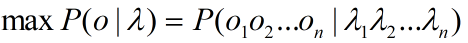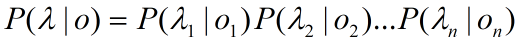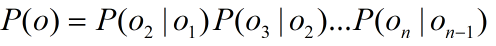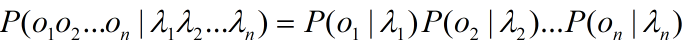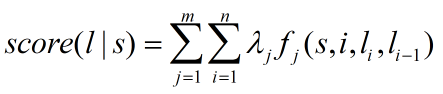一、简介
针对现有中文分词在垂直领域应用时,存在准确率不高的问题,本文对其进行了简要分析,对中文分词面临的分词歧义及未登录词等难点进行了介绍,最后对当前中文分词实现的算法原理(基于词表、统计以及序列标注等算法)进行了简要阐述,并对比了现有技术的优缺点,并给出了本文作者在工程应用上的中文分词调优的经验分享。
二、引言
中文信息处理是指自然语言处理的分支,是指用计算机对中文进行处理。和大部分西方语言不同,汉语的词语之间没有明显的空格标记,句子是以字串的形式出现。常规来说,对中文进行处理的第一步就是进行自动分词,即将字串转变成词串,以便后续对中文进行词法分析,如词性标注、语义角色标注等。
目前有较多优秀开源的中文分词工具,如jieba、HanLP、ansj、IKAnalyzer、FudanNLP、PKUseg等,为什么还要探讨中文分词?最主要的原因:在特定的垂直领域,例如医疗健康,中文分词的泛化能力较差,对特定疾病术语、疾病症状等分词准确率较差。在搜索引擎系统中,采用词汇、短语、句子等综合排序,中文分词的结果间接地对上述排序做贡献,故而影响了搜索引擎的排名结果(即期望的搜索结果未能排在前面)。在推荐系统中,运用自然语言处理技术提供特征,首当其冲为中文分词提供词法分词,中文分词的好坏也对推荐结果造成了较大的影响。在对话系统中,若是FAQ类型,则与搜索引擎处理方式类同,在此不再赘述了;若是非FAQ类型,中文分词对语义理解会造成一定的困扰,让对话进行下去或者在尽可能短的轮数完成特定的任务带来一些困难。综上所述,为了满足特定的垂直领域任务,研究中文分词技术,并构建自动中文分词势在必行。
三、中文分词难点
中文分词的难点主要集中在分词歧义与未登陆词上,其中未登录词(即不在词表中,或者不在训练语料中等)较分词歧义更加困难一些。分词歧义主要分为交集歧义、组合歧义以及自然语义歧义,具体内容如下:
1. 交集歧义
我们/ 的/ 士兵/ 同志
我们/ 的士/ 兵/ 同志
此类情形,一般由分词方式与词典造成的,可对大规模语料挖掘,一方面可以挖掘词汇来扩展词典,另一方面可挖掘句式,进行分词消歧。
2. 组合歧义
乔峰/ 从/ 马上/ 下来
乔峰/ 从/ 马/ 上/ 下来
此类情形,大多由词典造成的,可对大规模语料进行挖掘,补充词典或者进行句式挖掘,进而实现分词消歧。
3. 自然语义歧义
乒乓球/ 拍卖/ 完了
乒乓球拍/ 卖/ 完了
此类情形,多种分词方式在语义上均没问题,但需结合具体的上下文语境,来选择正确的中文分词方式。
综上所述,由于自然语义歧义较为复杂,对文本理解的要求比较高,因此,目前对中文分词的研究主要集中于交集歧义与组合歧义的处理。此外,未登录词层出不穷,给中文分词造成了极大的困难,有些的解决方法依赖新词发现去实现,并辅以人工校验并添加入词库中,本质上是一种延迟处理的思路,本文作者倾向于在根据句式在大规模语料中进行挖掘。
四、中文分词算法
中文分词算法从大类上来分,主要分为基于词表、统计以及序列标注的分词方式,在特定的应用场景下,可根据情况选择相应的实现方式。
1. 基于词表的中文分词
简单来说,根据维护的大规模词典,在词典中查找某一个固定长度的字组合,若未能查找到,则剔除一个字,直至找到一个词为止。基于词表的方式主要有正向最大匹配、逆向最大匹配以及双向最大匹配,以下简要介绍下逆向最大匹配的实现,其中正向最大匹配与逆向匹配类同,在此就不再赘述了。
图-1 逆向最大匹配分词
如图-1所示,为逆向最大匹配分词的实现,其中横向箭头为下一步移动方向,纵向箭头包含的部分为待查询字组合。图中以5最为最大长度词汇,即从右向左以5作为滑动窗口进行查找,若查找到则以前词的长度,向左整体平移,如图-1中前词“同志”,则整体平移至“我们”,若长度不足5,则将整体作为滑动窗口。
针对基于词表的中文分词实现,相对正向最大匹配而言,逆向最大匹配更符合中文语言表述习惯。在实际应用中,通常会结合正向与逆向,即双向最大匹配分词来处理分词歧义,若正向与逆向分词的个数相同,则通常选择单字个数少的实现方式;若个数不相同,可选择单字个数少的方式,也可以采用启发式规则,采用长词优先的策略,或者借助N-Gram模型统计邻接词共现频率来进行选择, 从而解决分词歧义的问题。
从上面描述可以看出,基于词表的分词效率较高,但非常依赖词典的规模,因而对未登录词不敏感,采取合适的启发策略,能在一定程度上解决分词分歧问题,但是局限性较大,其分词工具的典型代表为IKAnalyzer,需要用户维护较多的领域词典数据。另外构建词表时,维护词汇的频率对后续统计任务求解最短距离也是一种有利的辅助。
2. 基于统计的中文分词
承接上文所述,借助N-Gram模型统计邻接词的共现频率,也可视为邻接词间的距离。若将句子的分词看做有向图,图中顶点为字或者词汇(字的组合),顶点间的边的长度(即距离)采用N-Gram模型从大规模语料中统计,并进行演化计算,则将中文分词问题转化为求最短路径问题,如图-2所示。

图-2 最短路径中文分词
最短路径采用动态规划来计算,通过从源点开始,逐个增加邻接边,并计算出所有与该邻接边顶点的最短距离,则该顶点作为下一次局部统计的开始节点(即贪心算法),然后再次增加邻接边,直至到达目标节点,最后采用回溯方式,返回最短路径,则该最短路径即为目标分词结果,如图-2所示,"我们/的/士兵"即为最短路径7上的目标路径。需要指出最短路径本质上依然利用了词表的信息,利用了词(字)与词(字)的共现频率来进行计算,是词表方法的扩展。另外,N-最短路径算法也常用于中文分词,例如搜索引擎的全切分方式,在所有可能的路径中找出前N个最短路径,即N种分词结果作为粗分结果。
从上图可以看出,基于统计的分词方式,比较依赖词或者字的共现频率统计,故而对未登录词不敏感,由于有了统计信息的存在,在较大程度上,能够解决分词歧义的问题,其分词工具的典型代表为HanLP以及ansj。
3. 基于序列标注的中文分词
基于词表和基于统计的分词方式,非常依赖于词典,若是没有词典,在标注语料数据充分的前提下,可以基于序列标注来处理。需要指出,基于序列标注的方式本质为基于统计的方式,为了与上文基于统计的方式进行区分,故而明确指出序列标注的方式。对于中文分词任务,常见采用4-tag标记方式,B、M、E以及S分别代表开始、中间、结束以及独立字。本文简要介绍隐马尔可夫、条件随机场以及BiLSTM+CRF模型的实现。
1)隐马尔可夫模型
图-3 隐马尔可夫序列标注
假设λ=λ1λ2...λn表示句子的输入,o=o1o2...on表示标注输出,如图-3所示,从概率的角度而言,则期望P(o|λ)的概率最大,即:
由于隐马尔可夫模型,满足如下两个假设:
a) 独立性假设,任一时刻的观测值只依赖于该时刻的马尔可夫链的状态,与其它观测值与状态无关,即:
b) 齐次马尔可夫假设,任一时刻的某一状态,只依赖于其前一时刻的状态,与其它时刻的状态与观测无关,即:
因此,从概率角度来看,期望如下公式的条件概率最大:
根据如下贝叶斯公式,在一定语料场景下,P(λ)是确定值,则只需使得P(λ|o)P(o)概率最大:
根据隐马尔可夫的假设,问题则等价于下述公式:
其中P(λk|ok)与P(ok|ok-1)分别表示发射概率和转移概率,在一定语料场景下, 前述两个概率值可以统计得出,在此不再详述了。
从上述数学表达式可以看出,由于隐马尔可夫模型的独立性假设,其观测值只依赖当前的状态,没有考虑上下文的关联,则存在标记偏置的风险,即因概率较高会偏向某个标记。此外,齐次假设考虑了状态间的关联,在一定程度上兼顾了状态间的上下文,因此在大规模语料上,能考虑到字间共现关系,以及对句式的学习,从而能解决一些分词歧义以及未登录词问题。
2)条件随机场
图-4 条件随机场序列标注
给定一个线性链条件随机场P(Y|X),当观测序列为x=x1x2...xn,状态序列为y=y1y2...yn,如图-4所示,为条件随机场模型序列标注的表达形式,与隐马尔可夫模型的不同在于,状态输出考虑了上下文关联性,其数学表达式为:
其中Z(x)为归一化因子,在一定语料场景下,其值为确定值,在此不再详述了。其中tk与sl分别表示转移特征与状态特征,分别表示定义在边上与节点上(其中,条件随机场为概率图模型)的特征函数。以CRF++工具来说,状态特征与转移特征,分别对应于特征模板的Unigram与Bigram特征。另外我们常言,CRF是feature-based的模型,即其中的特征可根据需求进行定制,从而满足特定的应用需求,特征函数更一般的表征形式为:
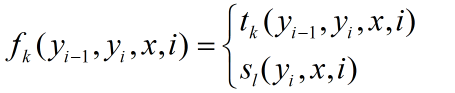
则,对于某个句子s, 有一个标注序列l, 则利用上述特征函数集对l来评分,则:
从上述数学表达式来看,通过考虑字间关联性来构建一些特征函数,例如前字依赖,后字依赖或者共同依赖等,来丰富上下文的关联性,相对隐马尔可夫模型来说,考虑的上下文关联更多,并能从全局角度(例如可定义对应状态特征函数)考虑,从而能解决标记偏置的问题。故而,在大规模语料上,解决分词歧义以及未登陆词上,准确率更高一些。
3)神经网络
图-5 基于BiLSTM + CRF序列标注
随着深度学习的引入,基于序列标注的中文分词任务也可采用BiLSTM+CRF等模型来处理,如图-5所示。其中BiLSTM层学习上下文的信息,即考虑字间的上下文关联性,其隐含输出为每个标签的分数,CRF层有转移特征,见图中标签,其考虑了标签之间的顺序性。若没有CRF层,BiLSTM层可根据每个字的最高得分标签逐个选择输出结果,但是因为存在相邻标签间存在无意义或者无效的标签,例如B标签后面紧邻B标签,则需要CRF层来对最终预测的标签进行一些约束。
综上所述,隐马尔可夫模型(HMM)相对简单,结合了N-Gram模型,模型训练效率较高,由于没有上下文的关系,存在序列偏置的风险,其分词工具的典型代表为结巴分词。条件随机场模型(CRF)考了上下文的关联,解决了序列偏置的问题,可根据需求定制特征,以便考虑更多的上下文特性,但是也给模型造成了复杂性,其训练比较耗时,其分词工具的典型代码为HanLP, ansj。基于深度学习的序列标注模型,因无需手工构造特征,因此也极具竞争力,但是其依赖大规模标注语料,好的标注语料比较难以获得,因此也具有一定的局限性,其分词工具的典型代表为PKUseg。
五. 总结
本文针对中文分词,简要阐述了其难点,并针对上述难点,从基于词表、统计以及序列标注方面进行介绍,指出了各个算法的优势及其局限。中文分词非常依赖词表,即很多时候采用词典即可分词,但是又不能过于依赖词表,因为词表不能穷举完所有的词汇,所以中文分词后面依然会成为困扰NLPer的问题。由于未登录词不断涌现,以及自然语言的复杂性,现有中分分词工具没有哪一个是完美的,在现实场景中很多时候采用混合策略,基于大规模语料训练领域中文分词,由于其代价比较大,当遇到badcase时,结合最短路径分词以及基于词典的对中文分词进行相应地调整,从而快速解决领域中文分词问题。
参考:
赵海, 蔡登, 黄昌宁, 揭春雨,中文分词又十年回顾:2007-2017.
- 深度学习将会变革NLP中的中文分词——TODO 待好好细看
见:https://www.leiphone.com/news/201608/IWvc75oJglAIsDvJ.html TODO 待好好细看
- NLP+词法系列(二)︱中文分词技术简述、深度学习分词实践(CIPS2016、超多案例)
摘录自:CIPS2016 中文信息处理报告<第一章 词法和句法分析研究进展.现状及趋势>P4 CIPS2016 中文信息处理报告下载链接:http://cips-upload.bj.bce ...
- 基于Deep Learning的中文分词尝试
http://h2ex.com/1282 现有分词介绍 自然语言处理(NLP,Natural Language Processing)是一个信息时代最重要的技术之一,简单来讲,就是让计算机能够理解人类 ...
- NLP+词法系列(一)︱中文分词技术小结、几大分词引擎的介绍与比较
笔者想说:觉得英文与中文分词有很大的区别,毕竟中文的表达方式跟英语有很大区别,而且语言组合形式丰富,如果把国外的内容强行搬过来用,不一样是最好的.所以这边看到有几家大牛都在中文分词以及NLP上越走越远 ...
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
1. NLP 走近自然语言处理 概念 Natural Language Processing/Understanding,自然语言处理/理解 日常对话.办公写作.上网浏览 希望机器能像人一样去理解,以 ...
- NLP & 中文分词
NLP & 中文分词 中文分词 (Word Segmentation, WS) 指的是将汉字序列切分成词序列. 中文自然语言处理系统 https://www.ltp-cloud.com/int ...
- nlp中文分词(jieba和pyltp)
分词是中文自然语言处理的基础.目前常用的分词算法有 1.张华平博士的NShort中文分词算法. 2.基于条件随机场(CRF)的中文分词算法. 这两种算法的代表工具包分别是jieba分词系统和哈工大的L ...
- NLP系列-中文分词(基于统计)
上文已经介绍了基于词典的中文分词,现在让我们来看一下基于统计的中文分词. 统计分词: 统计分词的主要思想是把每个词看做是由字组成的,如果相连的字在不同文本中出现的次数越多,就证明这段相连的字很有可能就 ...
- NLP系列-中文分词(基于词典)
中文分词概述 词是最小的能够独立活动的有意义的语言成分,一般分词是自然语言处理的第一项核心技术.英文中每个句子都将词用空格或标点符号分隔开来,而在中文中很难对词的边界进行界定,难以将词划分出来.在汉语 ...
随机推荐
- 谈谈surging 微服务引擎 2.0的链路跟踪和其它新增功能
一.前言 surging是基于.NET CORE 服务引擎.初始版本诞生于2017年6月份,经过NCC社区二年的孵化,2.0版本将在2019年08月28日进行发布,经历二年的发展,已经全部攘括了微服务 ...
- 前端小知识-html5
一.伪类与伪元素 为什么css要引入伪元素和伪类:是为了格式化文档树以外的信息,也就是说,伪类和伪元素是用来修饰不在文档树中的部分 伪类用于当已有元素处于的某个状态时,为其添加对应的样式,这个状态是根 ...
- imwrite imshow机制
今天在做数据增强的时候,遇到一个奇怪的问题.调用imwite生成的图片,在本地用图片查看器打开的时候是正常的.但是在代码里imshow的时候是一片亮白. 代码类似如下 gaussian_img = a ...
- 逻辑回归(Logistic Regression)详解,公式推导及代码实现
逻辑回归(Logistic Regression) 什么是逻辑回归: 逻辑回归(Logistic Regression)是一种基于概率的模式识别算法,虽然名字中带"回归",但实际上 ...
- ASP.NET Core on K8S深入学习(7)Dashboard知多少
本篇已加入<.NET Core on K8S学习实践系列文章索引>,可以点击查看更多容器化技术相关系列文章. 在第二篇<部署过程解析与Dashboard>中介绍了如何部署Das ...
- 【目标检测】RCNN算法详解
网址: 1. https://blog.csdn.net/zijin0802034/article/details/77685438 (box regression 边框回归) 2. https:// ...
- PySpark SQL 相关知识介绍
title: PySpark SQL 相关知识介绍 summary: 关键词:大数据 Hadoop Hive Pig Kafka Spark PySpark SQL 集群管理器 PostgreSQL ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- Leetcode之回溯法专题-90. 子集 II(Subsets II)
Leetcode之回溯法专题-90. 子集 II(Subsets II) 给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集). 说明:解集不能包含重复的子集. 示例: 输入 ...
- import同目录的py文件 :ModuleNotFoundError: No module named 'pdf'
报错 Traceback (most recent call last): File "D:/PyCharm 5.0.3/WorkSpace/2.NLP/2.获取数据源和规范化/5.crea ...