HashMap这些问题你知道吗?
HashMap是Java面试中的常考点之一,而且其<Key,Value>结构也是开发中常常用到的结构之一。或许你使用过HashMap,但是你知道下面这些问题吗?
- HashMap的
底层结构是什么?
如果你能说出是数组+链表,那么你知道1.8版本之后引入的红黑树吗?
- 说道
红黑树,你知道它的结构吗?
你知道红黑树,那么你知道它是结合平衡二叉树和2-3树优点的产物吗?亦或者你知道这两种树的结构吗?
- 既然你知道树的
索引结构,那么你了解过各种数据库的索引结构吗?
你或许知道类似于MySql使用的B+树结构,那么你知道为什么要使用这种结构吗?而且问题反绕回来,为什么HashMap使用了红黑树而不是B+树?为什么数据库中使用的是B+树?
HashMap的扩容机制了解吗?另外你知道为什么HashMap容量要保持2的N次方吗?HashMap不是线程安全,那么你知道主要发生线程不安全的情况是什么吗?
那么从这里开始,让我们过一遍这些问题。
索引
- HashMap的底层结构是什么?
- 从2-3树开始看红黑树
- 2-3树
- 红黑树
- 你知道各类数据库的索引结构吗?
- 数据库为什么选择B+树索引?HashMap为什么选择红黑树索引?
- HashMap的扩容机制了解吗?另外你知道为什么HashMap容量要保持2的N次方吗?
- HashMap线程不安全的主要情况是什么?
- 小彩蛋
HashMap的底层结构是什么?
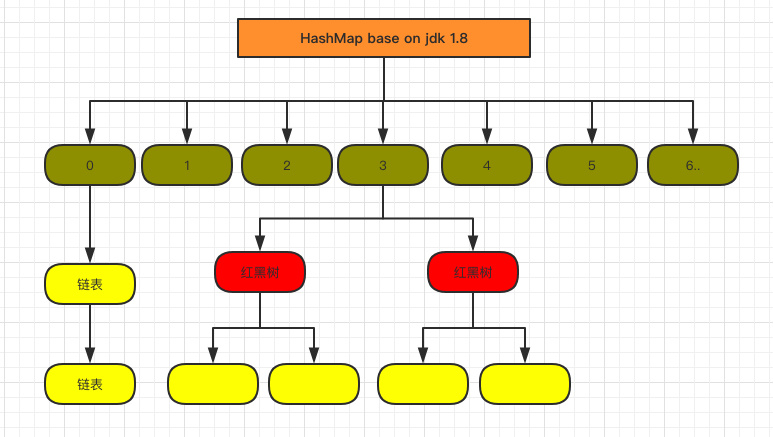
这个问题需要从JDK的版本来说,早在JDK1.7及其引入HashMap之前,HashMap使用的结构是数组+链表,使用这个结构的原因主要与Hash算法有关。HashMap的目的是为了让数据访问能够达到复杂度只有O(1)的级别,它是<Key,Value>的结构,在我们存储时,将key值使用Hash算法获得一个hashcode,这个hashcode就是value在HashMap的数组中的下标位置,当我们要查询某一个key对应的value时,只需要经过一次Hash就可以得到下标位置,而不用经过繁琐的遍历。
因为不同对象经过Hash之后可能得到同样的hashcode,所以这里使用了链表结构,当我们命中同一个下标时就需要通过链表来扩充了。
如果一个Hash函数设计的不太精妙,或者插入的数据本身有问题,那么就会出现一个hashcode多次命中的情况,这种情况下我们得到数组下标之后,还需要去遍历这个链表来得到具体的value。在这种情况下会影响到HashMap的访问速度。
所以在JDK1.8时,为了提高效率引入了红黑树结构,不过红黑树是在链表长度达到8(默认值)时,并且table的长度不小于64(否则扩容一次)时,才会将这条链表转换为红黑树。
假设hash冲突非常严重,一个数组后面接了很长的链表,此时重新的时间复杂度就是 O(n)。如果是红黑树,时间复杂度就是 O(logn)。
在开始下一个问题之前,在这里贴出一段HashMap的源码,这里有几个关键的地方需要了解。
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
DEFAULT_INITIAL_CAPACITY是指默认初始容量,这是我们直接new HashMap()之后给出的数组的大小。
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
DEFAULT_LOAD_FACTOR叫做负载因子,负载因子*当前容器的大小决定了容器的扩容时机,比如当前容量是16,负载因子是0.75,那么负载因子*当前容器的大小 = 16*0.75 = 12,当使用超过12时,就会进行一次容器扩容。
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
MAXIMUM_CAPACITY是最大扩容容量。
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
TREEIFY_THRESHOLD是链表长度达到此值时转换为红黑树的值。
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
UNTREEIFY_THRESHOLD是当执行resize操作时,红黑树中节点少于此值时退化为链表。
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
MIN_TREEIFY_CAPACITY是在转变成树之前,还会有一次判断,只有键值对数量大于64才会发生转换。这是为了避免在哈希表建立初期,多个键值对恰好被放入了同一个链表中而导致不必要的转化。
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
table就是所谓的数组。
从2-3树开始看红黑树
2-3树
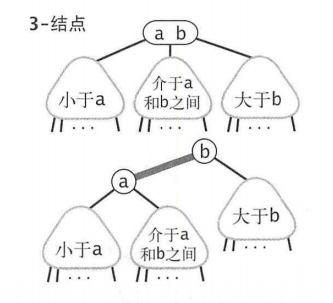
你应该知道二叉查找树,我们可以将二叉树的一个节点多保存一个键,并且称它为2-节点。多添加两个键,称它为3-节点。
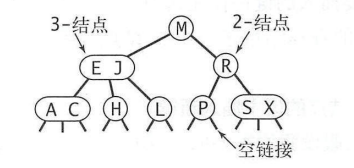
2-结点,含有一个键(及其对应的值)和两条链接,左链接指向的2-3树中的键都小于该结点,右链接指向的2-3树中的键都大于该结点。
3-结点,含有两个键(及其对应的值)和三条链接,左链接指向的2-3树中的键都小于该结点,中链接指向的2-3树中的键都位于该结点的两个键之间,右链接指向的2-3树中的键都大于该结点。
指向一棵空树的链接称为空链接。
一棵完美平衡的2-3查找树中的所有空链接到根结点的距离都应该是相同的。
那么问题来了,2-3树有什么意义?
不知道你有没有发现,二叉查找树存在的缺点,虽然它查找一个节点很快,但是它有着很大的缺点,就是在插入新的节点时,需要对整个二叉树进行调整。
而二叉查找树不一样,当我们要插入新的节点时,如果查找结束于一个2-节点,可以将一个2-节点转换为3-节点,从而避免了平衡操作。

如果查找结束于一个3-节点,可以将一个3-节点转换为3个2-节点。
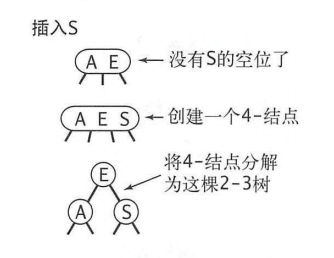
如果要向一个父结点为2-结点的3-结点中插入新值,可以将这个3-节点转换为3个2-节点,然后将其中一个2-节点与父节点的2-节点合并为3-节点。
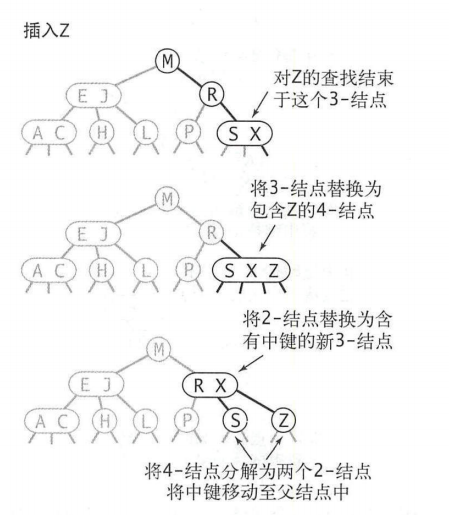
可以发现2-3树在拥有高效查找的情况下还拥有插入的高效。
红黑树
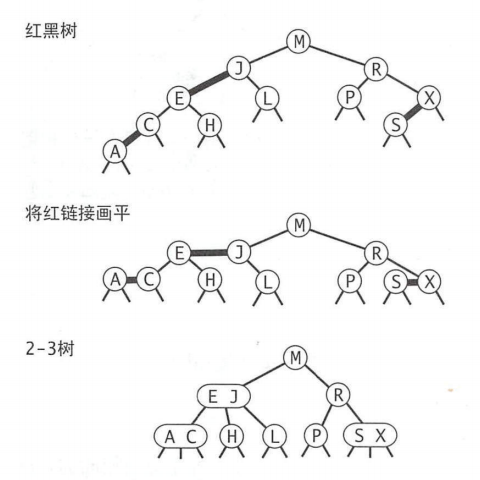
红黑树背后的基本思想是用标准的二叉查找树(完全由2-节点构成)和一些额外的信息(替换3-节点)来表示2-3树。树种的链接分为两种类型:红链接将两个2-节点连接起来构成一个3-节点,黑连接则是2-3树中的普通链接。确切来说,将3-节点表示为由一个左斜的红色链接连接两个2-节点。这种情况下,我们的红黑树就可以直接使用标准二叉树的get方法来查找节点,在插入节点时,我们可以对节点进行转换,派生出一颗对应的2-3树。
可以发现:
- 红链接均为左链接
- 没有任何一个结点同时和两条红链接相连
你可以将红黑树画平,就可以发现其中奥妙。
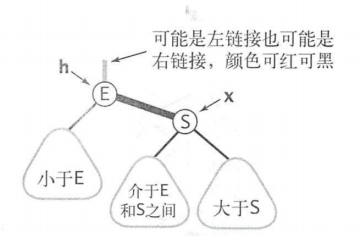
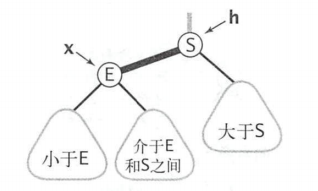
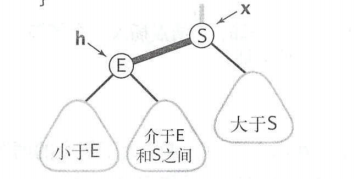
红黑树会有一个所谓的难点,就是旋转,想必你曾经因为这个问题很是恼火,那么从2-3树的角度来看看旋转的本质吧。
| 左旋 | 右旋 |
|---|---|
 |
 |
 |
|
左旋右旋的本质目的,就是为了保证红色链接均为左链接。
你知道各类数据库的索引结构吗?
这里要介绍有二叉查找树,平衡二叉树,B-Tree,B+-Tree,Hash结构。
- 二叉查找树
每个节点最多只有两个子树的结构。对于一个节点来说,他的左子树节点小于他,右子树节点大于他。

- 平衡二叉树
在二叉树的基础上,他的任意一个节点的左子树高度均不超过1。
但是二叉树因为每个节点只有两个子节点,所以树的高度非常高,IO次数也会增大,有时候效率并没有全表扫描高。所以这时候就需要B-Tree了。
- B-Tree
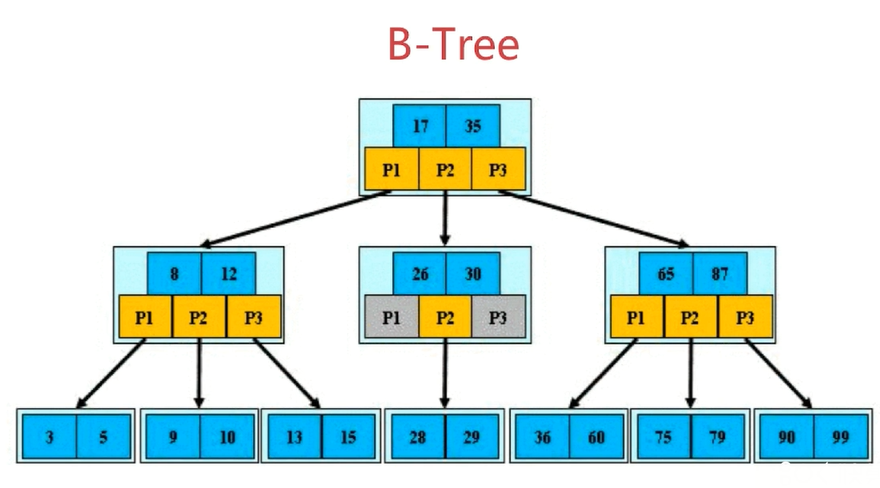
每个节点最多有m个孩子,m阶B树。根节点至少包括两个孩子,树中每个节点最多包含有m个孩子,所有叶子节点都位于同一层。目的是为了让每一个索引块尽可能多的存储更多的信息,尽可能减少IO次数。
- B+-Tree
树中节点指针与关键字数目一样,且数据均在叶子节点中。
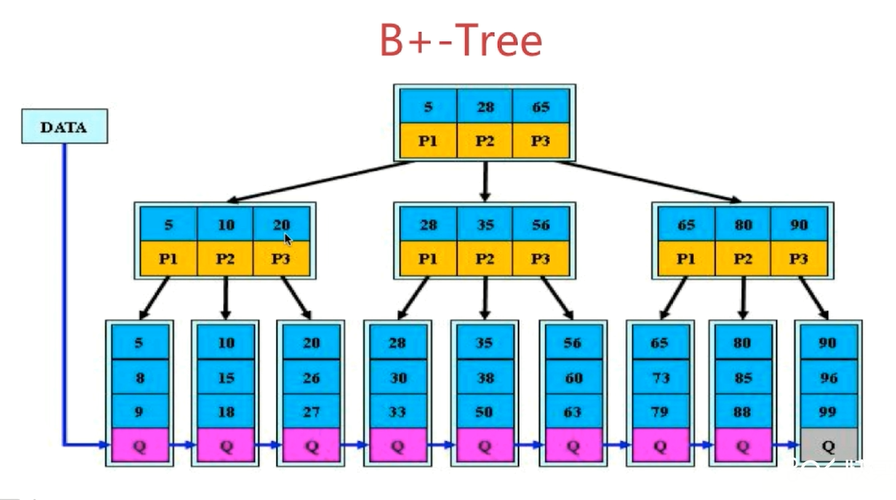
所以B+Tree更适合用来做索引存储,磁盘读写代价低,查询效率稳定。这也是Mysql所使用的索引,而且Mysql为了增加查询速度,引入了DATA指针,可以直接访问底层数组。
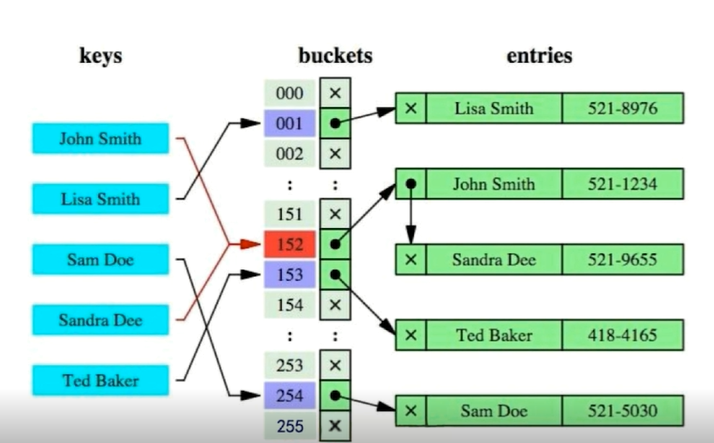
- Hash索引
通过Hash运算直接定位到目标。
- BitMap位图索引
修改数据时对其他数据影响极大。
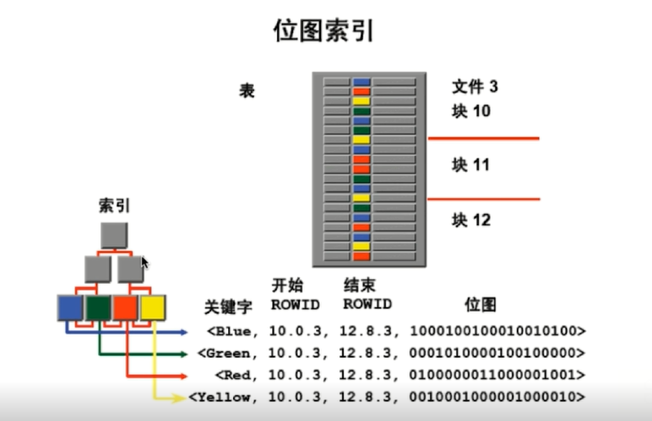
这类索引目前只有Oracle使用了。
数据库为什么选择B+树索引?HashMap为什么选择红黑树索引?
这个问题的答案是因为磁盘。
数据库的查询是位于磁盘,读取到数据之后存储到索引结构中。
HashMap是位于内存中。
而磁盘和内存的数据读取有很大差异,磁盘每次读取的最小单位是一簇,他可以是2、4、8、16、32或64个扇区的数据。而内存我们可以按照位来读取。
这种情况下我们在数据库中使用红黑树,建立的索引可能会庞大到无法想象,而在HashMap中使用B+树,对于HashMap频繁的插入操作,B+树无疑是要频繁进行修改的。
HashMap的扩容机制了解吗?另外你知道为什么HashMap容量要保持2的N次方吗?
HashMap扩容的主要情况是当前的容量达到负载因子*容器容量。
负载因子的默认值是0.75,使用这个值的原因是太小时没有扩容的必要,太大时才扩容会影响性能,所以选择了0.75这个值。
另一个问题是HashMap为什么要保持容量为2的N次方的容量。
可以当作是为了防止hash求值碰撞的问题。在使用2的N次方容量时,数组下标的求取拥有很高的散列程度。
这个是之前看到的一篇文章。

左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110与的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。
同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行与,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
HashMap线程不安全的主要情况是什么?
HashMap线程不安全的主要情况是在扩容时,调用resize()方法里的rehash()时,容易出现环形链表。
这样当获取一个不存在的key时,计算出的index正好是环形链表的下标时就会出现死循环。
rehash操作是重建内部数据结构,从而哈希表将会扩容两倍。通常,默认加载因子(0.75)在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
如果很多映射关系要存储在 HashMap 实例中,则相对于按需执行自动的 rehash 操作以增大表的容量来说,使用足够大的初始容量创建它将使得映射关系能更有效地存储。
小彩蛋
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这是HashMap的hash函数,不知道你有没有发现^ (h >>> 16)这个操作。
^ (h >>> 16)的目的就是因为hashcode的高16位在hashcode中其实并没有多大作用,为了让这16位也起到作用,这里将hash与它自己的高16位亦或,让高16位也参与hash运算中。
HashMap这些问题你知道吗?的更多相关文章
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- HashMap的工作原理
HashMap的工作原理 HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间 ...
- 计算机程序的思维逻辑 (40) - 剖析HashMap
前面两节介绍了ArrayList和LinkedList,它们的一个共同特点是,查找元素的效率都比较低,都需要逐个进行比较,本节介绍HashMap,它的查找效率则要高的多,HashMap是什么?怎么用? ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- 学习Redis你必须了解的数据结构——HashMap实现
本文版权归博客园和作者吴双本人共同所有,转载和爬虫请注明原文链接博客园蜗牛 cnblogs.com\tdws . 首先提供一种获取hashCode的方法,是一种比较受欢迎的方式,该方法参照了一位园友的 ...
- HashMap与HashTable的区别
HashMap和HashSet的区别是Java面试中最常被问到的问题.如果没有涉及到Collection框架以及多线程的面试,可以说是不完整.而Collection框架的问题不涉及到HashSet和H ...
- JDK1.8 HashMap 源码分析
一.概述 以键值对的形式存储,是基于Map接口的实现,可以接收null的键值,不保证有序(比如插入顺序),存储着Entry(hash, key, value, next)对象. 二.示例 public ...
- HashMap 源码解析
HashMap简介: HashMap在日常的开发中应用的非常之广泛,它是基于Hash表,实现了Map接口,以键值对(key-value)形式进行数据存储,HashMap在数据结构上使用的是数组+链表. ...
- java面试题——HashMap和Hashtable 的区别
一.HashMap 和Hashtable 的区别 我们先看2个类的定义 public class Hashtable extends Dictionary implements Map, Clonea ...
- 再谈HashMap
HashMap是一个高效通用的数据结构,它在每一个Java程序中都随处可见.先来介绍些基础知识.你可能也知 道,HashMap使用key的hashCode()和equals()方法来将值划分到不同的桶 ...
随机推荐
- Java学习笔记之---构造方法
Java学习笔记之---构造方法 (一)构造方法的特性 构造方法不能被对象单独调用 构造方法与类同名且没有返回值 构造方法只能在对象实例化的时候被调用 当没有指定构造方法时,系统会自动添加无参的构造方 ...
- 不要天真了,这些简历HR一看就知道你是培训的,质量不佳的那种
上到职场干将下到职场萌新,都会接触到包装简历这个词语.当你简历投到心仪的公司,公司内负责求职的工作人员是如何甄别简历的包装程度的?Jason 老师根据自己的经验写下了这篇文章,谁都不是天才,包装无可厚 ...
- android_aidl
好久未更新博客了.人都是这样,刚开始对某一样东东冲劲十足,时间一长,很难坚持下去了,我这博客也是.所以我要打破成规,继续更新. 本次博客谈谈adil的用法.aidl的全称叫什么来着忘了,不过不要紧,重 ...
- binlog_format日志错误
客户磁盘空间不够用,发现mysql的err日志文件已每天大概600M-800M的速度增长,开头考虑作日志切割,打开发现,整个7.8G的文件里面百分之99的文件全部是如下所示的warning警告信息 1 ...
- MyBatis 使用枚举或其他对象
From<Mybatis从入门到精通> 1.笔记: <!-- 6.3 使用枚举或者其他对象 6.3.1 使用MyBatis提供的枚举处理器 不懂: 因为枚举除了本身的字面值外,还可以 ...
- ZIP:ZipEntry
ZipEntry: /* 此类用于表示 ZIP 文件条目. */ ZipEntry(String name) :使用指定名称创建新的 ZIP 条目. ZipEntry(ZipEntry e) :使用从 ...
- [记录] Linux登录前后提示语
Linux登录前后提示语 /etc/issue 本地(虚拟控制台KVM等)登录前提示语,支持转义字符 /etc/issue.net 远程(telnet,ssh)登录前提示语,不支持转义字符 /etc/ ...
- Excel催化剂开源第36波-图片Exif信息提取,速度超快,信息超全
Excel催化剂在文件处理方面,功能做到极致,但其实很大功劳都是引用一些开源社区的轮子库,不敢独占好处,此篇给大家分享下抓取图片的Exif信息的好用的轮子. 此篇对应的Excel催化剂功能实现:第83 ...
- Hadoop值Partition分区
分区操作 为什么要分区? 要求将统计结果按照条件输出到不同文件中(分区).比如:将统计结果按 照手机归属地不同省份输出到不同文件中(分区) 默认 partition 分区 /** 源码中:numRed ...
- 编写Django项目并使用uwsgi和nginx部署在Linux平台
内容转载自:我自己的博客地址 这是花费了一个月的时间摸索整理出来的一份总结.分享出来一方面是给新人一个借鉴,另一方面对自己也算是个备份. --- *** 整个Django项目: ├── example ...