LinkedList源码分析(jdk1.8)
LinkedList概述
LinkedList 是 Java 集合框架中一个重要的实现,我们先简述一下LinkedList的一些特点:
LinkedList底层采用的双向链表结构;LinkedList支持空值和重复值(List的特点);LinkedList实现Deque接口,具有双端队列的特性,也可以作为栈来使用;LinkedList存储元素过程中,无需像 ArrayList 那样进行扩容,但存储元素的节点需要额外的空间存储前驱和后继的引用;LinkedList在链表头部和尾部插入效率比较高,但在指定位置进行插入时,需要定位到该位置处的节点,此操作的时间复杂度为O(N);LinkedList是非线程安全的集合类,并发环境下,多个线程同时操作 LinkedList,会引发不可预知的异常错误。
LinkedList继承体系
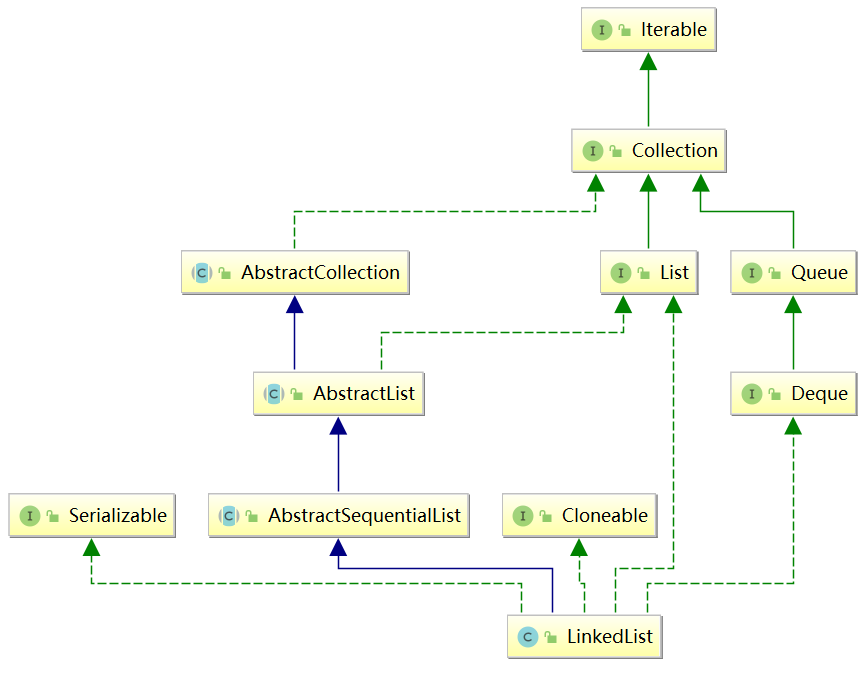
直接通过idea查看一下LinkedList的继承体系,体系结构比较复杂,一点点看。
- 继承自 AbstractSequentialList;
- 实现了 List 和 Deque 接口;
- 实现序列化接口;
- 实现了Cloneable接口
这里简单说一下AbstractSequentialList这个类,该类提供一套基本的基于顺序访问的接口,通过继承此类,子类仅需实现部分代码即可拥有完整的一套访问某种序列表(比如链表)的接口。AbstractSequentialList 提供的方法基本上都是通过 ListIterator 实现的,比如下面的get和add方法。但是虽然LinkedList 继承了 AbstractSequentialList,却并没有直接使用父类的方法,而是重新实现了一套的方法,后面我们会讲到这些方法的实现。
public E get(int index) {try {return listIterator(index).next();} catch (NoSuchElementException exc) {throw new IndexOutOfBoundsException("Index: "+index);}}public void add(int index, E element) {try {listIterator(index).add(element);} catch (NoSuchElementException exc) {throw new IndexOutOfBoundsException("Index: "+index);}}// 留给子类实现public abstract ListIterator<E> listIterator(int index);
另外的就是文章开头概述的,LinkedList实现了Deque接口,具有双端队列的特点。
LinkedList的成员属性
//记录链表中的实际元素个数transient int size = 0;//维护链表的首结点引用transient Node<E> first;//维护链表的尾节点引用transient Node<E> last;
可以看到first和last都是Node类型的,所以我们简单看一下LinkedList中的这个内部类
private static class Node<E> {E item; //结点中存放的实际元素Node<E> next; //维护结点的后继结点Node<E> prev; //维护结点的前驱结点//构造方法,创建一个新的结点,参数为:前驱结点,插入元素引用,后继节点Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
可以看到Node这个静态内部类的结构也是比较简单的,每个结点维护的就是自己存储的元素信息+前驱结点引用+后继节点引用。这里就不做过多的阐述,下面简单看看LinkedList的构造方法
LinkedList的构造方法
//构造一个空的集合(链表为空)public LinkedList() {}//先调用自己的无参构造方法构造一个空的集合,然后将Collection集合中的所有元素加入该链表中//如果传入的Collection为空,会抛出空指针异常public LinkedList(Collection<? extends E> c) {this();addAll(c);}
LinkedList的主要方法
add方法
LinkedList实现的添加方法主要有下面几种
在链表尾部添加结点(linkLast方法)
在链表首部添加元素(linkFirst方法)
在链表中间添加元素(linkBefore方法)
下面我们看看这三种方法的实现。
(1)linkLast方法
public void addLast(E e) {linkLast(e);}
在addLast方法中直接就是调用了linkLast方法实现结点的添加(没有返回值,所以add方法一定是返回true的),所以下面我们看看这个方法:
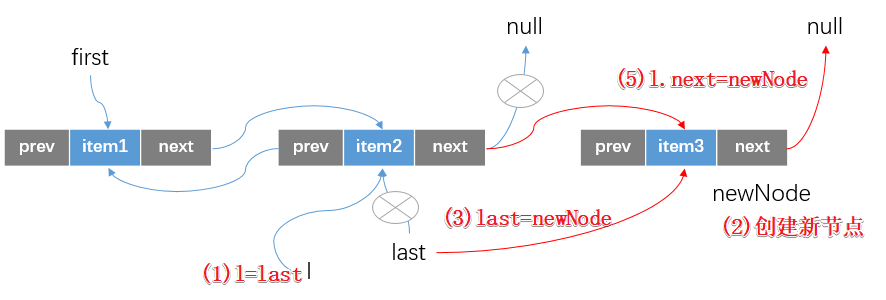
void linkLast(E e) {//(1)获得当前链表实例的全局后继节点final Node<E> l = last;//(2)创建一个新的结点,从Node的构造方法我们就能知道//这个新的结点中存放的元素item为当前传入的泛型引用,前驱结点为全局后继结点,后继节点为null//(即相当于要将这个新节点作为链表的新的后继节点)final Node<E> newNode = new Node<>(l, e, null);// Node(Node<E> prev, E element, Node<E> next){}//(3)更新全局后继节点的引用last = newNode;//(4)如果原链表的后继结点为null,那么也需要将全局头节点引用指向这个新的结点if (l == null)first = newNode;//(5)不为null,因为是双向链表,创建新节点的时候只是将newNode的prev设置为原last结点。这里就需要将原last//结点的后继结点设置为newNodeelsel.next = newNode;//(6)更新当前链表中的size个数size++;//(7)这里是fast-fail机制使用的参数modCount++;}
我们通过一个示例图来简单模拟这个过程
- 当链表初始时为空的时候,我么调用add方法添加一个新的结点
- 链表不为空,此时调用add方法在链表尾部添加结点的时候
(2)linkFirst方法
该方法是一个private方法,通过addFirst方法调用暴露给使用者。
public void addFirst(E e) {linkFirst(e);}
我们还是主要看看linkFirst方法的实现逻辑
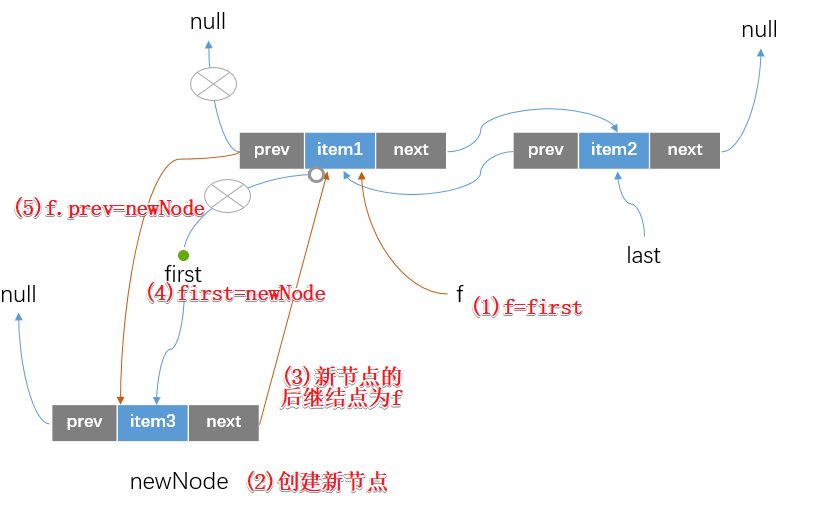
private void linkFirst(E e) {//(1)获取全局头节点final Node<E> f = first;//(2)创建一个新节点,其前驱结点为null,后继结点为当前的全局首结点final Node<E> newNode = new Node<>(null, e, f);//(3)更新全局首结点引用first = newNode;//(4)如果首结点为null,last结点指向新建的结点if (f == null)last = newNode;//(5)不为null,原头节点的前驱结点为newNodeelsef.prev = newNode;size++;modCount++;}
上面的逻辑也比较简单,就是将新添加的结点设置为头节点,然后更新链表中结点之间的指向,我们通过下面这个图简单理解一下(链表初始为null就不做演示了,和上面图示的差不多,这里假设已经存在结点)
(3)linkBefore方法
public void add(int index, E element) {//检查index的合法性:大于等于0小于等于size,不合法会抛出异常checkPositionIndex(index);//index等于size,就在尾部插入新节点,linkLast方法上面说到过if (index == size)linkLast(element);//否则就在指定index处插入结点,先找到index处的结点(调用的是node(index方法))elselinkBefore(element, node(index));}private void checkPositionIndex(int index) {if (!isPositionIndex(index))throw new IndexOutOfBoundsException(outOfBoundsMsg(index));}private boolean isPositionIndex(int index) {return index >= 0 && index <= size;}
add(index,element)方法中主要的逻辑还是linkBefore,我们下面看看这个方法,在此之前调用的是node(index)方法,找到index处的结点
Node<E> node(int index) {//index < size/2 (index在链表的前半部分)if (index < (size >> 1)) {//使用全局头节点去查找(遍历链表)Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {//index > size / 2 (index在链表的后半部分)Node<E> x = last;//使用全局尾节点向前查找for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
node方法实现利用双向链表以及记录了链表总长度的这两个特点,分为前后两部分去遍历查询jindex位置处的结点。查找这个结点后,就会作为参数调用linkBefore方法,如下所示
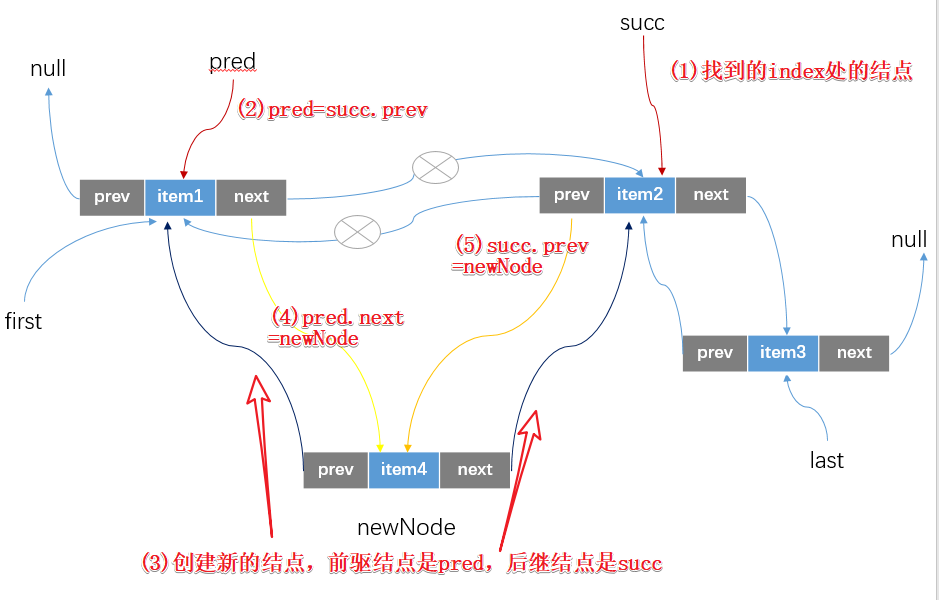
void linkBefore(E e, Node<E> succ) {//succ != null;succ就是指定位置处的结点//传入的结点element=succfinal Node<E> pred = succ.prev;//创建新的结点//前驱结点是传入的结点的前驱结点//后继结点是传入的结点final Node<E> newNode = new Node<>(pred, e, succ);//更新index处结点的前驱结点引用succ.prev = newNode;//index处结点的前驱结点为null,那么就相当于在头部插入结点,并且更新firstif (pred == null)first = newNode;//不为null,那么它的后继结点就是新的结点elsepred.next = newNode;size++;modCount++;}
这个方法的逻辑也比较简单,就是在succ和succ.prev两个结点之间插入一个新的结点,我们通过简单的图示理解这个过程
删除
作为双端队列,删除元素也有两种方式队列首删除元素、队列尾删除元素;作为List,又要支持中间删除元素,所以删除元素一个有三个方法。
(1)unlinkFirst方法
下面是调用unlinkFirst方法的两个public方法(Deque接口的方法实现),主要区别就是removeFirst方法执行时候,first为null的时候会抛出异常,而pollFirst返回null。
// remove的时候如果没有元素抛出异常public E removeFirst() {final Node<E> f = first;if (f == null)throw new NoSuchElementException();return unlinkFirst(f);}// poll的时候如果没有元素返回nullpublic E pollFirst() {final Node<E> f = first;return (f == null) ? null : unlinkFirst(f);}
主要还是看unlinkFirst这个方法的实现
private E unlinkFirst(Node<E> f) {// assert f == first && f != null;//获取头结点的元素值final E element = f.item;//获取头结点的后继结点final Node<E> next = f.next;//删除头节点中存放的元素item和后继结点,GCf.item = null;f.next = null; // help GC//更新头节点引用(原头节点的后继结点)first = next;//链表中只有一个结点,那么尾节点也是null了if (next == null)last = null;//将新的头节点的前驱结点设置为nullelsenext.prev = null;//更新size和modCountsize--;modCount++;//返回原头节点的值return element;}
(2)unlinkLast方法
下面是调用unlinkLast方法的两个public方法(Deque接口的方法实现),主要区别就是removeLast方法执行时候,first为null的时候会抛出异常,而pollLast返回null。
// remove的时候如果没有元素抛出异常public E removeLast() {final Node<E> l = last;if (l == null)throw new NoSuchElementException();return unlinkLast(l);}// poll的时候如果没有元素返回nullpublic E pollLast() {final Node<E> l = last;return (l == null) ? null : unlinkLast(l);}
下面是unlinkLast方法的实现
// 删除尾节点private E unlinkLast(Node<E> l) {// 尾节点的元素值final E element = l.item;// 尾节点的前置指针final Node<E> prev = l.prev;// 清空尾节点的内容,协助GCl.item = null;l.prev = null; // help GC// 让前置节点成为新的尾节点last = prev;// 如果只有一个元素,删除了把first置为空// 否则把前置节点的next置为空if (prev == null)first = null;elseprev.next = null;// 更新size和modCountsize--;modCount++;// 返回删除的元素return element;}
(4)unlink方法
// 删除中间节点public E remove(int index) {// 检查是否越界checkElementIndex(index);// 删除指定index位置的节点return unlink(node(index));}
// 删除指定节点xE unlink(Node<E> x) {// x的元素值final E element = x.item;// x的前置节点final Node<E> next = x.next;// x的后置节点final Node<E> prev = x.prev;// 如果前置节点为空// 说明是首节点,让first指向x的后置节点// 否则修改前置节点的next为x的后置节点if (prev == null) {first = next;} else {prev.next = next;x.prev = null;}// 如果后置节点为空// 说明是尾节点,让last指向x的前置节点// 否则修改后置节点的prev为x的前置节点if (next == null) {last = prev;} else {next.prev = prev;x.next = null;}// 清空x的元素值,协助GCx.item = null;// 元素个数减1size--;// 修改次数加1modCount++;// 返回删除的元素return element;}
查找
LinkedList 底层基于链表结构,无法向 ArrayList 那样随机访问指定位置的元素。LinkedList 查找过程要稍麻烦一些,需要从链表头结点(或尾节点)向后查找,时间复杂度为 O(N)。相关源码如下:
public E get(int index) {checkElementIndex(index); //还是先检验index的合法性,这里上面已经说过//调用node方法遍历查询index处的结点,然后返回结点存放的值item,node方法上面已经说过return node(index).item;}
遍历
链表的遍历过程也很简单,和上面查找过程类似,我们从头节点往后遍历就行了。但对于 LinkedList 的遍历还是需要注意一些,不然可能会导致代码效率低下。通常情况下,我们会使用 foreach 遍历 LinkedList,而 foreach 最终转换成迭代器形式。所以分析 LinkedList 的遍历的核心就是它的迭代器实现,相关代码如下:
public ListIterator<E> listIterator(int index) {checkPositionIndex(index);return new ListItr(index);}private class ListItr implements ListIterator<E> {private Node<E> lastReturned;private Node<E> next;private int nextIndex;private int expectedModCount = modCount;/** 构造方法将 next 引用指向指定位置的节点 */ListItr(int index) {// assert isPositionIndex(index);next = (index == size) ? null : node(index);nextIndex = index;}public boolean hasNext() {return nextIndex < size;}public E next() {checkForComodification();if (!hasNext())throw new NoSuchElementException();lastReturned = next;next = next.next;nextIndex++;return lastReturned.item;}//...other method}
这里主要说下遍历 LinkedList 需要注意的一个点。LinkedList 不擅长随机位置访问,如果大家用随机访问的方式遍历 LinkedList,效率会很差。比如下面的代码:
List<Integet> list = new LinkedList<>();list.add(1)list.add(2)......for (int i = 0; i < list.size(); i++) {Integet item = list.get(i);// do something}
当链表中存储的元素很多时,上面的遍历方式对于效率肯定是非常低的。原因在于,通过上面的方式每获取一个元素(调用get(i)方法,上面说到了这个方法的实现),LinkedList 都需要从头节点(或尾节点)进行遍历(node()方法的实现),效率低,上面的遍历方式在大数据量情况下,效率很差。在日常使用中应该尽量避免这种用法。
总结
最后总结一下面试常问的ArrayList和LinkedList的区别,关于ArrayList请参考我上一篇ArrayList源码分析。
ArrayList是基于动态数组实现的,LinkedList是基于双向链表实现的;对于随机访问来说,
ArrayList(数组下标访问)要优于LinkedList(遍历链表访问);不考虑直接在尾部添加数据的话,
ArrayList按照指定的index添加/删除数据是通过复制数组实现。LinkedList通过寻址改变节点指向实现;所以添加元素的话LinkedList(改变结点的next和prev指向即可)要优于ArrayList(移动数组元素)。LinkedList在数据存储上不存在浪费空间的情况。ArrayList动态扩容会导致有一部分空间是浪费的。
LinkedList源码分析(jdk1.8)的更多相关文章
- ArrayList源码分析--jdk1.8
ArrayList概述 1. ArrayList是可以动态扩容和动态删除冗余容量的索引序列,基于数组实现的集合. 2. ArrayList支持随机访问.克隆.序列化,元素有序且可以重复. 3. ...
- ReentrantLock源码分析--jdk1.8
JDK1.8 ArrayList源码分析--jdk1.8LinkedList源码分析--jdk1.8HashMap源码分析--jdk1.8AQS源码分析--jdk1.8ReentrantLock源码分 ...
- Java入门系列之集合LinkedList源码分析(九)
前言 上一节我们手写实现了单链表和双链表,本节我们来看看源码是如何实现的并且对比手动实现有哪些可优化的地方. LinkedList源码分析 通过上一节我们对双链表原理的讲解,同时我们对照如下图也可知道 ...
- ArrayList 和 LinkedList 源码分析
List 表示的就是线性表,是具有相同特性的数据元素的有限序列.它主要有两种存储结构,顺序存储和链式存储,分别对应着 ArrayList 和 LinkedList 的实现,接下来以 jdk7 代码为例 ...
- Java集合之LinkedList源码分析
概述 LinkedLIst和ArrayLIst一样, 都实现了List接口, 但其内部的数据结构不同, LinkedList是基于链表实现的(从名字也能看出来), 随机访问效率要比ArrayList差 ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- Java集合基于JDK1.8的LinkedList源码分析
上篇我们分析了ArrayList的底层实现,知道了ArrayList底层是基于数组实现的,因此具有查找修改快而插入删除慢的特点.本篇介绍的LinkedList是List接口的另一种实现,它的底层是基于 ...
- List中的ArrayList和LinkedList源码分析
List是在面试中经常会问的一点,在我们面试中知道的仅仅是List是单列集合Collection下的一个实现类, List的实现接口又有几个,一个是ArrayList,还有一个是LinkedLis ...
- LinkedList 源码分析(JDK 1.8)
1.概述 LinkedList 是 Java 集合框架中一个重要的实现,其底层采用的双向链表结构.和 ArrayList 一样,LinkedList 也支持空值和重复值.由于 LinkedList 基 ...
随机推荐
- Ember报错
错误是ember-data的版本不对 解决办法是: npm install --save ember-data@2.14.2 //bing.com中去查资料,应有尽有
- 使用事件注册器进行swoole代码封装
在使用swoole的时候,事件回调很难维护与编写,写起来很乱.特别在封装一些代码的时候,使用这种注册,先注册用户自己定义的,然后注册些默认的事件函数. Server.php class Server ...
- css之vw布局
vw,vh是视口单位,是相对视口单位,与百分百布局不一样的是,百分百是相对于父及元素,而vw布局是相对与窗口. 而rem布局是要与js一起配合 // 以iphone6设计稿 @function px2 ...
- Python 爬虫从入门到进阶之路(十一)
之前的文章我们介绍了一下 Xpath 模块,接下来我们就利用 Xpath 模块爬取<糗事百科>的糗事. 之前我们已经利用 re 模块爬取过一次糗百,我们只需要在其基础上做一些修改就可以了, ...
- sql-实现select取行号、分组后在分组内排序、每个分组中的前n条数据
表结构设计: 实现select取行号 sql局部变量的2种方式 set @name='cm3333f'; select @id:=1; 区别:set 可以用=号赋值,而select 不行,必须使用:= ...
- 深入学习Spring框架(一)- 入门
1.Spring是什么? Spring是一个JavaEE轻量级的一站式开发框架. JavaEE: 就是用于开发B/S的程序.(企业级) 轻量级:使用最少代码启动框架,然后根据你的需求选择,选择你喜欢的 ...
- C#中的委托和事件(下篇)
上次以鸿门宴的例子写了一篇博文,旨在帮助C#初学者迈过委托和事件这道坎,能够用最快的速度掌握如何使用它们.如果觉得意犹未尽,或者仍然不知如何在实际应用中使用它们,那么,这篇窗体篇,将在Winform场 ...
- 解决thinkphp在开发环境下文件模块找不到的问题
win10系统下,phpstudy开发环境下小问题描述: 找不到public公共模块. Not Found The requested URL /public/admin/login.html was ...
- Django rest framework(1)----认证
目录 Django组件库之(一) APIView源码 Django restframework (1) ----认证 Django rest framework(2)----权限 Django ...
- python实现DFA模拟程序(附java实现代码)
DFA(确定的有穷自动机) 一个确定的有穷自动机M是一个五元组: M=(K,∑,f,S,Z) K是一个有穷集,它的每个元素称为一个状态. ∑是一个有穷字母表,它的每一个元素称为一个输入符号,所以也陈∑ ...