论文解读2——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
背景
用ConvNet方法解决图像分类、检测问题成为热潮,但这些方法都需要先把图片resize到固定的w*h,再丢进网络里,图片经过resize可能会丢失一些信息。论文作者发明了SPP pooling(空间金字塔池化)层,让网络可以接受任意size的输入。
方法
首先思考一个问题,为什么ConvNet需要一个固定size的图片作为输入,我们知道,Conv层只需要channel固定(彩色图片3,灰度图1),但可以接受任意w*h的输入,当然输出的w*h也会跟着变化;然而,后面的FC层却需要固定长度的vector作为输入,图片size变化->conv层输出的size变化->FC层输入的vector长度变化,这就产生了错误。
怎么解决这个问题呢?作者给出的方法是在最后一层Conv层后面加上一个SPP pooling层,SPP pooling层可以将接收到的不同size的输入转换成为固定的输出,保证FC层的输入长度固定。
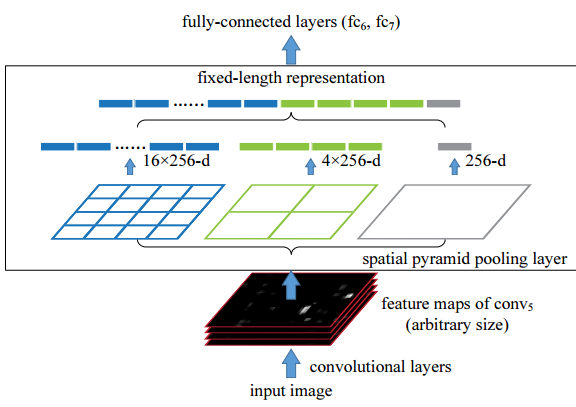
如图,SPP pooling层的原理很简单,例子如下:给定一个w*h的特征图,把其分别分成4*4、2*2、1*1的bin,在每个bin上面作pooling操作(文中使用的是max pooling),最后能得到16*256-d(256-d是最后一个conv层的输出通道数),4*256-d、1*256-d的feature vector,最后连接在一起,得到的就是21*256-d的feature vector。
可以看到,不管一开始的w和h取值多少,最后都能得到固定长度的feature vector作为FC层的输入,这样,ConvNet就能接受不同size的图片作为输入了。
总结
论文作者通过在FC层前面加上一个SPP pooling层,有效解决了ConvNet必须接受固定size的图片。
论文解读2——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition的更多相关文章
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- SPP Net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)论文理解
论文地址:https://arxiv.org/pdf/1406.4729.pdf 论文翻译请移步:http://www.dengfanxin.cn/?p=403 一.背景: 传统的CNN要求输入图像尺 ...
- SPP NET (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
1. https://www.cnblogs.com/gongxijun/p/7172134.html (SPP 原理) 2.https://www.cnblogs.com/chaofn/p/9305 ...
- 目标检测(二)SSPnet--Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognotion
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun 以前的CNNs都要求输入图像尺寸固定,这种硬性要求也许会降低识别任意尺寸图像的准确度. ...
- 论文笔记:(2019CVPR)PointConv: Deep Convolutional Networks on 3D Point Clouds
目录 摘要 一.前言 1.1直接获取3D数据的传感器 1.2为什么用3D数据 1.3目前遇到的困难 1.4现有的解决方法及存在的问题 二.本文idea 2.1 idea来源 2.2 初始思路 2.3 ...
随机推荐
- 彻底透析SpringBoot jar可执行原理
文章篇幅较长,但是包含了SpringBoot 可执行jar包从头到尾的原理,请读者耐心观看.同时文章是基于SpringBoot-2.1.3进行分析.涉及的知识点主要包括Maven的生命周期以及自定 ...
- 缓存实践Cache Aside Pattern
Cache Aside Pattern旁路缓存,是对缓存应用的一个总结,包括读数据方案和写数据方案. 读数据方案 先读cache,如果命中则返回 如果miss则读db 将db的数据存入缓存 写数据方案 ...
- EPPLUS 实现excel报表数据及公式填充
年后工作第一天,根据客户要求修善EPPLUS报表. Epplus: Epplus是一个使用Open Office XML(Xlsx)文件格式,能读写Excel 2007/2010文件的开源组件 好处很 ...
- Method has too many Body parameters openfeign
feign 调用问题,最新版本的feign和旧版本的稍微有一些不一样,具体如下(eureka 作为服务发现与注册 ) 依赖: compile('io.github.openfeign:feign-ja ...
- Hadoop值Partition分区
分区操作 为什么要分区? 要求将统计结果按照条件输出到不同文件中(分区).比如:将统计结果按 照手机归属地不同省份输出到不同文件中(分区) 默认 partition 分区 /** 源码中:numRed ...
- Python学习6——再谈抽象(面对对象编程)
1.对象魔法 在面对对象编程中,术语对象大致意味着一系列数据(属性)以及一套访问和操作这些数据的方法. 使用对象而非全局变量以及函数的原因有多个,而最重要的好处不过以下几点: 多态:可对不同类型的对象 ...
- 备战金九银十,Java研发面试题(Spring、MySQL、JVM、Mybatis、Redis、Tomcat)[带答案],刷起来!
八月在即,马上就是"金九银十",又是跳槽招聘季.咱们这行公认涨薪不如跳槽加的快.但不建议频繁跳槽,还是要学会融合团队,抓住每个机会提升技能. 苏先生在这里给大家整理了一套各大互联网 ...
- Java后台处理框架之struts2学习总结
Java后台处理框架之struts2学习总结 最近我在网上了解到,在实际的开发项目中struts2的使用率在不断降低,取而代之的是springMVC.可能有很多的朋友看到这里就会说,那还不如不学str ...
- [填坑] ubuntu检测不到外接显示器
笔记本是win10+ubuntu18双系统,今天ubuntu(开启nivida独显状态)突然无法连外接屏幕,但切换win10就可以显示. 贴吧找到的简单解决方法,不需要重装驱动,记录分享在这里: su ...
- js数组排序 多条件
按照[次数]和[时间]排序,选择次数最多的排在前面,同样次数的情况下时间较新排在前面. 原始数据: var arr= [ {name:'qqq', num:2,time:'2015-06-08 13: ...