基于CDH,部署Apache Kylin读写分离
一. 部署读写分离的契机
目前公司整体项目稳定运行在CDH5.6版本上,与其搭配的Hbase1.0.0无法正确运行Kylin,原因是Kylin只满足Hbase1.1.x+版本。解决方案如下
1. 升级整体CDH版本,从而获得高版本Hbase(方案风险太大)
2. 把Hbase从CDH单独剥离出来,用原生的Hbase高版本替代(方案缺点是管理Hbase不方便,原有的应用难迁移)
3. Kylin读写分离(经验证,CDH5.6的Hbase支持Kylin建CUBE,但无法读(api不兼容),所以只需在另一个集群配置高版本的Hbase即可解决问题,方案高可行,因为既不影响现有的应用,也提高了Kylin的高可用性,一举两得)
二. 环境说明
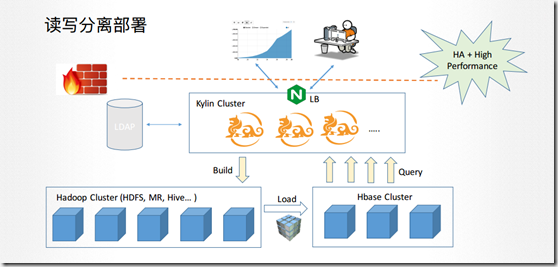
从上图可看出,Kylin支持读写分离,但其设计的初衷是为了分离集群压力,读和写分离,实现高速稳定可用。
当我们在前段发现建CUBE请求时,Build操作在计算集群实现,计算CUBE之后把它load到Hbase集群,最后转成HFILE到Hbase,从而提供前端读。具体到目前我的环境,可把上图抽象为:
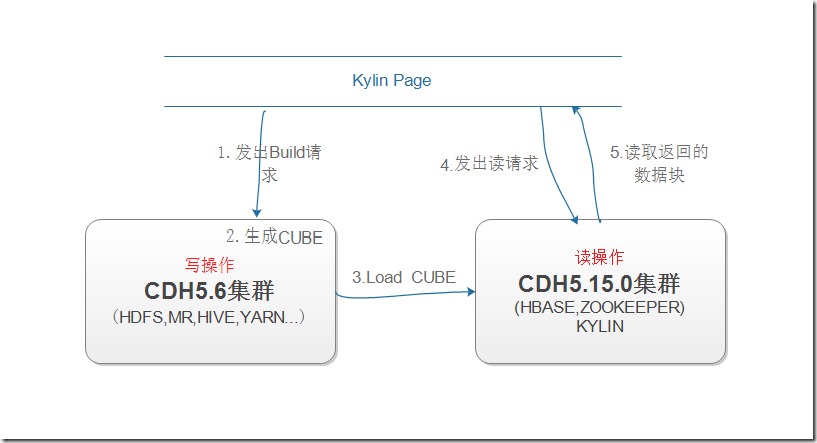
Kylin版本: apache-kylin-2.4.0-bin-cdh57
集群 机器IP 机器名称 备注
CDH5.6 10.5.8.10 see-data-pre-master-01 集群A 主 (CDH5.6)
CDH5.6 10.5.8.17 see-data-pre-slave-1 集群A 从
CDH5.15.0 10.5.8.12 test-data-master-1 集群B 主 (CDH5.15.0)
CDH5.15.0 10.5.8.6 test-data-slave-1 集群B 从
CDH5.15.0 10.5.8.7 test-data-slave-2 集群B 从
后面我们把CDH5.6集群简述为集群A,CDH5.15.0简述为集群B
三. 部署思路
部署Kylin的读写分离,顾名思义是把写的操作指向集群A,读操作指向集群B,反映到配置上,其实就是:
1. 把集群A中的Hadooo\MR\Hive\Yarn配置复制到部署Kylin的配置目录
2. 把集群B中的Hbase配置文件复制到Kylin的配置目录
3. 配置Kylin.property文件中对集群A和集群B的指针属性
四. 部署过程
1. 首先保证两个集群的所有机器都配置完域名映射,可免密访问,保证两集群可正常运行。
2. Kylin下载解压后放在集群B机器test-data-slave-2 的/home/hadoop/kylin/apache-kylin-2.4.0-bin-cdh57目录下=$KYLIN_HOME
3. 所有配置文件复制到$KYLIN_HOME(CDH的配置文件都默认放在/etc/hadoop/conf; /etc/hive/conf; ….)
- 把集群A的/etc/hadoop/conf 下的 core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 复制到$ YLIN_HOME的conf目录下
- 把集群A的/etc/hive/conf 下的 hive-site.xml 复制到$KYLIN_HOME的conf目录下
- 把集群B的/etc/hbase/conf 下的hbase-site.xml 复制到$KYLIN_HOME的conf目录下
原则上,这些从集群拷贝的配置文件都不需要改,但是如果hdfs或者hive的指向地址为本地地址,就需要改成远程访问地址!
[hadoop@test-data-slave- conf]$ ll
total
-rw-r--r-- hadoop data Dec : core-site.xml
-rw-r--r-- hadoop data Dec : hbase-site.xml
-rw-r--r-- hadoop data Dec : hdfs-site.xml
-rw-r--r-- hadoop data Dec : hive-site.xml
-rw-r--r-- hadoop data Jun : kylin_hive_conf.xml
-rw-r--r-- hadoop data Jun : kylin_job_conf_inmem.xml
-rw-r--r-- hadoop data Dec : kylin_job_conf.xml
-rw-r--r-- hadoop data Jun : kylin-kafka-consumer.xml
-rw-r--r-- hadoop data Dec : kylin.properties
-rw-r--r-- hadoop data Jun : kylin-server-log4j.properties
-rw-r--r-- hadoop data Jun : kylin-tools-log4j.properties
-rw-r--r-- hadoop data Dec : mapred-site.xml
-rwxr-xr-x hadoop data Jun : setenv.sh
-rw-r--r-- hadoop data Dec : yarn-site.xml
以下是各个主要文件的配置信息:
core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://see-data-pre-master-01:8020</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.DeflateCodec,org.apache.hadoop.io.compress.SnappyCodec,org.apache.hadoop.io.compress.Lz4Codec</value>
</property>
<property>
<name>hadoop.security.authentication</name>
<value>simple</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>false</value>
</property>
<property>
<name>hadoop.rpc.protection</name>
<value>authentication</value>
</property>
<property>
<name>hadoop.security.auth_to_local</name>
<value>DEFAULT</value>
</property>
<property>
<name>hadoop.proxyuser.oozie.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.mapred.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.mapred.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.flume.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.flume.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.HTTP.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.HTTP.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hive.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.httpfs.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.yarn.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.yarn.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.security.group.mapping</name>
<value>org.apache.hadoop.security.ShellBasedUnixGroupsMapping</value>
</property>
<property>
<name>hadoop.security.instrumentation.requires.admin</name>
<value>false</value>
</property>
<property>
<name>net.topology.script.file.name</name>
<value>/etc/hadoop/conf.cloudera.yarn/topology.py</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>65536</value>
</property>
<property>
<name>hadoop.ssl.enabled</name>
<value>false</value>
</property>
<property>
<name>hadoop.ssl.require.client.cert</name>
<value>false</value>
<final>true</final>
</property>
<property>
<name>hadoop.ssl.keystores.factory.class</name>
<value>org.apache.hadoop.security.ssl.FileBasedKeyStoresFactory</value>
<final>true</final>
</property>
<property>
<name>hadoop.ssl.server.conf</name>
<value>ssl-server.xml</value>
<final>true</final>
</property>
<property>
<name>hadoop.ssl.client.conf</name>
<value>ssl-client.xml</value>
<final>true</final>
</property>
</configuration>
hbase-site.xml
<?xml version="1.0" encoding="UTF-8"?> <!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://test-data-master-1:8020/hbase_test</value>
</property>
<property>
<name>hbase.client.write.buffer</name>
<value>2097152</value>
</property>
<property>
<name>hbase.client.pause</name>
<value>100</value>
</property>
<property>
<name>hbase.client.retries.number</name>
<value>35</value>
</property>
<property>
<name>hbase.client.scanner.caching</name>
<value>100</value>
</property>
<property>
<name>hbase.client.keyvalue.maxsize</name>
<value>10485760</value>
</property>
<property>
<name>hbase.ipc.client.allowsInterrupt</name>
<value>true</value>
</property>
<property>
<name>hbase.client.primaryCallTimeout.get</name>
<value>10</value>
</property>
<property>
<name>hbase.client.primaryCallTimeout.multiget</name>
<value>10</value>
</property>
<property>
<name>hbase.fs.tmp.dir</name>
<value>/user/${user.name}/hbase-staging</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.access.SecureBulkLoadEndpoint</value>
</property>
<property>
<name>hbase.regionserver.thrift.http</name>
<value>false</value>
</property>
<property>
<name>hbase.thrift.support.proxyuser</name>
<value>false</value>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>60000</value>
</property>
<property>
<name>hbase.snapshot.enabled</name>
<value>true</value>
</property>
<property>
<name>hbase.snapshot.master.timeoutMillis</name>
<value>60000</value>
</property>
<property>
<name>hbase.snapshot.region.timeout</name>
<value>60000</value>
</property>
<property>
<name>hbase.snapshot.master.timeout.millis</name>
<value>60000</value>
</property>
<property>
<name>hbase.security.authentication</name>
<value>simple</value>
</property>
<property>
<name>hbase.rpc.protection</name>
<value>authentication</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>60000</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase_test</value>
</property>
<property>
<name>zookeeper.znode.rootserver</name>
<value>root-region-server-test</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>test-data-master-1,test-data-slave-2,test-data-slave-1</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.rest.ssl.enabled</name>
<value>false</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///dfs/nn</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address</name>
<value>see-data-pre-master-01:8022</value>
</property>
<property>
<name>dfs.https.address</name>
<value>see-data-pre-master-01:50470</value>
</property>
<property>
<name>dfs.https.port</name>
<value>50470</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>see-data-pre-master-01:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>false</value>
</property>
<property>
<name>fs.permissions.umask-mode</name>
<value>022</value>
</property>
<property>
<name>dfs.namenode.acls.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.client.use.legacy.blockreader</name>
<value>false</value>
</property>
<property>
<name>dfs.client.read.shortcircuit</name>
<value>false</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<property>
<name>dfs.client.read.shortcircuit.skip.checksum</name>
<value>false</value>
</property>
<property>
<name>dfs.client.domain.socket.data.traffic</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
</configuration>
hive-site.xml
<?xml version="1.0" encoding="UTF-8"?> <!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://see-data-pre-master-01:9083</value>
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>300</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.warehouse.subdir.inherit.perms</name>
<value>true</value>
</property>
<property>
<name>hive.enable.spark.execution.engine</name>
<value>false</value>
</property>
<property>
<name>hive.conf.restricted.list</name>
<value>hive.enable.spark.execution.engine</value>
</property>
<property>
<name>hive.auto.convert.join</name>
<value>true</value>
</property>
<property>
<name>hive.auto.convert.join.noconditionaltask.size</name>
<value>20971520</value>
</property>
<property>
<name>hive.optimize.bucketmapjoin.sortedmerge</name>
<value>false</value>
</property>
<property>
<name>hive.smbjoin.cache.rows</name>
<value>10000</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>-1</value>
</property>
<property>
<name>hive.exec.reducers.bytes.per.reducer</name>
<value>67108864</value>
</property>
<property>
<name>hive.exec.copyfile.maxsize</name>
<value>33554432</value>
</property>
<property>
<name>hive.exec.reducers.max</name>
<value>1099</value>
</property>
<property>
<name>hive.vectorized.groupby.checkinterval</name>
<value>4096</value>
</property>
<property>
<name>hive.vectorized.groupby.flush.percent</name>
<value>0.1</value>
</property>
<property>
<name>hive.compute.query.using.stats</name>
<value>false</value>
</property>
<property>
<name>hive.vectorized.execution.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.vectorized.execution.reduce.enabled</name>
<value>false</value>
</property>
<property>
<name>hive.merge.mapfiles</name>
<value>true</value>
</property>
<property>
<name>hive.merge.mapredfiles</name>
<value>false</value>
</property>
<property>
<name>hive.cbo.enable</name>
<value>false</value>
</property>
<property>
<name>hive.fetch.task.conversion</name>
<value>minimal</value>
</property>
<property>
<name>hive.fetch.task.conversion.threshold</name>
<value>268435456</value>
</property>
<property>
<name>hive.limit.pushdown.memory.usage</name>
<value>0.1</value>
</property>
<property>
<name>hive.merge.sparkfiles</name>
<value>true</value>
</property>
<property>
<name>hive.merge.smallfiles.avgsize</name>
<value>16777216</value>
</property>
<property>
<name>hive.merge.size.per.task</name>
<value>268435456</value>
</property>
<property>
<name>hive.optimize.reducededuplication</name>
<value>true</value>
</property>
<property>
<name>hive.optimize.reducededuplication.min.reducer</name>
<value>4</value>
</property>
<property>
<name>hive.map.aggr</name>
<value>true</value>
</property>
<property>
<name>hive.map.aggr.hash.percentmemory</name>
<value>0.5</value>
</property>
<property>
<name>hive.optimize.sort.dynamic.partition</name>
<value>false</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>268435456</value>
</property>
<property>
<name>spark.driver.memory</name>
<value>268435456</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>1</value>
</property>
<property>
<name>spark.yarn.driver.memoryOverhead</name>
<value>26</value>
</property>
<property>
<name>spark.yarn.executor.memoryOverhead</name>
<value>26</value>
</property>
<property>
<name>spark.dynamicAllocation.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.dynamicAllocation.initialExecutors</name>
<value>1</value>
</property>
<property>
<name>spark.dynamicAllocation.minExecutors</name>
<value>1</value>
</property>
<property>
<name>spark.dynamicAllocation.maxExecutors</name>
<value>2147483647</value>
</property>
<property>
<name>hive.metastore.execute.setugi</name>
<value>true</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>see-data-pre-master-01</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.zookeeper.namespace</name>
<value>hive_zookeeper_namespace_hive</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>see-data-pre-master-01</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hive.cluster.delegation.token.store.class</name>
<value>org.apache.hadoop.hive.thrift.MemoryTokenStore</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<property>
<name>hive.server2.use.SSL</name>
<value>false</value>
</property>
<property>
<name>spark.shuffle.service.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?> <!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>mapreduce.job.split.metainfo.maxsize</name>
<value>10000000</value>
</property>
<property>
<name>mapreduce.job.counters.max</name>
<value>120</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>false</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>BLOCK</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.DefaultCodec</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>zlib.compress.level</name>
<value>DEFAULT_COMPRESSION</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>64</value>
</property>
<property>
<name>mapreduce.map.sort.spill.percent</name>
<value>0.8</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>10</value>
</property>
<property>
<name>mapreduce.task.timeout</name>
<value>600000</value> </property>
<property>
<name>mapreduce.client.submit.file.replication</name>
<value>1</value>
</property>
<property>
<name>mapreduce.job.reduces</name>
<value>5</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.map.speculative</name>
<value>false</value>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>false</value>
</property>
<property>
<name>mapreduce.job.reduce.slowstart.completedmaps</name>
<value>0.8</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>see-data-pre-master-01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>see-data-pre-master-01:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.https.address</name>
<value>see-data-pre-master-01:19890</value>
</property>
<property>
<name>mapreduce.jobhistory.admin.address</name>
<value>see-data-pre-master-01:10033</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
<property>
<name>mapreduce.am.max-attempts</name>
<value>2</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>false</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Djava.net.preferIPv4Stack=true -Xmx825955249</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Djava.net.preferIPv4Stack=true</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Djava.net.preferIPv4Stack=true</value>
</property>
<property>
<name>yarn.app.mapreduce.am.admin.user.env</name>
<value>LD_LIBRARY_PATH=$HADOOP_COMMON_HOME/lib/native:$JAVA_LIBRARY_PATH</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>0</value>
</property>
<property>
<name>mapreduce.map.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>0</value>
</property>
<property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>mapreduce.job.heap.memory-mb.ratio</name>
<value>0.8</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH</value>
</property>
<property>
<name>mapreduce.admin.user.env</name>
<value>LD_LIBRARY_PATH=$HADOOP_COMMON_HOME/lib/native:$JAVA_LIBRARY_PATH</value>
</property>
<property>
<name>mapreduce.shuffle.max.connections</name>
<value>80</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?> <!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.admin.acl</name>
<value>*</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>see-data-pre-master-01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>see-data-pre-master-01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>see-data-pre-master-01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>see-data-pre-master-01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>see-data-pre-master-01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>see-data-pre-master-01:8090</value>
</property>
<property>
<name>yarn.resourcemanager.client.thread-count</name>
<value>50</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.client.thread-count</name>
<value>50</value>
</property>
<property>
<name>yarn.resourcemanager.admin.client.thread-count</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.increment-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3374</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.increment-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>8</value>
</property>
<property>
<name>yarn.resourcemanager.amliveliness-monitor.interval-ms</name>
<value>1000</value>
</property>
<property>
<name>yarn.am.liveness-monitor.expiry-interval-ms</name>
<value>600000</value>
</property>
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>2</value>
</property>
<property>
<name>yarn.resourcemanager.container.liveness-monitor.interval-ms</name>
<value>600000</value>
</property>
<property>
<name>yarn.resourcemanager.nm.liveness-monitor.interval-ms</name>
<value>1000</value>
</property>
<property>
<name>yarn.nm.liveness-monitor.expiry-interval-ms</name>
<value>600000</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.client.thread-count</name>
<value>50</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.sizebasedweight</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.assignmultiple</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.max-completed-applications</name>
<value>10000</value>
</property>
</configuration>
4. 在$KYLIN_HOME/conf/下的 kylin.properties 中追加以下设置
kylin.source.hive.beeline-shell=beeline
kylin.source.hive.beeline-params=-n hadoop --hiveconf hive.security.authorization.sqlstd.confwhitelist.append='mapreduce.job.*|dfs.*' -u jdbc:hive2://see-data-pre-master-01:10000
# 重要:这是通过beeline向集群A的Hive指定Kylin计算过程中产生的中间表存储的数据库
kylin.source.hive.database-for-flat-table=kylin
kylin.source.hive.redistribute-flat-table=true
kylin.storage.url=hbase
kylin.storage.hbase.cluster-fs=hdfs://test-data-master-1:8020
kylin.storage.hbase.namespace=kylin_prod
# 重要:这是集群B的zookeeper节点,Hbase要依赖zk,需要加上
kylin.env.zookeeper-connect-string=test-data-master-,test-data-slave-,test-data-slave-1
5. 配置环境变量
在安装Kylin的机器上配置 ~/.bashrc 文件,追加以下内容
# hadoop
export CONF_HOME=/home/hadoop/kylin/apache-kylin-2.4.-bin-cdh57/conf
export HBASE_CONF=$CONF_HOME
export HBASE_CONF_DIR=$CONF_HOME
export HADOOP_CONF_DIR=$CONF_HOME
export HIVE_CONF=$CONF_HOME
export HIVE_CONF_DIR=$CONF_HOME #added by Hive hcatalog
export HCAT_HOME=/opt/cloudera/parcels/CDH/lib/hive-hcatalog #add by KYLIN
export KYLIN_HOME=/home/hadoop/kylin/apache-kylin-2.4.-bin-cdh57
export PATH=$KYLIN_HOME/bin:$PATH
这个环境变量告诉Kylin不取本机的hadoop计算,重要!
编辑完后 source ~/.bashrc 以下让其生效!
6. 单服务验证以上配置是否正确
在集群B,安装Kylin的机器下执行以下操作以确定是否都指向了集群A
- 验证HDFS,以下的结果是集群A上的HDFS目录
[hadoop@test-data-slave- conf]$ hdfs dfs -ls /user/hive/warehouse/
Found items
drwxrwxrwt - hadoop hive -- : /user/hive/warehouse/kylin.db
drwxrwxrwt - superuser hive -- : /user/hive/warehouse/test_default
- 验证HIVE,打开HIVE CLI,是集群A的hive数据库
hive> show databases;
OK
default
kylin
Time taken: 1.78 seconds, Fetched: row(s)
- 验证YARN,Running列表里头的两台机器是集群A的
yarn node -list
-- ::, INFO [main] client.RMProxy (RMProxy.java:createRMProxy()) - Connecting to ResourceManager at see-data-pre-master-/10.5.8.10:
Total Nodes:
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
see-data-pre-slave-: RUNNING see-data-pre-slave-:
see-data-pre-master-: RUNNING see-data-pre-master-:
7.
hive上建立kylin数据库,用作存储建CUBE时的临时文件
hbase上建立namespace ==> kylin_prod,专门存储kylin cube表
8. 到$KYLIN_HOME下运行Kylin
./kylin.sh start
9. 打开Kylin UI,执行demo建cube ,到集群A的CDH Yarn页面查看建CUBE的MR任务
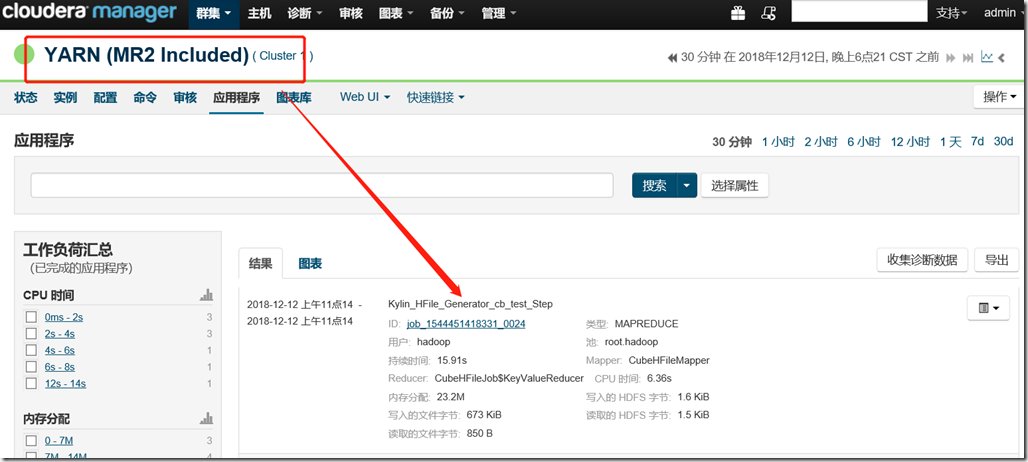
在Kylin UI 中查看CUBE保存后的Kylin表
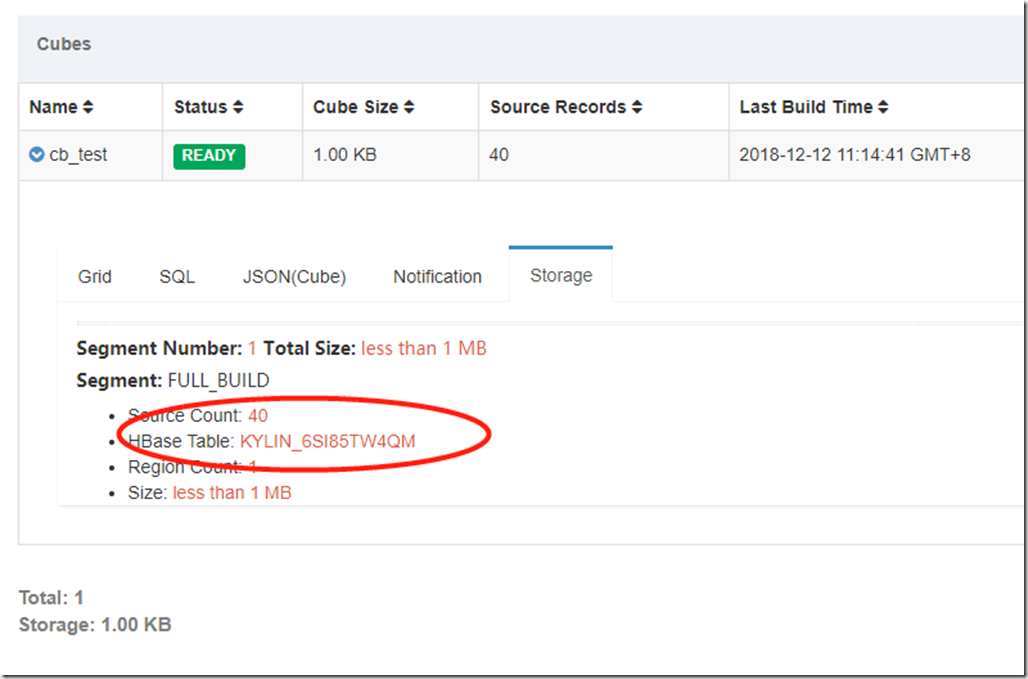
到集群B的Hbase中验证
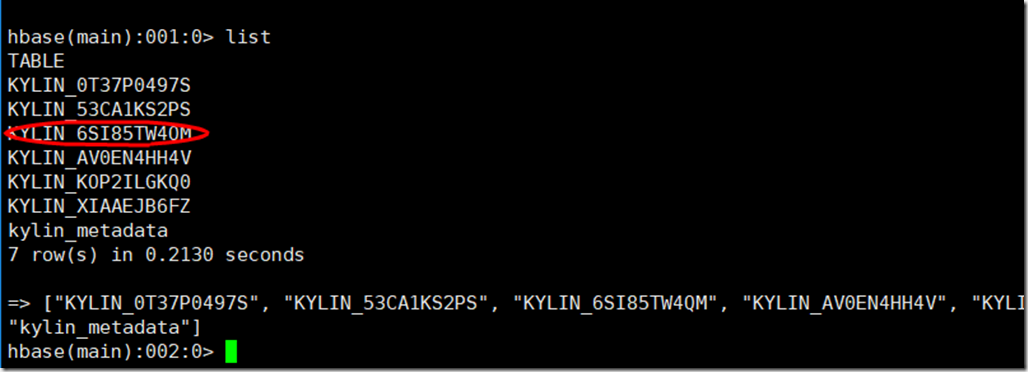
至此搭建Kylin读写分离完成。
基于CDH,部署Apache Kylin读写分离的更多相关文章
- 基于 EntityFramework 的数据库主从读写分离服务插件
基于 EntityFramework 的数据库主从读写分离服务插件 1. 版本信息和源码 1.1 版本信息 v1.01 beta(2015-04-07),基于 EF 6.1 开发,支持 EF 6.1 ...
- 基于 EntityFramework 的数据库主从读写分离架构 - 目录
基于 EntityFramework 的数据库主从读写分离架构 回到目录,完整代码请查看(https://github.com/cjw0511/NDF.Infrastructure)中的目 ...
- 基于 EntityFramework 的数据库主从读写分离架构(2)- 改进配置和添加事务支持
回到目录,完整代码请查看(https://github.com/cjw0511/NDF.Infrastructure)中的目录: src\ NDF.Data.EntityFramew ...
- 基于 EntityFramework 的数据库主从读写分离架构(1) - 原理概述和基本功能实现
回到目录,完整代码请查看(https://github.com/cjw0511/NDF.Infrastructure)中的目录: src\ NDF.Data.EntityFramew ...
- 在项目中部署redis的读写分离架构(包含节点间认证口令)
#### 在项目中部署redis的读写分离架构(包含节点间认证口令) ##### 1.配置过程 --- 1.此前就是已经将redis在系统中已经安装好了,redis utils目录下,有个redis ...
- linux下mysql基于mycat做主从复制和读写分离之基础篇
Linux下mysql基于mycat实现主从复制和读写分离1.基础设施 两台虚拟机:172.20.79.232(主) 172.20.79.233(从) 1.1软件设施 mysql5.6.39 , my ...
- MyCAT部署及实现读写分离(转)
MyCAT是mysql中间件,前身是阿里大名鼎鼎的Cobar,Cobar在开源了一段时间后,不了了之.于是MyCAT扛起了这面大旗,在大数据时代,其重要性愈发彰显.这篇文章主要是MyCAT的入门部署. ...
- 利用mycat实现基于mysql5.5主从复制的读写分离
整体步骤: 1.准备好两台服务器,一台作为主数据库服务器,一台作为从服务器,并安装好mysql数据库,此处略 2.配置好主从同步 3.下载JDK配置mycat依赖的JAVA环境,mycat采用java ...
- 基于Amoba实现mysql主从读写分离
一.Amoeba简介 Amoeba是一个以MySQL为底层数据存储,并对应用提供MySQL协议接口的proxy.它集中地响应应用的请求,依据用户事先设置的规则,将SQL请求发送到特 ...
随机推荐
- ASLR pe 分析
ASLR 转:http://www.cnblogs.com/dliv3/p/6411814.html 3ks @author:dlive 微软从windows vista/windows server ...
- Redis—初探Redis
一.什么是Redis? 学习Redis最好的是看官网了,下面是Redis的官网对Redis的介绍 可见,Redis是一个内存存储的数据结构服务器,可以用作数据库.缓存等.支持的数据结构也很丰富,有字符 ...
- USB描述符【整理】
USB描述符 USB描述符信息存储在USB设备中,在枚举过程中,USB主机会向USB设备发送GetDescriptor请求,USB设备在收到这个请求之后,会将USB描述符信息返回给USB主机,USB主 ...
- 新一代的USB 3.0传输规格
通用序列总线(USB) 从1996问世以来,一统个人电脑外部连接界面,且延伸至各式消费性产品,早已成为现代人生活的一部分.2000年发表的USB 2.0 High-speed规格,提供了480Mbps ...
- URAL题解三
URAL题解三 URAL 1045 题目描述:有\(n\)个机场,\(n-1\)条航线,任意两个机场有且只有一种方案联通.现有两个恐怖分子从\(m\)号机场出发,第一个人在机场安装炸弹,乘坐飞机,引爆 ...
- 《深入理解Java虚拟机》笔记--第二章、Java内存区域与内存溢出异常
Java程序员把内存的控制权交给了Java虚拟机.在Java虚拟机内存管理机制的帮助下,程序员不再需要为每一个new操作写对应的delete/free代码,而且不容易出现内存泄露和溢出. 虚拟机在执行 ...
- ssh -o 常用选项
ssh -o ConnectTimeout=3 -o ConnectionAttempts=5 -o PasswordAuthentication=no -o StrictHostKeyCheckin ...
- git - git命令中文显示乱码
使用git add添加要提交的文件的时候,如果文件名是中文,会显示形如897\232\350\256...的乱码,解决办法: git config --global core.quotepath ...
- 使用 Python 的 sounddevice 包录制系统声音
博客中的文章均为meelo原创,请务必以链接形式注明本文地址 sounddevice是一个与Numpy兼容的录音以及播放声音的包. 安装sounddevice包 直接通过pip就能安装. pip in ...
- Java虚拟机四:垃圾回收算法与垃圾收集器
在Java运行时的几个数据区域中,程序计数器,虚拟机栈,本地方法栈3个区域随着线程而生,随线程而灭,因此这几个区域的内存分配和回收具有确定性,不需要过多考虑垃圾回收问题,因为方法结束或者线程结束时,内 ...