Storm 系列(四)—— Storm 集群环境搭建
一、集群规划
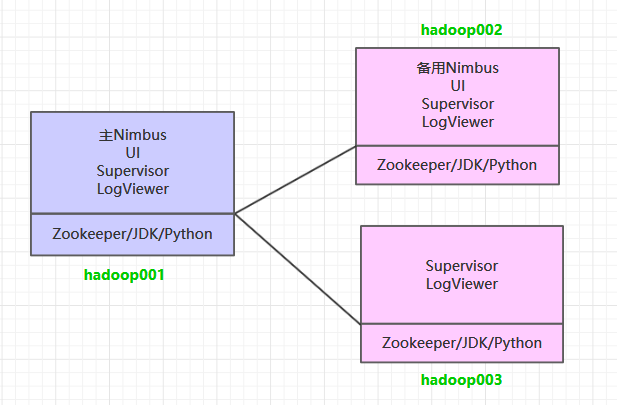
这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus 服务外,还在 hadoop002 上部署备用的 Nimbus 服务。Nimbus 服务由 Zookeeper 集群进行协调管理,如果主 Nimbus 不可用,则备用 Nimbus 会成为新的主 Nimbus。
二、前置条件
Storm 运行依赖于 Java 7+ 和 Python 2.6.6 +,所以需要预先安装这两个软件。同时为了保证高可用,这里我们不采用 Storm 内置的 Zookeeper,而采用外置的 Zookeeper 集群。由于这三个软件在多个框架中都有依赖,其安装步骤单独整理至 :
三、集群搭建
1. 下载并解压
下载安装包,之后进行解压。官方下载地址:http://storm.apache.org/downloads.html
# 解压
tar -zxvf apache-storm-1.2.2.tar.gz
2. 配置环境变量
# vim /etc/profile添加环境变量:
export STORM_HOME=/usr/app/apache-storm-1.2.2
export PATH=$STORM_HOME/bin:$PATH使得配置的环境变量生效:
# source /etc/profile3. 集群配置
修改 ${STORM_HOME}/conf/storm.yaml 文件,配置如下:
# Zookeeper集群的主机列表
storm.zookeeper.servers:
- "hadoop001"
- "hadoop002"
- "hadoop003"
# Nimbus的节点列表
nimbus.seeds: ["hadoop001","hadoop002"]
# Nimbus和Supervisor需要使用本地磁盘上来存储少量状态(如jar包,配置文件等)
storm.local.dir: "/home/storm"
# workers进程的端口,每个worker进程会使用一个端口来接收消息
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703supervisor.slots.ports 参数用来配置 workers 进程接收消息的端口,默认每个 supervisor 节点上会启动 4 个 worker,当然你也可以按照自己的需要和服务器性能进行设置,假设只想启动 2 个 worker 的话,此处配置 2 个端口即可。
4. 安装包分发
将 Storm 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Storm 的环境变量。
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop002:/usr/app/
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop003:/usr/app/四. 启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动 ZooKeeper 服务:
zkServer.sh start4.2 启动Storm集群
因为要启动多个进程,所以统一采用后台进程的方式启动。进入到 ${STORM_HOME}/bin 目录下,执行下面的命令:
hadoop001 & hadoop002 :
# 启动主节点 nimbus
nohup sh storm nimbus &
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动UI界面 ui
nohup sh storm ui &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &hadoop003 :
hadoop003 上只需要启动 supervisor 服务和 logviewer 服务:
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &4.3 查看集群
使用 jps 查看进程,三台服务器的进程应该分别如下:

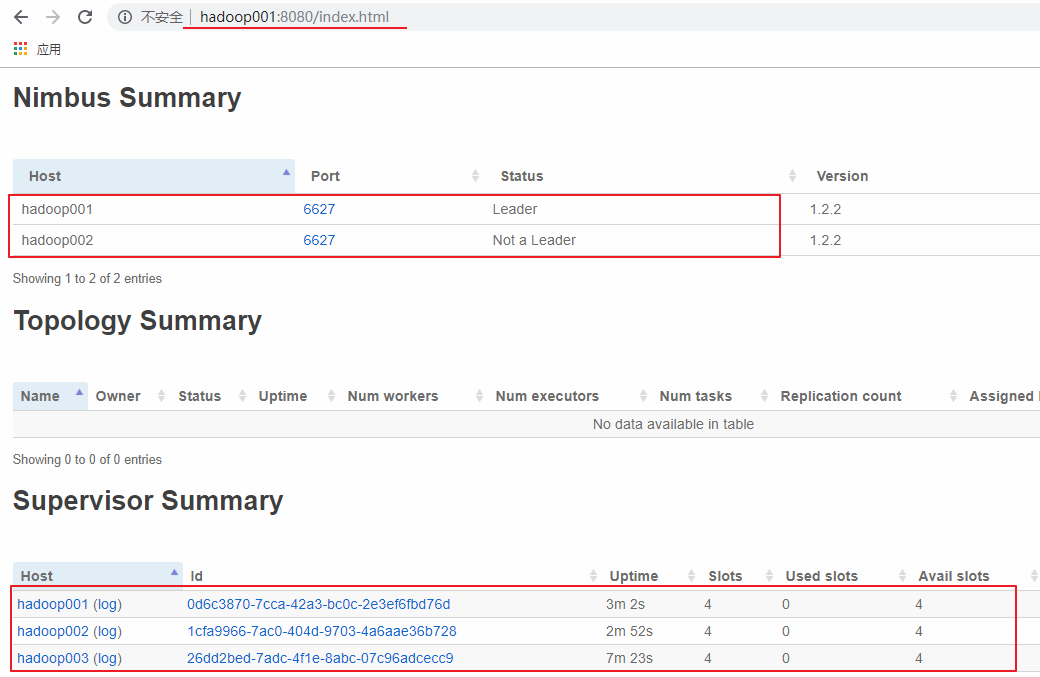
访问 hadoop001 或 hadoop002 的 8080 端口,界面如下。可以看到有一主一备 2 个 Nimbus 和 3 个 Supervisor,并且每个 Supervisor 有四个 slots,即四个可用的 worker 进程,此时代表集群已经搭建成功。
五、高可用验证
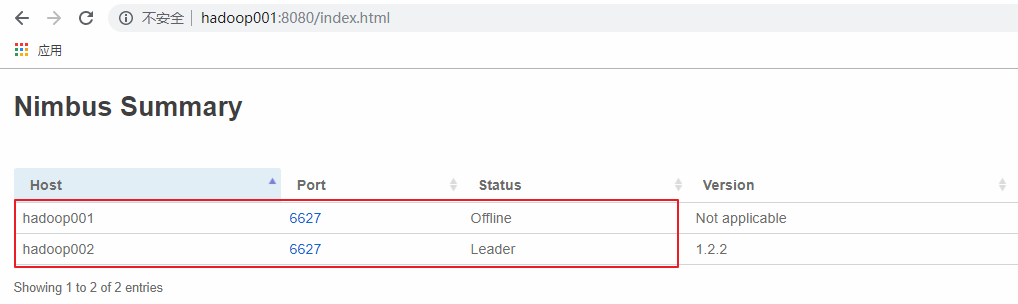
这里手动模拟主 Nimbus 异常的情况,在 hadoop001 上使用 kill 命令杀死 Nimbus 的线程,此时可以看到 hadoop001 上的 Nimbus 已经处于 offline 状态,而 hadoop002 上的 Nimbus 则成为新的 Leader。
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Storm 系列(四)—— Storm 集群环境搭建的更多相关文章
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm —— 集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- 一:Storm集群环境搭建
第一:storm集群环境准备及部署[1]硬件环境准备--->机器数量>=3--->网卡>=1--->内存:尽可能大--->硬盘:无额外需求[2]软件环境准备---& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- ZooKeeper 系列(二)—— Zookeeper单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 1.2 解压 1.3 配置环境变量 1.4 修改配置 1.5 启动 1. ...
- ZooKeeper系列(二)—— Zookeeper 单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 下载对应版本 Zookeeper,这里我下载的版本 3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- HBase —— 集群环境搭建
一.集群规划 这里搭建一个3节点的HBase集群,其中三台主机上均为Regin Server.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002上部署备用的 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
随机推荐
- 基于RobotFramework实现自动化测试
Java + robotframework + seleniumlibrary 使用Robot Framework Maven Plugin(http://robotframework.org/Mav ...
- 【Kubernetes 系列一】Kubernetes 概述
以下内容还可以通过 Google Slide 查看:https://docs.google.com/presentation/d/1eYP4bkVBojI_e6PqdpxIf0hvWO-JwAf-fy ...
- MySQL学习随笔记录
安装选custmer自定义安装.默认安装全部在c盘.自定义安装的时候有个advance port选项用来选择安装目录. -----------------------MySQL常见的一些操作命令--- ...
- ABAP_增强点查找
*&---------------------------------------------------------------------* *& Report Z_FIND_EN ...
- Spring系列(四):Spring AOP详解
一.AOP是什么 AOP(面向切面编程),可以说是一种编程思想,其中的Spring AOP和AspectJ都是现实了这种编程思想.相对OOP(面向过程编程)来说,提供了另外一种编程方式,对于OOP过程 ...
- 什么是CWS、WBS、OBS
今天公司进行CMMI资质审核,审核人提到了WBS,以前对这些名词没有太过于注意,后经过审核人的审核对这个名词有了一个大致的了解,并结合项目经验和网上的一些资料,编此文档.不为别人,主要怕自己忘记了. ...
- Django上线部署之Apache
环境: 1.Windows Server 2016 Datacenter 64位 2.SQL Server 2016 Enterprise 64位 3.Python 3.6.0 64位 4.admin ...
- Selenium+java - 手把手一起搭建一个最简单自动化测试框架
写在前面 我们刚开始做自动化测试,可能写的代码都是基于原生写的代码,看起来特别不美观,而且感觉特别生硬. 来看下面一段代码,如下图所示: 从上面图片代码来看,具体特征如下: driver对象在测试类中 ...
- 【改革春风吹满地 HDU - 2036 】【计算几何-----利用叉积计算多边形的面积】
利用叉积计算多边形的面积 我们都知道计算三角形的面积时可以用两个邻边对应向量积(叉积)的绝对值的一半表示,那么同样,对于多边形,我们可以以多边形上的一个点为源点,作过该点并且过多边形其他点中的某一个的 ...
- java JVM原理讲解和调优和gc