darknet是如何对数据集做resize的?
在准备数据集时,darknet并不要求我们预先对图片resize到固定的size. darknet自动帮我们做了图像的resize.
darknet训练前处理
本文所指的darknet版本:https://github.com/AlexeyAB/darknet
./darknet detector train data/trafficlights.data yolov3-tiny_trafficlights.cfg yolov3-tiny.conv.15
main函数位于darknet.c
训练时的入口函数为detector.c里
void train_detector(char *datacfg, char *cfgfile, char *weightfile, int *gpus, int ngpus, int clear, int dont_show, int calc_map, int mjpeg_port, int show_imgs)
{
load_args args = { 0 };
args.type = DETECTION_DATA;
args.letter_box = net.letter_box;
load_thread = load_data(args);
loss = train_network(net, train);
}
函数太长,只贴了几句关键的.注意args.type = DETECTION_DATA;
data.c中
void *load_thread(void *ptr)
{
//srand(time(0));
//printf("Loading data: %d\n", random_gen());
load_args a = *(struct load_args*)ptr;
if(a.exposure == 0) a.exposure = 1;
if(a.saturation == 0) a.saturation = 1;
if(a.aspect == 0) a.aspect = 1;
if (a.type == OLD_CLASSIFICATION_DATA){
*a.d = load_data_old(a.paths, a.n, a.m, a.labels, a.classes, a.w, a.h);
} else if (a.type == CLASSIFICATION_DATA){
*a.d = load_data_augment(a.paths, a.n, a.m, a.labels, a.classes, a.hierarchy, a.flip, a.min, a.max, a.size, a.angle, a.aspect, a.hue, a.saturation, a.exposure);
} else if (a.type == SUPER_DATA){
*a.d = load_data_super(a.paths, a.n, a.m, a.w, a.h, a.scale);
} else if (a.type == WRITING_DATA){
*a.d = load_data_writing(a.paths, a.n, a.m, a.w, a.h, a.out_w, a.out_h);
} else if (a.type == REGION_DATA){
*a.d = load_data_region(a.n, a.paths, a.m, a.w, a.h, a.num_boxes, a.classes, a.jitter, a.hue, a.saturation, a.exposure);
} else if (a.type == DETECTION_DATA){
*a.d = load_data_detection(a.n, a.paths, a.m, a.w, a.h, a.c, a.num_boxes, a.classes, a.flip, a.blur, a.mixup, a.jitter,
a.hue, a.saturation, a.exposure, a.mini_batch, a.track, a.augment_speed, a.letter_box, a.show_imgs);
} else if (a.type == SWAG_DATA){
*a.d = load_data_swag(a.paths, a.n, a.classes, a.jitter);
} else if (a.type == COMPARE_DATA){
*a.d = load_data_compare(a.n, a.paths, a.m, a.classes, a.w, a.h);
} else if (a.type == IMAGE_DATA){
*(a.im) = load_image(a.path, 0, 0, a.c);
*(a.resized) = resize_image(*(a.im), a.w, a.h);
}else if (a.type == LETTERBOX_DATA) {
*(a.im) = load_image(a.path, 0, 0, a.c);
*(a.resized) = letterbox_image(*(a.im), a.w, a.h);
} else if (a.type == TAG_DATA){
*a.d = load_data_tag(a.paths, a.n, a.m, a.classes, a.flip, a.min, a.max, a.size, a.angle, a.aspect, a.hue, a.saturation, a.exposure);
}
free(ptr);
return 0;
}
根据a.type不同,有不同的加载逻辑.在训练时,args.type = DETECTION_DATA,接着去看load_data_detection().
load_data_detection()有两套实现,用宏#ifdef OPENCV区别开来.我们看opencv版本
load_data_detection()
{
src = load_image_mat_cv(filename, flag);
image ai = image_data_augmentation(src, w, h, pleft, ptop, swidth, sheight, flip, jitter, dhue, dsat, dexp);
}
注意load_image_mat_cv()中imread读入的是bgr顺序的,用cv::cvtColor做了bgr-->rgb的转换.
if (mat.channels() == 3) cv::cvtColor(mat, mat, cv::COLOR_RGB2BGR);
这里有个让人困惑的地方,为什么是cv::COLOR_RGB2BGR而不是cv::COLOR_BGR2RGB,实际上这两个enum值是一样的,都是4.
见https://docs.opencv.org/3.1.0/d7/d1b/group__imgproc__misc.html
https://github.com/pjreddie/darknet/issues/427
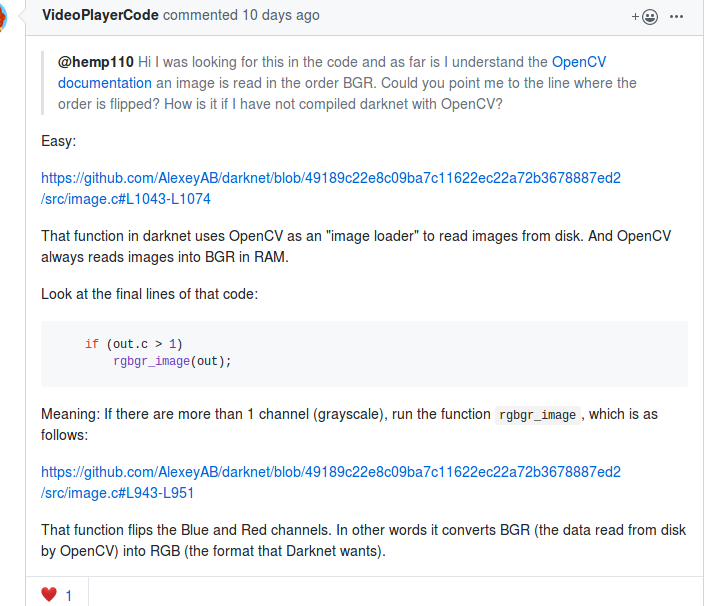
所以在做推理的时候,也应该转换到rgb的顺序.
image_data_argmentation()的主要逻辑
cv::Mat cropped(src_rect.size(), img.type());
//cropped.setTo(cv::Scalar::all(0));
cropped.setTo(cv::mean(img));
img(new_src_rect).copyTo(cropped(dst_rect));
// resize
cv::resize(cropped, sized, cv::Size(w, h), 0, 0, cv::INTER_LINEAR);
其实主要就是cv::resize. 这里cropped的img是在原图上随机截取出来的一块区域(当然是有范围的).
在load_data_detection()中有这样一段逻辑,生成pleft,pright,ptop,pbot. 这些参数被传递给image_data_argmentation(),用以截取出cropped image.
int oh = get_height_mat(src);
int ow = get_width_mat(src);
int dw = (ow*jitter);
int dh = (oh*jitter);
if(!augmentation_calculated || !track)
{
augmentation_calculated = 1;
r1 = random_float();
r2 = random_float();
r3 = random_float();
r4 = random_float();
dhue = rand_uniform_strong(-hue, hue);
dsat = rand_scale(saturation);
dexp = rand_scale(exposure);
flip = use_flip ? random_gen() % 2 : 0;
}
int pleft = rand_precalc_random(-dw, dw, r1);
int pright = rand_precalc_random(-dw, dw, r2);
int ptop = rand_precalc_random(-dh, dh, r3);
int pbot = rand_precalc_random(-dh, dh, r4);
int swidth = ow - pleft - pright;
int sheight = oh - ptop - pbot;
float sx = (float)swidth / ow;
float sy = (float)sheight / oh;
float dx = ((float)pleft/ow)/sx;
float dy = ((float)ptop /oh)/sy;
这么做的目的是,参考作者AlexeyAB大神的回复:
https://github.com/AlexeyAB/darknet/issues/3703
Your test images will not be the same as training images, so you should change training images as many times as possible. So maybe one of the modified training images of the object coincides with the test image.
这里,我此前一直有个错误的理解,在train和test时对image的preprocess应该是完全一致的.大神的回复意思是,并非如此,在train的时候应该尽可能多地使训练图片产生一些变化,因为测试图片不可能与训练图片是完全一致的,这样的话,才更有可能使测试图片与某个随机变化后的训练图片吻合.
但是之前,我在issue里有看到有人训练出来的模型效果并不好,改变了image的preprocess以后,效果就好了.这一点还有待研究.
原始的darknet里图像的preprocess用的是letterbox_image(),AlexeyAB的版本里用的是resize.据作者说这一改变使得对小目标的检测效果更好.
参考https://github.com/AlexeyAB/darknet/issues/1907 https://github.com/AlexeyAB/darknet/issues/232#issuecomment-336955485
resize()并不会保持宽高比,letterbox_image()会保持宽高比.作者认为如果你的dataset的train和test中图像分辨率一致的话,是没有必要保持宽高比的.
darknet 推导前处理
detector.c中
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh,
float hier_thresh, int dont_show, int ext_output, int save_labels, char *outfile)
{
image im = load_image(input, 0, 0, net.c);
image sized = resize_image(im, net.w, net.h);
}
这里的resize_image是用C实现的,和cv::resize功能相同
/update 20190821***************/
darknet数据预处理
- 数据加载入口函数void *load_thread(void *ptr)
根据args.type不同有不同加载逻辑 - 喂给模型的输入并不是你训练图片的原始矩阵,darknet自己会做一些数据增强的操作,比如调整对比度,色相,饱和度,对图片旋转角度,翻转图像等等.
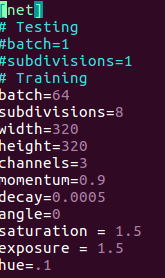
这些是配置在配置文件中的.
具体做了哪些数据增强,要自己看源代码,args.type不同,加载逻辑也略有差异
以./darknet detector train ....,即做目标检测的训练为例的话,对色相/饱和度/对比度的调整代码如下,位于image.c中

基本上前处理的代码都位于data.c,image.c中,image.c里是对图像矩阵的具体操作函数,data.c里是一些调用这些函数的控制流程.
当训练图片特别小时,不同的preprocess对喂给模型的代表图片的矩阵的影响就很大.所以最好先手动resize到模型的input size.
darknet是如何对数据集做resize的?的更多相关文章
- 深度学习入门教程UFLDL学习实验笔记二:使用向量化对MNIST数据集做稀疏自编码
今天来做UFLDL的第二个实验,向量化.我们都知道,在matlab里面基本上如果使用for循环,程序是会慢的一逼的(可以说基本就运行不下去)所以在这呢,我们需要对程序进行向量化的处理,所谓向量化就是将 ...
- 深度学习voc数据集图片resize
本人新写的3个pyhton脚本. (1)单张图片的resize: # coding = utf-8 import Image def convert(width,height): im = Image ...
- darknet YOLOv2安装及数据集训练
一. YOLOv2安装使用 1. darknet YOLOv2安装 git clone https://github.com/pjreddie/darknetcd darknetmake或到网址上下载 ...
- 对数据集做标准化处理的几种方法——基于R语言
数据集——iris(R语言自带鸢尾花包) 一.scale函数 scale函数默认的是对制定数据做均值为0,标准差为1的标准化.它的两个参数center和scale: 1)center和scale默认为 ...
- 4.keras实现-->生成式深度学习之用变分自编码器VAE生成图像(mnist数据集和名人头像数据集)
变分自编码器(VAE,variatinal autoencoder) VS 生成式对抗网络(GAN,generative adversarial network) 两者不仅适用于图像,还可以 ...
- 机器学习 — 从mnist数据集谈起
做了一些简单机器学习任务后,发现必须要对数据集有足够的了解才能动手做一些事,这是无法避免的,否则可能连在干嘛都不知道,而一些官方例程并不会对数据集做过多解释,你甚至连它长什么样都不知道... 以skl ...
- 基于pytorch实现Resnet对本地数据集的训练
本文是使用pycharm下的pytorch框架编写一个训练本地数据集的Resnet深度学习模型,其一共有两百行代码左右,分成mian.py.network.py.dataset.py以及train.p ...
- 最近用django做了个在线数据分析小网站
用最近做的理赔申请人测试数据集做了个在线分析小网站. 数据结构,算法等设置都保存在json文件里.将来对这个小破站扩充算法,只修改一下json文件就行. 当然,结果分析还是要加代码的.页面代码不贴了, ...
- ArcGIS 网络分析[8.3] 设置IDENetworkDataset的属性及INetworkDataset的对比/创建网络数据集
创建网络数据集就得有各种数据和参数,这篇文章很长,慎入. 网络分析依赖于网络数据集的质量,这句话就在这里得到了验证:复杂.精确定义. 本节目录如下: 1. INetworkDataset与IDENet ...
随机推荐
- 对于BIO/NIO/AIO,你还只停留在烧开水的水平吗?
1.发发牢骚 相信大家在网上看过不少讲解 BIO/NIO/AIO 的文章,文章中举起栗子来更是夯吃夯吃一大堆,我是越看越觉得 What are you 你讲啥嘞? 本文将针对 BIO/NIO/AIO ...
- 使用docker运行GitLab
从docker镜像拉取代码,docker pull gitlab/gitlab-ce:latest. 创建/srv/gitlab目录sudo mkdir /srv/gitlab 启动GitLab CE ...
- 并发编程-concurrent指南-原子操作类-AtomicLong
可以用原子方式更新的 long 值.有关原子变量属性的描述,请参阅 java.util.concurrent.atomic 包规范.AtomicLong 可用在应用程序中(如以原子方式增加的序列号), ...
- Abnormal build process termination IDEA启动报错
报错如下: Error:Abnormal build process termination: "C:Program FilesJavajdk1.11.0_1injava" -Xm ...
- 如何编写无须人工干预的shell脚本
在使用基本的一些shell命令时,机器需要与人进行互动来确定命令的执行.比如 cp test.txt boo/test.txt,会询问是否覆盖?ssh远程登陆时,需要输入人工密码后,才可以继续执行ss ...
- 深度总结eMMC发展史 ICMAX值得更好地期待
随着大数据.云计算.物联网等产业的发展,信息存储安全一旦受到威胁,将危害到政军.石油.化工.核能.金融等所有行业的安全.存储芯片又被称为电子产品的“粮食”,占产品成本的二成左右,尽管中国是全球最大的手 ...
- CAD2014学习笔记-图层图案图块
基于 虎课网huke88.com CAD教程 对象特性 选择对象点击特性栏/或右键点击特性 颜色:color 图层 线型:线的类型,如点状线.虚线等,若不改变则默认新建的线为该类型 线型比例:不同类型 ...
- MyBatis简单使用方式总结
MyBatis简单使用方式总结 三个部分来理解: 1.对MyBatis的配置部分 2.实体类与映射文件部分 3.使用部分 对MyBatis的配置部分: 1.配置用log4J显式日志 2.导入包的别名 ...
- golang开发:类库篇(四)配置文件解析器goconfig的使用
为什么要使用goconfig解析配置文件 目前各语言框架对配置文件书写基本都差不多,基本都是首先配置一些基础变量,基本变量里面有环境的配置,然后通过环境变量去获取该环境下的变量.例如,生产环境跟测试环 ...
- weblogic10.3.6重置/修改控制台账号密码
weblogic部署服务后由于交接过程中文档不完整导致有一个域的控制台账号密码遗失, 在此整理记录一下重置控制台账号密码的过程: 注:%DOMAIN_HOME%:指WebLogic Server 域( ...