可以以同步或异步调用TCC框架,或者TCC框架本身就是同步异步兼备的. 假定TCC框架拥有断电后的自动恢复能力.同时,在下游业务出现无限失败的情况下,也会进行无限的重试,以达到 ...
- MySQL数据库Group by分组之后再统计数目Count(*)与不分组直接统计数目的区别
简述问题“统计最新时刻处于某一状态的设备的数量” 1. 首先子查询结果,可以看到每个设备最新的状态信息 2.1 在子查询的基础上,对设备状态进行分组,进行统计每个状态的设备数量 2.1.1 可以看到处 ...
- android studio 常见编译问题及解决思路总结
问题一:编译运行成功后放置一段时间后再运行会报错 这个问题让我纠结了不少时间,最后才发现遇到类似的错误,clear一下project就好了.这个一般是上次生成的临时文件和这次的有冲突造成的. 问题二: ...
- java开发,入职半年。对未来迷茫,如何发展?
蛮多人私密我一些问题,关于面试,关于技术的,我只能说有些路只能靠自己去走,没人可以帮到自己,哪怕偶尔帮一到两次,但是技术的路这么长,总归需要自己独自成长的.附一张自己藏书的照片,与各位共勉 工作三年多 ...
- Android项目实战之高仿网易云音乐创建项目和配置
这一节我们来讲解创建项目:说道大家可能就会说了,创建项目还有谁不会啊,还需要讲吗,别急听我慢慢到来,肯定有你不知道的. 使用项目Android Studio创建项目我们这里就不讲解了,主要是讲解如何配 ...
- dedecmsV5.7 插入记录并返回刚插入数据的自增ID
//插入一条数据 $sql = "INSERT INTO `table_name` (`name`,age) VALUES ('小明','23')"; $dsql->SetQ ...
- 使用Python轻松批量压缩图片
在互联网,图片的大小对一个网站的响应速度有着明显的影响,因此在提供用户预览的时候,图片往往是使用压缩后的.如果一个网站图片较多,一张张压缩显然很浪费时间.那么接下来,我就跟大家分享一个批量压缩图片的方 ...
- Pinpoint-agent监控springboot编译的jar启动方式
由于springboot在打包发版时已经将tomcat容器内嵌到jar文件中,可以通过以下命令来使pinpoint-agent监控生成的jar服务 java -javaagent:D:\Softwar ...
- 记录python上传文件的坑(2)
描述: 1.之前在写项目mock代码时,碰到一个上传文件的接口,但项目接口本身有token保护机制,碰到token失效时,需要重新获取一次token后,再次对上传文件发起请求,在实际调用中发现,第一次 ...
- 腾讯云服务器ubuntu18.04部署禅道系统
踩了不少坑,记录一下. 基于ubuntu18.04 一开始按照网上的攻略下载安装包 ZenTaoPMS.9.8.3.zbox_64.tar.gz,通过FileZilla传到linux的/opt下面,解 ...