Steps to Install Hadoop on CentOS/RHEL 6---reference
http://tecadmin.net/steps-to-install-hadoop-on-centosrhel-6/#
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. Read More
This article will help you for step by step install and configure single node hadoop cluster.
Step 1. Install Java
Before installing hadoop make sure you have java installed on your system. If you do not have java installed use following article to install Java.
Steps to install JAVA on CentOS and RHEL 5/6
Step 2. Create User Account
Create a system user account to use for hadoop installation.
# useradd hadoop
# passwd hadoop
Changing password for user hadoop.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
Step 3. Configuring Key Based Login
Its required to setup hadoop user to ssh itself without password. Using following method it will enable key based login for hadoop user.
# su - hadoop
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
$ exit
Step 4. Download and Extract Hadoop Source
Downlaod hadoop latest availabe version from its official site, and follow below steps.
# mkdir /opt/hadoop
# cd /opt/hadoop/
# wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
# tar -xzf hadoop-1.2.1.tar.gz
# mv hadoop-1.2.1 hadoop
# chown -R hadoop /opt/hadoop
# cd /opt/hadoop/hadoop/
Step 5: Configure Hadoop
First edit hadoop configuration files and make following changes.
5.1 Edit core-site.xml
# vim conf/core-site.xml
#Add the following inside the configuration tag
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
5.2 Edit hdfs-site.xml
# vim conf/hdfs-site.xml
# Add the following inside the configuration tag
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
5.3 Edit mapred-site.xml
# vim conf/mapred-site.xml
# Add the following inside the configuration tag
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
5.4 Edit hadoop-env.sh
# vim conf/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.7.0_17
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
Set JAVA_HOME path as per your system configuration for java.
Next to format Name Node
# su - hadoop
$ cd /opt/hadoop/hadoop
$ bin/hadoop namenode -format
13/06/02 22:53:48 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = srv1.tecadmin.net/192.168.1.90
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.2.1
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1479473; compiled by 'hortonfo' on Mon May 6 06:59:37 UTC 2013
STARTUP_MSG: java = 1.7.0_17
************************************************************/
13/06/02 22:53:48 INFO util.GSet: Computing capacity for map BlocksMap
13/06/02 22:53:48 INFO util.GSet: VM type = 32-bit
13/06/02 22:53:48 INFO util.GSet: 2.0% max memory = 1013645312
13/06/02 22:53:48 INFO util.GSet: capacity = 2^22 = 4194304 entries
13/06/02 22:53:48 INFO util.GSet: recommended=4194304, actual=4194304
13/06/02 22:53:49 INFO namenode.FSNamesystem: fsOwner=hadoop
13/06/02 22:53:49 INFO namenode.FSNamesystem: supergroup=supergroup
13/06/02 22:53:49 INFO namenode.FSNamesystem: isPermissionEnabled=true
13/06/02 22:53:49 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
13/06/02 22:53:49 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
13/06/02 22:53:49 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length = 0
13/06/02 22:53:49 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/06/02 22:53:49 INFO common.Storage: Image file of size 112 saved in 0 seconds.
13/06/02 22:53:49 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/opt/hadoop/hadoop/dfs/name/current/edits
13/06/02 22:53:49 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/opt/hadoop/hadoop/dfs/name/current/edits
13/06/02 22:53:49 INFO common.Storage: Storage directory /opt/hadoop/hadoop/dfs/name has been successfully formatted.
13/06/02 22:53:49 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at srv1.tecadmin.net/192.168.1.90
************************************************************/
Step 6: Start Hadoop Services
Use the following command to start all hadoop services.
$ bin/start-all.sh
[sample output]
starting namenode, logging to /opt/hadoop/hadoop/libexec/../logs/hadoop-hadoop-namenode-ns1.tecadmin.net.out
localhost: starting datanode, logging to /opt/hadoop/hadoop/libexec/../logs/hadoop-hadoop-datanode-ns1.tecadmin.net.out
localhost: starting secondarynamenode, logging to /opt/hadoop/hadoop/libexec/../logs/hadoop-hadoop-secondarynamenode-ns1 .tecadmin.net.out
starting jobtracker, logging to /opt/hadoop/hadoop/libexec/../logs/hadoop-hadoop-jobtracker-ns1.tecadmin.net.out
localhost: starting tasktracker, logging to /opt/hadoop/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-ns1.tecadmin.ne t.out
Step 7: Test and Access Hadoop Services
Use ‘jps‘ command to check if all services are started well.
$ jps
or
$ $JAVA_HOME/bin/jps
26049 SecondaryNameNode
25929 DataNode
26399 Jps
26129 JobTracker
26249 TaskTracker
25807 NameNode
Web Access URLs for Services
http://srv1.tecadmin.net:50030/ for the Jobtracker
http://srv1.tecadmin.net:50070/ for the Namenode
http://srv1.tecadmin.net:50060/ for the Tasktracker
Hadoop JobTracker: ![]()
Hadoop Namenode: 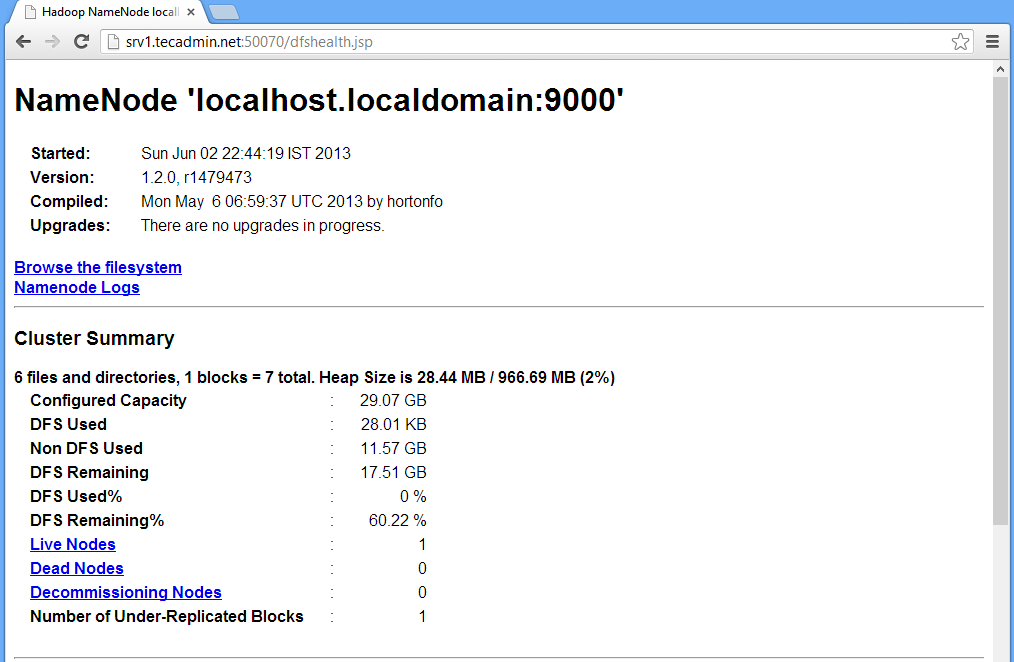
Hadoop TaskTracker: ![]()
Step 8: Stop Hadoop Services
If you do no need anymore hadoop. Stop all hadoop services using following command.
# bin/stop-all.sh
Steps to Install Hadoop on CentOS/RHEL 6---reference的更多相关文章
- How to Install Ruby on CentOS/RHEL 7/6
How to Install Ruby on CentOS/RHEL 7/6 . Ruby is a dynamic, object-oriented programming language foc ...
- Install LAMP Server (Apache, MariaDB, PHP) On CentOS/RHEL/Scientific Linux 7
Install LAMP Server (Apache, MariaDB, PHP) On CentOS/RHEL/Scientific Linux 7 By SK - August 12, 201 ...
- How to Install Tomcat 8.0.27 on CentOS/RHEL and Ubuntu【转】
https://tecadmin.net/install-tomcat-8-on-centos-rhel-and-ubuntu/ Apache Tomcat is an opensource web ...
- Install Google Chrome on Fedora 28/27, CentOS/RHEL 7.5 (在 fedora 28 等 上 安装 chrome)
今天在使用 fedora 安装 chrome 的时候遇到了问题,今天进行将安装过程进行记录下来.需要安装第三方软件仓库. 我们需要进行安装 fedora-workstation-repositorie ...
- [转载]How to Install Google Chrome 39 in CentOS/RHEL 6 and Fedora 19/18
FROM: http://tecadmin.net/install-google-chrome-in-centos-rhel-and-fedora/ Google Chrome is a freewa ...
- [转载]Install Opera 12.16 Web Browser in CentOS/RHEL and Fedora
FROM: http://tecadmin.net/install-opera-web-browser-in-centos-rhel-fedora/ Opera is an modern web br ...
- 转: How to Install MongoDB 3.2 on CentOS/RHEL & Fedora (简单易懂)
from: http://tecadmin.net/install-mongodb-on-centos-rhel-and-fedora/ MongoDB (named from “huMONGOus ...
- How To Install Java on CentOS and Fedora
PostedDecember 4, 2014 453.8kviews JAVA CENTOS FEDORA Introduction This tutorial will show you how ...
- 在CentOS/RHEL/Scientific Linux 6下安装 LAMP
LAMP 是服务器系统中开源软件的一个完美组合.它是 Linux .Apache HTTP 服务器.MySQL 数据库.PHP(或者 Perl.Python)的第一个字母的缩写代码.对于很多系统管理员 ...
随机推荐
- Django中如何使用django-celery完成异步任务1(转)
原文链接: http://www.weiguda.com/blog/73/ 本篇博文主要介绍在开发环境中的celery使用,请勿用于部署服务器. 许多Django应用需要执行异步任务, 以便不耽误ht ...
- jquery 回车切换 tab功能
挺有趣的,Jquery 回车切换tab功能的实现哦 <html> <head><!--jquery库.js--></head> <body> ...
- 树上的DP
CF#196B http://codeforces.com/contest/338/problem/B 题意:在一颗树上,给m个点,求到所有m个点距离不超过d的点的个数,所有路径长度为1. 分析:问题 ...
- linux 5 配置xmanager
0 关闭防火墙或者打开177端口 iptables -A INPUT -p udp --dport 177 -j ACCEPT 1.vi /etc/inittab id:5:initdefault: ...
- MAT(3)获取dump文件
方式一:添加启动参数 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=E:\Java\dump 生成的文件例如:java_pid2080.hprof ...
- Java 线程池学习
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具.真正的线程池接口是ExecutorService. 下面这张图完整描述了线程 ...
- ckeditor 升级到 4.5
原来的项目用的是4.0+asp.net 3.5的,一直不错,这两天升级一下ckeditor到最新版4.5.1,用的是chrome浏览器测试,发觉TextBox.Text获取不到数据,在页面用js写do ...
- Hibernate操作和保存方式
Session API [Java Hibernate 之 CRUD 操作]http://www.codeceo.com/article/java-hibernate-crud.html [Ses ...
- CloudStack采用spring加载bean(cloud-framework-spring-module模块)
CloudStackContextLoaderListener /* * Licensed to the Apache Software Foundation (ASF) under one * or ...
- 【flash】关于flash的制作透明gif的一个小技巧
关于flash的制作透明gif的一个小技巧 或者说是一个需要注意的地方 1.导出影片|gif,得到的肯定是不透明的.2.想要透明背景,必须通过发布.3.flash中想要发布gif动画的话,不能有文字, ...