Community structure enhanced cascade prediction 笔记
一、摘要
深度学习不用去手工提取特征,但是现有深度模型没有在传播预测任务中使用社区结构。所以提出一个CS-RNN框架,把社区在传播中的影响考虑在内,做传播预测。
二、杂记
- 贡献:①引入community structure information;②CS-RNN模型包含社区结构标签预测层(community structure labels prediction layer),可以预测下一个活跃节点的社区结构标签;③参数健壮、结果好;(PS:原文中3、4点被总结到此处第3点了,单从此处来看创新并不是很吸引人。)
- 参考文献结论:strong community 通过加强局部和社区内部的传播,有利于信息进行全局传播。
- 文章缺点:参考文献列举了随着神经网络发展产生的一些深度模型,但是并没有描述这些深度模型的侧重点或者缺点。(PS:那如何突出自己工作的重要性)
三、模型思想
3.1 问题定义:
Network:\(G=(V,E)\),\(V\)是顶点代表用户,\(E\)是边代表用户间关系;
Cascade:\(S=\{\left(t_{i}, v_{i}\right) | v_{i} \in V, t_{i} \in[0,+\infty), t_i \le t_{i+1}, i=1,2,...,N \}\),代表节点\(v_i\)在\(t_i\)时刻分享了消息;
Community:\(G(V',E')\)代表内部连接紧密的子图。假设图\(G=(V,E)\)可以被分为q个子部分\(\mathcal{L} = \left\{L_{1}, L_{2} \ldots L_{q}\right\}\),一个用户 \(v_i\) 只能属于一个社区,且它的社区标签并定义为\(c_{v_i} \in X_{\mathcal{X}}\);
问题描述:观察之前的传播过程,给定k个时间节点对(Cascade)表示为\(S_{\le k}\),在传播级联中进行序列建模,来预测下一个激活节点的概率,即\(p(v_{k+1}|S_{\le k})\),还要预测下一个激活节点的社区标签\(c_{v_{k+1}}\),即\(P{c_{v_{k+1}}|S_{\le k}}\),还要预测节点激活的确切时间。
3.2 模型框架
基本原理:信息传播到下一个节点不仅跟活跃节点的历史序列状态有关,还跟信息传播过的社区有关。
模型框架图如下,带标号和有颜色背景的无边缘线图形,是我为了更好的描述框架而加上的:

输入层:
①图中标记1的部分,把节点\(v_k\)转换成一个低维的向量\(\mathbf{v}_k \in R^{d_v}\),\(\mathbf{v}_{k}=\mathbf{W}_{e m v}^{T} v_{k}\);
②图中标记2的部分,把社区标签\(c_{v_k}\)也初始化转换为低维向量\(\mathbf{c}_{v_k} \in R^{d_c}\),\(\mathbf{c}_{v_{k}}=\mathbf{W}_{e m c}^{T} c_{v_{k}}\);
隐藏层:
①图中标记3的部分,这里是把\(\mathbf{v}_1\)到\(\mathbf{v}_k\)用一个RNN串联起来,表示每个节点的初始隐含表示,由之前得到的表示向量\(\mathbf{v}_k\)和传播过程中上一个节点的隐含表示所决定:\(\mathbf{h}_{k}^{(0)}=R N N\left(\mathbf{v}_{k}, \mathbf{h}_{k-1}^{(0)}\right)\)。其中,\(h_0^{(0)}\)由全0的向量初始化,RNN层中可以使用GRU和LSTM。这里暂时把\(\mathbf{h}_{k}^{(0)}\)和上一步得到的\(\mathbf{c}_{v_{k}}\)拼接起来,组成\(\mathbf{h}_{k}^{(1)}= \mathbf{h}_{k}^{(0)} \oplus \mathbf{c}_{v_{k}}\),备用。
②图中标记4的部分,把传播级联中的时间t,也按照序列顺序用RNN串联,得到\(\mathbf{h}_{k}^{(2)}=R N N\left(\mathbf{t}_{k}, \mathbf{h}_{k-1}^{(2)}\right)\)。
最后,把上述的两个(其实是三个\(\mathbf{h}_{k}^{(1)}\)由两部分组成)拼接起来,组成一个向量(图中三色向量图形),然后通过一个线性变换层(FC层)和一个非线性变换(激活层)【图中Linear and Activation Layer】,得到结果:\(\mathbf{h}_{k}^{\mathrm{cas}}=\delta\left(\mathbf{W}_{h}^{T}\left(\mathbf{h}_{k}^{(1)} \oplus \mathbf{h}_{k}^{(2)}\right)+\mathbf{b}_{h}\right)\)。
社区结构标签产生:(图中右上部分)
由上面得到的\(\mathbf{h}_{k}^{\mathrm{cas}}\),在通过一个线性变换层和激活层,目的是为了把\(\mathbf{h}_{k}^{\mathrm{cas}}\)映射到和社区结构标签嵌入向量同样的空间中去,得到\(\mathbf{h}_{k}^{\mathrm{com}}=\delta\left(\mathbf{W}_{\mathrm{com}}^{T} \mathbf{h}_{k}^{\mathrm{cas}}+\mathbf{b}_{\mathrm{com}}\right)\),然后把\(\mathbf{h}_{k}^{\mathrm{com}}\)和所有社区标签向量做余弦相似度,在用一个softmax层归一化所有相似度,得到(预测)下一个激活节点的社区标签,\(\mathbf{p}_{k}^{c o m}=\operatorname{sigmoid}\left(\mathbf{h}_{k}^{c o m} \mathbf{W}_{e m c}^{T}\right)\)。
下一个激活节点的产生:(图中右上部分)
我们可以看到,图中的右上部分有一个类似残差神经网络(大雾)的连接,其实是作者又做了一个下一个激活节点的预测,具体如下:
通过模型左侧得到的\(h_k^{cas}\),和刚刚预测的社区结构标签 $ \mathbf{p}_{k}^{\text {com}}$,作者把这两个向量拼接起来,再送入线性变换层和激活层,得到 \(\mathbf{h}_{k}^{\text {node }}=\delta\left(\mathbf{W}_{\text {node }}^{T}\left(\mathbf{h}_{k}^{\text {cas }} \oplus \mathbf{p}_{k}^{\text {com }}\right)+\mathbf{b}_{\text {node }}\right)\),然后如法炮制,在计算隐向量\(h_k^{node}\)和所有节点的嵌入表示之间的余弦相似度,再用softmax层归一化,得到每个节点的概率表示,从而预测下一个激活结点是哪个节点。
下一个激活时间预测:(图中左上部分)
利用最开始得到的传播级联第K步的表示\(h_k^{cas}\),还可以预测传播过程的第K+1步和第k步之间的时间间隔,即\(t_{k+1}-t_{k}=\mathbf{W}_{t}^{T} \mathbf{h}_{k}^{c a s}+\mathbf{b}_{t}\)。
哇,这是一口气做了三个预测,通过传播级联第K步的表示\(h_k^{cas}\),文中做了下一个激活节点的预测,下一激活节点所在的社区标签的预测,还做了时间间隔的预测,感觉文章要做multi-task了(是不是做multi-task会有收获呢?),然而没有,文中的损失函数:
\[
\operatorname{Loss}(Q)=\sum_{f=1}^{F} \sum_{i=1}^{N_{f}-1} \log p\left(\left(t_{k+1}, v_{k+1}, c_{k+1}\right) | c_{v_{k}}, S_{\leq k}\right)
\]
利用基于时间的反向传播(backpropagation through time,BPTT)来训练模型,最后用SGD,mini-batch和Adam优化。为了加快速度,在训练过程中使用正交初始化方法。
四、实验
利用合成数据和真实数据(Digg数据集)。主要在合成数据集上做了分析,对于真实数据集分析简短。
设备:Tesla V100 32G GPU, Intel Xeon E5 CPU,512G内存。
合成数据生成方法:(不太懂,之后用到生成数据可以参考这里,关键是传播都能够生成!)
网络结构和传播过程都是生成的。
网络结构生成,两种方法:①kronecker graph model;②LFR bechmark,更像真实网络。产生两种网络结构①random network(RD);②层级社区网络(HC)。
传播过程生成,对于每个节点,按照一定的时间分布来设置被激活用户的激活时间,参考其他文献,也设置了两种分布,①混合指数分布(Exp);②混合瑞利分布(Ray);
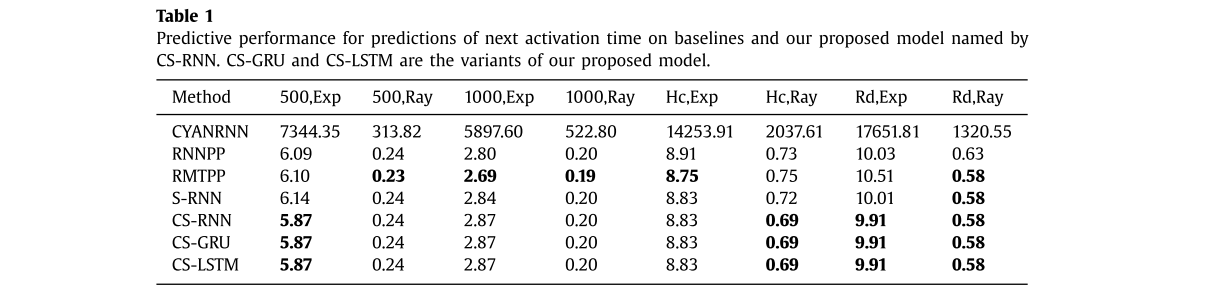
对比算法:
CYANRNN(AAAI’17):使用attention-based RNN,利用传播过程中的交叉依赖性(什么是交叉依赖性?)。
RNNPP(AAAI’17):用RNN的视角处理point process,建模背景和历史作用。可以预测event时间,主要类型的event和子类型的event。作者在论文中把社区结构当做main-types,把node当做sub-type。
RMTPP(SIGKDD‘16):将时间点过程的强度函数视为历史的非线性函数,利用RNN自动学习事件历史影响的表示。
S-RNN,CS-RNN,CS-GRU,CS-LSTM:分别是去掉社区结构的方法,原始方法,使用GRU的方法和使用LSTM的方法。前两个是为了对比结果证明,社区结构有用的,后面两个是对比GRU好还是LSTM好。
结果还是比较中规中矩的,提出的方法肯定是最优的,社区结构是有用的。


五、其他
瑞利分布(Rayleigh Distribution):当一个随机二维向量的两个分量呈独立的、有着相同的方差的正态分布时,这个向量的模呈瑞利分布。
六、参考文献
[1]. Liu, Chaochao, et al. “Community Structure Enhanced Cascade Prediction.” Neurocomputing, vol. 359, Elsevier B.V., 2019, pp. 276–84, doi:10.1016/j.neucom.2019.05.069.
Community structure enhanced cascade prediction 笔记的更多相关文章
- {ICIP2014}{收录论文列表}
This article come from HEREARS-L1: Learning Tuesday 10:30–12:30; Oral Session; Room: Leonard de Vinc ...
- Content-Type List
Content-Type List Description of Data Content Typical Filename Extensions MIME type/subtype Te ...
- A Brief Review of Supervised Learning
There are a number of algorithms that are typically used for system identification, adaptive control ...
- 蛋白质结构模型和功能预测:I-TASSER工具的使用
I-TASSER是一款用于预测蛋白质结构和功能的工具,网站链接:https://zhanglab.ccmb.med.umich.edu/I-TASSER/ 具体描述如下: I-TASSER (Iter ...
- 关于Intel芯片架构的发展史
---恢复内容开始--- 当你真正的深入去行走在底层的道路上,你就会接触大量的一些貌似懂的概念性名词,比如Intel公司的x86架构,x64等等,又或者是当年的386,486等等,唉,有的时候真的是 ...
- 论文解读(DFCN)《Deep Fusion Clustering Network》
Paper information Titile:Deep Fusion Clustering Network Authors:Wenxuan Tu, Sihang Zhou, Xinwang Liu ...
- hibernate笔记--cascade级联以及inverse属性
cascade : 不管是单向多对一还是一对多,或者是双向的一对多关系,在一的一端映射文件中有一个set标签,在多的一端有many-to-one标签,拿前几篇笔记里讲的Grade和Student举例, ...
- scikit-learn使用笔记与sign prediction简单小结
经Edwin Chen的推荐,认识了scikit-learn这个非常强大的python机器学习工具包.这个帖子作为笔记.(其实都没有笔记的意义,因为他家文档做的太好了,不过还是为自己记记吧,为以后节省 ...
- [原创]java WEB学习笔记83:Hibernate学习之路---双向 1-n介绍,关键点解释,代码实现,set属性介绍(inverse,cascade ,order-by )
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
随机推荐
- ACL(访问控制列表)
第六部分,访问控制列表.访问控制列表(Access Control List,ACL) 是路由器和交换机接口的指令列表,用来控制端口进出的数据包.应用场景有校园网中教师网和学生网分别管理,通过acl控 ...
- 修改IE默认页的指向
方法一: 1.打开IE浏览器 → 单击 工具 → Internet选项 2.填上你要设置的主页网址 3.重启IE浏览器,成功设置主页 方法二: 1.按住键盘"win+r" → 输入 ...
- 垂直方向margin重叠原因与解决方法
参考博客:https://blog.csdn.net/weixin_33743661/article/details/88755435
- 谈谈redis的特性以及使用场景
ok?先从String开始讲: String: 这是最简单的类型,就是普通的get和set,做简单的KV缓存. 但是在真实的开发环境中,很多men可能会吧很多复杂的结构也统一转成String去储存使用 ...
- item()方法遍历字典
Python字典的遍历方法有好几种,其中一种是for...in,这个我就不说明,在Python了几乎随处都可见for...in.下面说的这种遍历方式是item()方法. item() item()方法 ...
- 《Java基础知识》Java注解"@"详解
Java注解含义: Java注解,顾名思义,注解,就是对某一事物进行添加注释说明,会存放一些信息,这些信息可能对以后某个时段来说是很有用处的.Java注解又叫java标注,java提供了一套机制,使得 ...
- 松软科技Web课堂:JavaScript 正则表达式
正则表达式是构成搜索模式的字符序列. 该搜索模式可用于文本搜索和文本替换操作. 什么是正则表达式? 正则表达式是构成搜索模式(search pattern)的字符序列. 当您搜索文本中的数据时,您可使 ...
- 墨者 - X-FORWARDED-FOR注入漏洞实战
X-FORWARDED-FOR 首先,X-Forwarded-For 是一个 HTTP 扩展头部.HTTP/1.1(RFC 2616)协议并没有对它的定义,它最开始是由 Squid 这个缓存代理软件引 ...
- Android 避免内存泄漏
什么是内存泄露? 就是该回收的内存由于种种原因没有被回收,还驻留在内存中. 内存泄露有什么影响? 可能一处小小的内存泄露就会导致整个应用卡顿,甚至崩溃. 例子说明: Toast.makeText(Ma ...
- styled-components:解决react的css无法作为组件私有样式的问题
react中的css在一个文件中导入,是全局的,对其他组件标签都会有影响. 使用styled-components第三方模块来解决,并且styled-components还可以将标签和样式写到一起,作 ...