Elastic Stack 开源的大数据解决方案
目的
本文主要介绍的内容有以下三点:
一. Elastic Stack是什么以及组成部分
二. Elastic Stack前景以及业务应用
三. Elasticsearch原理(索引方向)
四. Elasticsearch相对薄弱的地方
一、Elastic Stack是什么以及组成部分
介绍Elastic Stack是什么,其实只要一句话就可以,就是: 一套完整的大数据处理堆栈,从摄入、转换到存储分析、可视化。
它是不同产品的集合,各司其职,形成完整的数据处理链,因此Elastic Stack也可以简称为BLEK。
Beats 轻量型数据采集器
Logstash 输入、过滤器和输出
Elasticsearch 查询和分析
Kibana 可视化,可自由选择如何呈现数据
1. Beats - 全品类采集器,搞定所有数据类型
Filebeat(日志文件):对成百上千、甚至上万的服务器生成的日志汇总,可搜索。
Metricbeat(指标): 收集系统和服务指标,CPU 使用率、内存、文件系统、磁盘 IO 和网络 IO 统计数据。
Packetbeat(网络数据):网络数据包分析器,了解应用程序动态。
Heartbeat(运行时间监控):通过主动探测来监测服务的可用性
......
Beats支持许许多多的beat,这里列的都是比较的常用的beat,了解更多可以点击链接:Beats 社区
2. Logstash - 服务器端数据处理管道
介绍Logstash之前,我们先来看下Linux下常用的几个命令
cat alldata.txt | awk ‘{print $1}’ | sort | uniq | tee filterdata.txt
只要接触过Linux同学,应该都知道这几个命名意思
cat alldata.txt #将alldata.txt的内容输出到标准设备上
awk ‘{print $1}’ #对上面的内容做截取,只取每一行第一列数据
sort | uniq #对截取后的内容,进行排序和唯一性操作
tee filterdata.txt #将上面的内容写到filterdata.txt
上面的几个简单的命令就可以看出来,这是对数据进行了常规的处理,用名词修饰的话就是:数据获取/输入、数据清洗、数据过滤、数据写入/输出
而Logstash做的也是相同的事(看下图)。
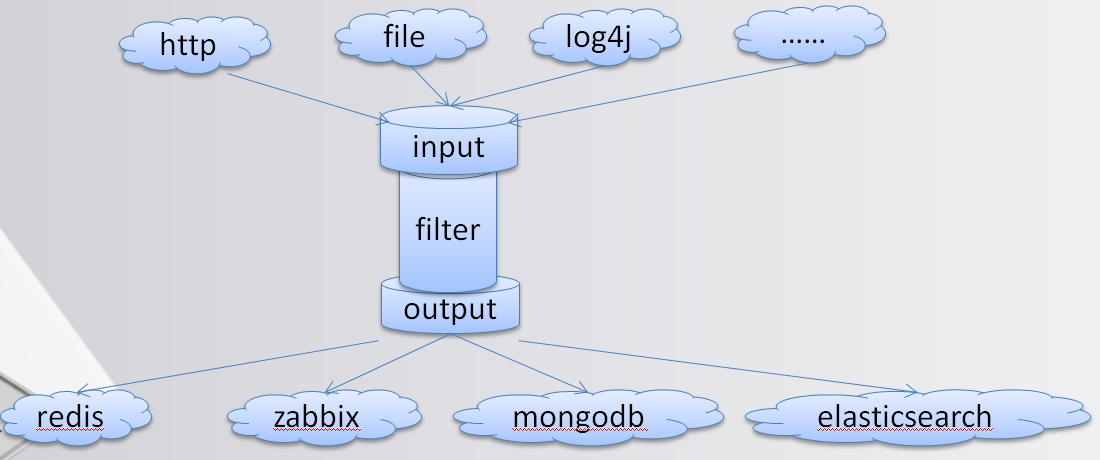
将系统的日志文件、应用日志文件、系统指标等数据,输入到Input,再通过数据清洗以及过滤,输入到存储设备中,这里当然是输入到Elasticsearch
3. Elasticsearch - 分布式文档存储、RESTful风格的搜索和数据分析引擎
Elasticsearch主要也是最原始的功能就是搜索和分析功能。这里就简单说一下,下面讲原理的时候会着重讲到Elasticsearch
搜索:全文搜索,完整的信息源转化为计算机可以识别、处理的信息单元形成的数据集合 。
分析:相关度,搜索所有内容,找到所需的具体信息(词频或热度等对结果排序)
4. Kibana- 可视化
可视化看下图(来源官网)便知

可以对日志分析、业务分析等做可视化
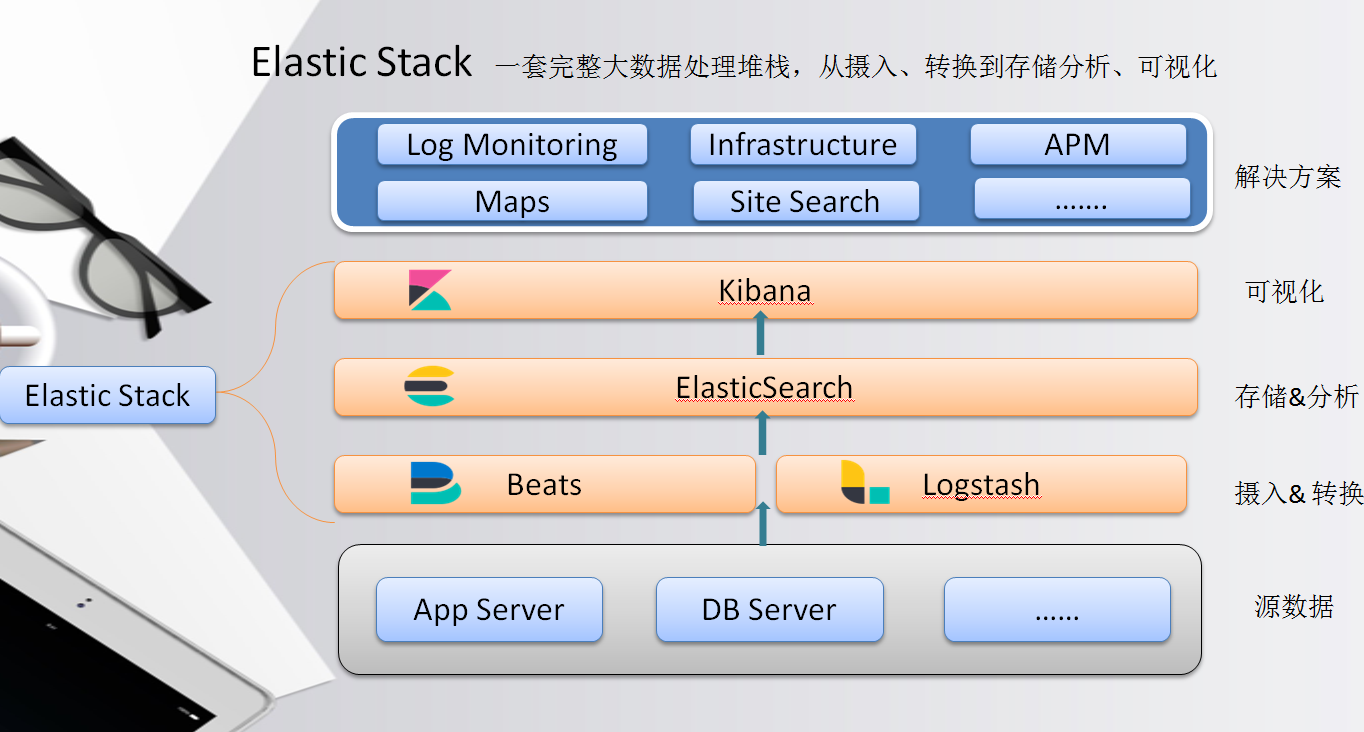
现在从总体上来了解下,在心中对Elastic Stack有个清楚的认知(下图)。
二、Elastic Stack前景以及业务应用
1. DB-Engines 排名
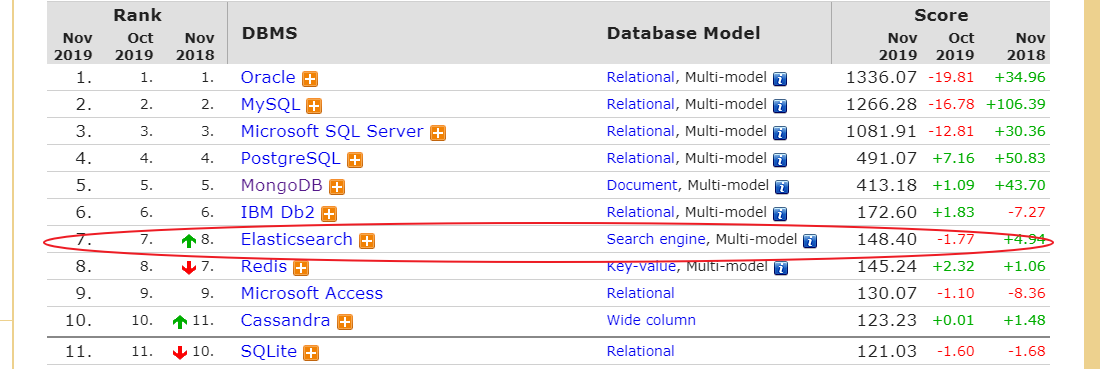
Elasticsearch是Elastic Stack核心,由图可以看出在搜索领域Elasticsearch暂时没有对手。
2. ES社区
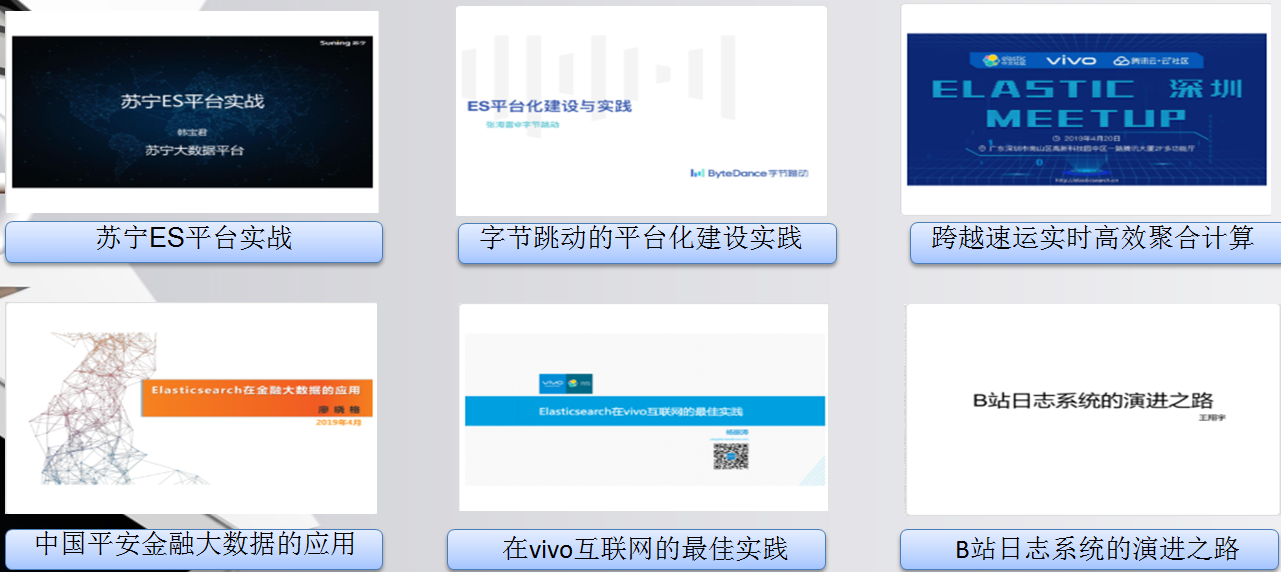
ES中文社区也是相当活跃的,会定期做一下分享,都是大公司的宝贵经验,值得参考。
3. 2018年携程的使用情况(让我们看看能处理多大的数据)
集群数量是94个,最小的集群一般是3个节点。全部节点数量大概700+。
最大的一个集群是做日志分析的,其中数据节点330个,最高峰一天产生1600亿文档,写入值300w/s。
现在有2.5万亿文档,大概是几个PB的量
三、Elasticsearch(ES)原理
因为篇目有限,本篇只介绍ES的索引原理。
ES为什么可以做全文搜索,主要就是用了倒排索引,先来看下面的一张图

看图可以简单的理解倒排索引就是:关键字 + 页码
对倒排索引有个基本的认识后,下面来做个简单的数据例子。

现在对Name做到排索引,记住:关键字 + ID(页码)。
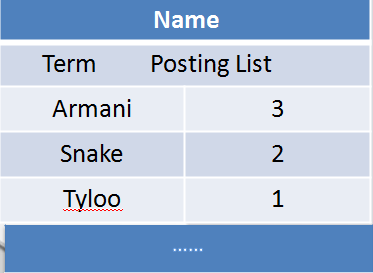
对Age做到排索引。

对Intersets做到排索引。
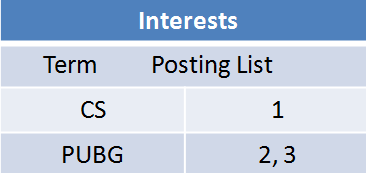
现在搜索Age等于18的,通过倒排索引就可以快速得到1和3的id,再通过id就可以得到具体数据,看,这样是不是快的狠。
如果是用Mysql等关系数据库,现在有十多亿数据(大数据嘛),就要一条一条的扫描下去找id,效率可想而知。而用倒排索引,找到所有的id就轻轻松松了。
在ES中,关键词叫Term,页码叫Posting List。
但这样就行了吗? 如果Name有上亿个Term,要找最后一个Term,效率岂不是还是很低?
再来看Name的倒排索引,你会发现,将Armani放在了第一个,Tyloo放在了第三个,可以看出来,对Term做了简单的排序。虽然简单,但很实用。这样查找Term就可以用二分查找法来查找了,将复杂度由n变成了logn。
在ES中,这叫Term Dictionary。
到这里,再来想想MySQL的b+tree, 你有没有发现原理是差不多的,那为什么说ES搜索比MySQL快很多,究竟快在哪里? 接下来再看。
有一种数据结构叫Trie树,又称前缀树或字典树,是一种有序树。这种数据结构的好处就是可以压缩前缀和提高查询数据。
现在有这么一组Term: apps, apple, apply, appear, back, backup, base, bear,用Trie树表示如下图。
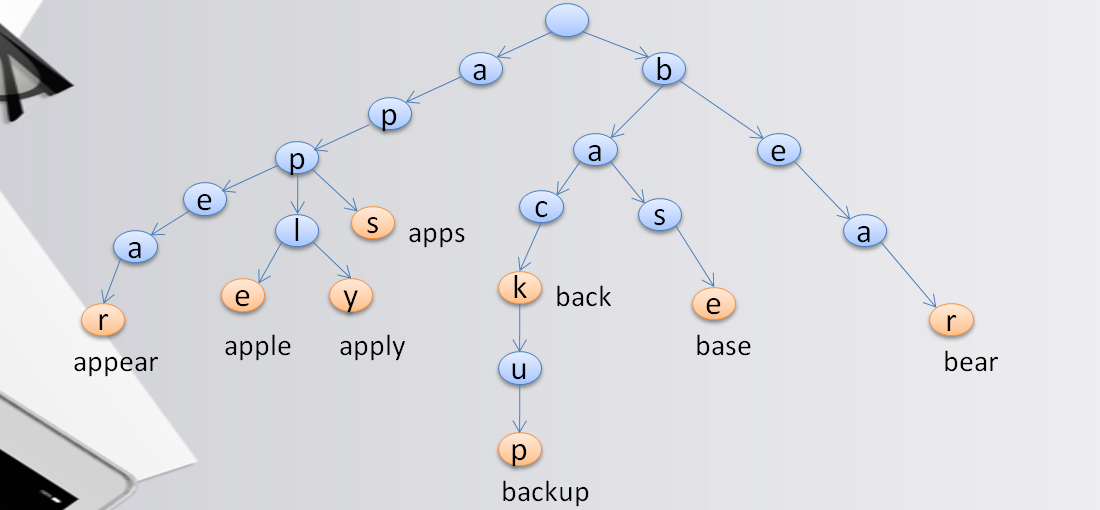
通过线路路径字符连接就可以得到完成的Term,并且合用了前缀,比如apps, apple, apply, appear合用了app路径,节省了大量空间。
这个时候再来找base单词,立即就可以排除了a字符开头的单词,比Term Dictionary快了不知多少。
在ES中,这叫Term Index
现在我们再从整体看下ES的索引
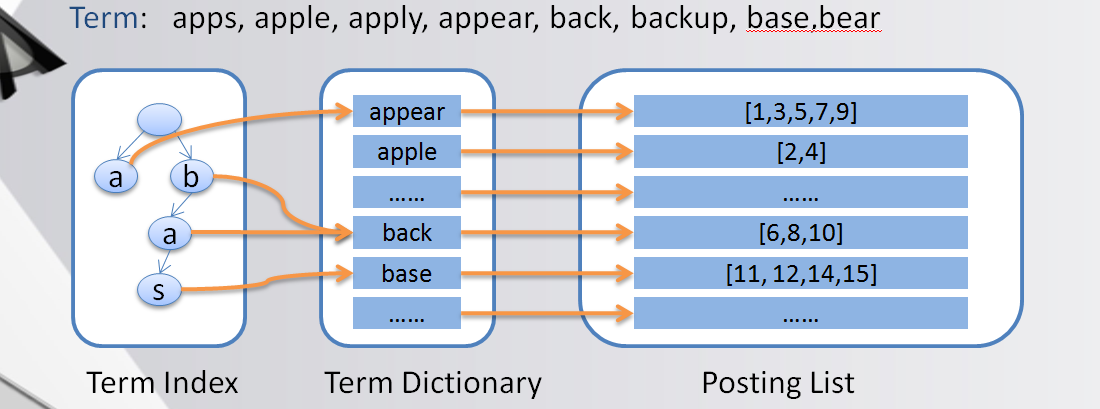
先通过Trie树快速定位block(相当于页码), 再到Term Dictionary 做二分查找,得到Posting List。
索引优化
ES是为了大数据而生的,这意味着ES要处理大量的数据,它的Term数据量也是不可想象的。比如一篇文章,要做全文索引,就会对全篇的内容做分词,会产生大量的Term,而ES查询的时候,这些Term肯定要放在内存里面的。
虽然Trie树对前缀做了压缩,但在大量Term面前还是不够,会占用大量的内存使用,于是就有ES对Trie树进一步演化。
FST(Finite State Transducer )确定无环有限状态转移器 (看下图)
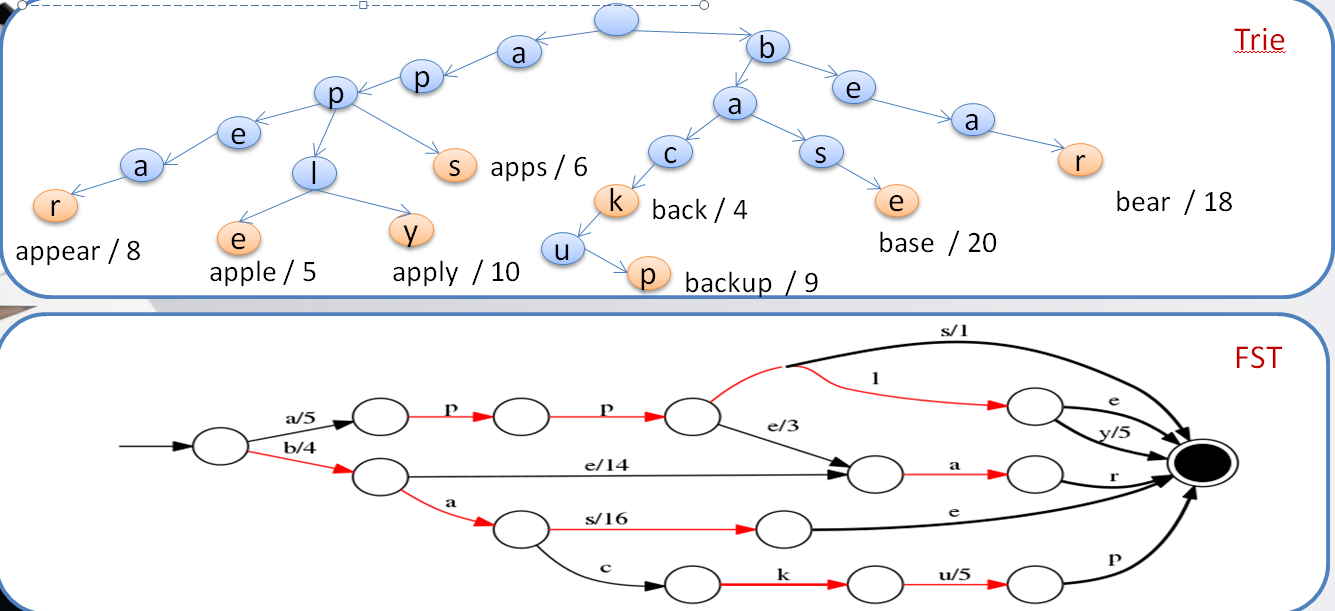
可以看appear、bear 对共同的后缀做了压缩。
Posting List磁盘压缩
假设有一亿的用户数据,现在对性别做搜索,而性别无非两种,可能"男"就有五千万之多,按int4个字节存储,就要消耗50M左右的磁盘空间,而这仅仅是其中一个Term。
那么面对成千上万的Term,ES究竟是怎么存储的呢?接下来,就来看看ES的压缩方法。
**Frame Of Reference (FOR) 增量编码压缩,将大数变小数,按字节存储 **
只要能把握“增量,大数变小数,按字节存储”这几个关键词,这个算法就很好理解,现在来具体看看。
现在有一组Posting List:[60, 150, 300,310, 315, 340], 按正常的int型存储,size = 6 * 4(24)个字节。
按增量存储:60 + 90(150)+ 150(300) + 10(310) + 5(315)+ 25(340),也就是[60, 90, 150, 10, 5, 25],这样就将大数变成了小数。
切分成不同的block:[60, 90, 150]、[10, 5, 25],为什么要切分,下面讲。
按字节存储:对于[60, 90, 150]这组block,究竟怎么按字节存储,其实很简单,就是找其中最大的一个值,看X个比特能表示这个最大的数,那么剩下的数也用X个比特表示(切分,可以尽可能的压缩空间)。
[60, 90, 150]最大数150 < 2^8 = 256,也就是这组每个数都用8个比特表示,也就是 3*8 = 24个比特,再除以8,也就是3个字节存在,再加上一个8的标识位(说明每个数是8个比特存储),占用一个字节,一共4个字节。
[10, 5, 25]最大数25 < 2^5 = 32,每个数用5个比特表示,3*5=15比特,除以8,大约2个字节,加上5的标识位,一共3个字节。
那么总体size = 4 + 3(7)个字节,相当于24个字节,大大压缩了空间。
再看下图表示

Posting List内存压缩
同学们应该都知道越复杂的算法消耗的CPU性能就越大,比如常见的https,第一次交互会用非对称密码来验证,验证通过后就转变成了对称密码验证,FOR同样如此,那么ES是用什么算法压缩内存中的Posting List呢?
Roaring Bitmaps 压缩位图索引
Roaring Bitmaps 涉及到两种数据结构 short[] 、bitmap。
short好理解就是2个字节的整型。
bitmap就是用比特表示数据,看下面的例子。
Posting List:[1, 2, 4, 7, 10] -> [1, 1, 0, 1, 0, 0, 1,0, 0, 1],取最大的值10,那么就用10个比特表示这组Posting List,第1, 2, 4, 7, 10位存在,就将相对应的“位”置为1,其他的为0。
但这种bitmap数据结构有缺陷,看这组Posting List: [1, 3, 100000000] -> [1, 0, 1, 0, 0, 0, …, 0, 0, 1 ],最大数是1亿,就要1亿的比特表示,这么算下来,反而消耗了更多的内存。
那如何解决这个问题,其实也很简单,跟上面一样,将大数变成小数。
看下图:
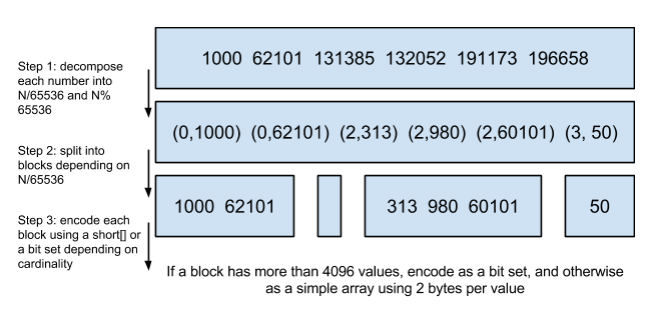
第一步:将每个数除以65536,得到(商,余数)。
第二步:按照商,分成不同的block,也就是相同的商,放在同一个block里面,余数就是这个值在这个block里面的位置(永远不会超过65536,余数嘛)。
第三步:判断底层block用什么数据结构存储数据,如果block里面的余数的个数超过4096个,就用short存储,反之bitmap。
上面那个图是官网的图,看下我画的图,可能更好理解些。

到这里,ES的索引原理就讲完了,希望大家都能理解。
四、Elasticsearch(ES)相对薄弱的地方
1. 多表关联
其实ES有一个很重要的特性这里没有介绍到,也就是分布式,每一个节点的数据和,才是整体数据。
这也导致了多表关联问题,虽然ES里面也提供了Nested& Join 方法解决这个问题,但这里还是不建议用。
那这个问题在实际应用中应该如何解决? 其实也很简单,装换思路,ES无法解决,就到其他层解决,比如:应用层,用面向对象的架构,拆分查询。
2. 深度分页
分布式架构下,取数据便不是那么简单,比如取前1000条数据,如果是10个节点,那么每个节点都要取1000条,10个节点就是10000条,排序后,返回前1000条,如果是深度分页就会变的相当的慢。
ES提供的是Scroll + Scroll_after,但这个采取的是缓存的方式,取出10000条后,缓存在内存里,再来翻页的时候,直接从缓存中取,这就代表着存在实时性问题。
来看看百度是怎么解决这个问题的。
一样在应用层解决,翻页到一定的深度后,禁止翻页。
3. 更新应用
频繁更新的应用,用ES会有瓶颈,比如一些游戏应用,要不断的更新数据,用ES不是太适合,这个看大家自己的应用情况。
Elastic Stack 开源的大数据解决方案的更多相关文章
- HP PCS 云监控大数据解决方案
——把数据从分散统一集中到数据中心 基于HP分布式并行计算/存储技术构建的云监控系统即是通过“云高清摄像机”及IaaS和PaaS监控系统平台,根据用户所需(SaaS)将多路监控数据流传送给“云端”,除 ...
- 浅析基于微软SQL Server 2012 Parallel Data Warehouse的大数据解决方案
作者 王枫发布于2014年2月19日 综述 随着越来越多的组织的数据从GB.TB级迈向PB级,标志着整个社会的信息化水平正在迈入新的时代 – 大数据时代.对海量数据的处理.分析能力,日益成为组织在这个 ...
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- 转:浅析基于微软SQL Server 2012 Parallel Data Warehouse的大数据解决方案
综述 随着越来越多的组织的数据从GB.TB级迈向PB级,标志着整个社会的信息化水平正在迈入新的时代 – 大数据时代.对海量数据的处理.分析能力,日益成为组织在这个时代决胜未来的关键因素,而基于大数据的 ...
- H2O是开源基于大数据的机器学习库包
H2O是开源基于大数据的机器学习库包 H2O能够让Hadoop做数学,H2O是基于大数据的 统计分析 机器学习和数学库包,让用户基于核心的数学积木搭建应用块代码,采取类似R语言 Excel或JSON等 ...
- 使用Stack堆栈集合大数据运算
使用Stack堆栈集合大数据运算 package com.sta.to; import java.util.Iterator; import java.util.Stack; public class ...
- 转:甲骨文发布大数据解决方案 含最新版NoSQL数据库
原文出处: http://www.searchdatabase.com.cn/showcontent_88247.htm 以下是部分节选: 最新发布的大数据创新成果包括: Oracle Big Dat ...
- dkh人力资源大数据解决方案整体架构
大数据技术的应用正在潜移默化改变着我们的日常生活习惯和工作方式,很多看起来有点“不可思议”的事情也渐渐被我们“习以为常”.大数据可能在国内的起步较晚,但我们可能却是对大数据应用最好的了代表了.前些时候 ...
- MongoDB + Spark: 完整的大数据解决方案
Spark介绍 按照官方的定义,Spark 是一个通用,快速,适用于大规模数据的处理引擎. 通用性:我们可以使用Spark SQL来执行常规分析, Spark Streaming 来流数据处理, 以及 ...
随机推荐
- selenium+testNG自动化测试框架搭建
自动化测试框架搭建 1 Java环境的搭建 1.1访问oracle的官网下载最新版本的jdk http://www.oracle.com/technetwork/java/javase/downloa ...
- 04-07 scikit-learn库之梯度提升树
目录 scikit-learn库之梯度提升树 一.GradietBoostingClassifier 1.1 使用场景 1.2 参数 1.3 属性 1.4 方法 二.GradietBoostingCl ...
- js中try、catch、finally的执行规则
首先一个常识就是,在浏览器执行JS脚本过程中,当出现脚本错误,并且你没有手动进行异常捕捉时,他会在浏览器下面出现黄色的叹号,这是正常的,这也不是最重要的,最重要的是,出错行以下的所有JS代码将中停执行 ...
- 第一次 在Java课上的编程
第一次在java课上的编程(使用参数输入求和): 代码: public class He { public static void main(String[] args) { ...
- .net cookie跨域请求指定请求域名
HttpCookie cookie = new HttpCookie("OrderApiCookie"); //初使化并设置Cookie的名称 cookie.HttpOnly = ...
- java接口的演变(jdk8的default、静态方法,jdk9的私有方法、私有静态方法)
目录: 接口的定义 jdk7-9,接口属性的变化 jdk8,default.public static method的提出解决了什么问题,使用时需要注意什么 jdk9的补充(引入private met ...
- drf框架接口文档
drf框架接口文档 REST framework可以自动帮助我们生成接口文档. 接口文档以网页的方式呈现. 自动接口文档能生成的是继承自APIView及其子类的视图. 一.安装依赖 pip insta ...
- vue——同一局域网内访问项目
1.想要在手机上访问本地的vue项目,首先要保证手机和电脑处在同一局域网内(连着同一个无线网) 2.将你电脑的ip设置为固定ip(ipconfig查找本地的ip,然后修改它,改为你想变的数字) 3.在 ...
- UltraEdit等软件详细安装破解教程,附注册机(全网独家可用)
--- title: "UltraEdit等软件详细安装破解教程,附注册机(全网独家可用)" categories: soft tags: soft author: LIUREN ...
- Spring容器启动源码解析
1. 前言 最近搭建的工程都是基于SpringBoot,简化配置的感觉真爽.但有个以前的项目还是用SpringMvc写的,看到满满的配置xml文件,却有一种想去深入了解的冲动.折腾了好几天,决心去写这 ...