java集合类学习笔记之HashMap
1、简述
HashMap是java语言中非常典型的数据结构,也是我们平常用的最多的的集合类之一。它的底层是通过一个单向链表(Node<k,v>)数组(也称之为桶bucket,数组的长度也叫做桶深)来实现的。它内部有以下成员变量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 内部数组的默认初始长度
static final int MAXIMUM_CAPACITY = 1 << 30; 内部数组最大的长度为2^30
static final float DEFAULT_LOAD_FACTOR = 0.75f; 加载因子,每当数组里面的元素达到这个百分比的时候内部的数组进行扩容
transient Node<K,V>[] table; hashMap内部用来保存数据的链表数组
transient int size; hashMap内存放的元素的个数
int threshold; 每次内部数组达到这个大小是需要扩容,它等于容量乘以加载因子
transient int modCount; HashMap实例结构修改的次数,当多个线程同时修改它的结构时就可能会导致每个线程中的modeCount的值不一样,此时就会抛出异常,所以说HashMap是线程不安全的
2、实现
1、数据结构:
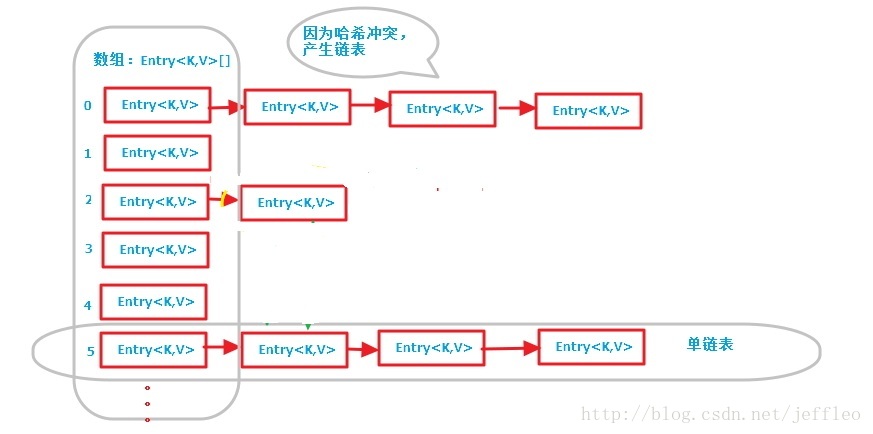
2、构造方法:
HashMap一共提供了一下四种构造方法:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
在实例化HashMap实例的时候我们可以根据不同的业务需求调用不同的构造方法。第一种构造方法适用于能够提前预知hashMap中存放元素的准确数量,我们可以指定加载因子和初始容量(因为内部数组每次扩容的代价是很大的,都是直接将容量翻倍)。第二种构造方法适用于能大致知道内部元素的数量,只能指定初始容量,第三种构造方法也是我们平常用的最多的,适用于存放位置数量。第四种适用于需要将一个一直Map数据拷贝到当前map中。(以上纯属个人理解,不喜勿喷)
3、HashMap操作:
增加操作(V put(K key, V value) )
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; //hashMap初始化的时候内部数组长度为0,第一次put操作的时候才设置成默认的容量
if ((p = tab[i = (n - 1) & hash]) == null) //根据key的hash值和数组长度的与操作获取对应的下标,如果数组该下标位置为空则直接new一个新的Node放到该位置
tab[i] = newNode(hash, key, value, null);
else { //根据key的hash值和数组长度的与操作获取对应的下标,此时该位置已经有元素(即产生了hash冲突),接下来是产生hash冲突的解决办法
Node<K,V> e; K k;
/**
* 判断key的hash位置的元素的key的hash值和新put的元素的key的hash值是否相等,如果相等的直接将之前位置的值赋给新的Node<k,v>节点
*/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) //判断之前位置的元素是不是TreeNode的子类,此处和hashMap无关可以暂时不看
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
/**
* 1、以下操作是当产生hash冲突之后,判断产生冲突的Node<k,v>节点的下一个节点是否为空,为空说明是第一次产生hash冲突,
* 直接将新put的元素放在产生冲突的元素后面(每个hash值对应的都是一个链表)
* 2、当产生冲突的元素下个节点不为空,说明不是第一次产生hash冲突,此时再去判断产生冲突的下一个节点与新put的元素可以的hash值是否相等,
* 相等直接break,相当于新put的元素已经存在,此时不用做任何操作
* 不相等的时候将冲突节点下一个节点的值赋给自己,一直循环直到获取到产生hash冲突的位置的链表的末尾,并将新插入的元素放到链表的末尾
*/
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); //当产生hash冲突的值比较多,即链表过长时,会将链表变成红黑树进行存储
break;
}
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
/**
* hashMap 的 e值肯定是null,这里的操作是LinkedHashMap相关,暂时忽略
*/
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); //这里主要用于判断LinkedHashMap是否是按照访问顺序排序的
return oldValue;
}
}
++modCount; //此时实例结构发生改变,内部结构改变计数器数量+1
if (++size > threshold) //判断put完之后内部数组是否需要扩容
resize();
afterNodeInsertion(evict); //这里是用来判断LinkedHashMap是否需要删除最老元素
return null;
}
从以上代码可以看出,当产生hash冲突的时候对hashMap的效率大大降低,所以当使用自定义类当做key值的时候一定要重写hashcode方法,尽量避免hash冲突,
关于java位运算符可以参考:java学习笔记之位运算符
查询操作(V get(Object key)):
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { //先判断key的hash对应数组下标的位置有没有值
if (first.hash == hash && // 判断hash值对应的链表第一个节点的key值可当前查询的可以是不是同一个对象(当没有产生hash冲突的时候就是第一个)
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode) //LinkedHashMap操作相关,暂时忽略
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do { //此时是之前插入的时候产生了hash冲突,此时遍历hash值对应的链表,知道找到当前查询的key对应的节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
删除操作(V remove(Object key))
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
remove的操作步骤基本和put操作类似,在这里就不再一一分析了,有写的不明白的地方可以私信我一起讨论下
总结:
HashMap的实现是通过在内部定义了一个链表数组,数组的每一个位置的元素都是一个单向链表,当往hashMap中put值产生hash冲突的时候,会将新的是放到key的hash值对应数组位置的链表的末尾,当我们在使用过程中用一个引用变量类型当做key值的时候,尽量重写引用类型的hashcode方法使用更优的hash算法,避免产生过多的hash冲突,因为产生hash冲突的时候对hashmap的性能会产生很大的影响。此外在使用hashMap的时候在能预知最终存放的数组的时候可以在初始化的时候指定HashMap内置数组的初始长度,避免内部数组扩容的次数过多,因为内部数组扩容每次都是直接将长度翻倍,这样的操作代价是很大的
java集合类学习笔记之HashMap的更多相关文章
- java集合类学习笔记之LinkedHashMap
1.简述 LinkedHashMap是HashMap的子类,他们最大的不同是,HashMap内部维护的是一个单向的链表数组,而LinkedHashMap内部维护的是一个双向的链表数组.HashMap是 ...
- java集合类学习笔记之ArrayList
1.简述 ArrayList底层的实现是使用了数组保存所有的数据,所有的操作本质上是对数组的操作,每一个ArrayList实例都有一个默认的容量(数组的大小,默认是10),随着 对ArrayList不 ...
- Java集合类学习笔记2
二,具体的集合 集合类型 描述 ArrayList 一种可以动态增长和缩减的索引序列 LinkedList 一种可以在任何位置进行高效地插入和删除操作的有序序列 ArrayDeque 一种用循环数组实 ...
- java集合类学习笔记1
一.集合的接口 java集合类库也将接口与实现相分离.首先看一下大家都熟悉的数据结构-队列是如何分离的.队列接口指出可以在队列的尾部添加元素,在队列的头部删除元素,并且可以查找队列中元素的个数.当需要 ...
- Java集合类学习笔记(各种Map实现类的性能分析)
HashMap和Hashtable的实现机制几乎一样,但由于Hashtable是一个古老的.线程安全的集合,因此HashMap通常比Hashtable要快. TreeMap比HashMap和Hasht ...
- Java集合类学习笔记(Map集合)
Map用于保存具有映射关系的数据,因此Map集合里保存着两组数据,一组用于保存Map的key,一组用于保存key所对应的value. Map的key不允许重复. HashMap和Hashtable都是 ...
- Java集合类学习笔记(Set集合)
Set集合不允许包含相同的元素,如果试图把两个相同的元素加入同一个Set集合中,则添加操作失败,add()方法返回false,且新元素不会被加入. HashSet类的特点: 不能保证元素的排列顺序,顺 ...
- Java集合类学习笔记(各种线性表性能分析)
ArrayList.LinkedList是线性表的两种典型实现:基于数组的线性表和基于链的线性表. Queue代表了队列,Deque代表了双端队列. 一般来说,由于数组以一块连续内存区来保存所有的数组 ...
- Java集合类学习笔记(Queue集合)
Queue集合用于模拟队列(先进先出:FIFO)这种数据类型. Queue有一个Deque接口,代表一个"双端队列",双端队列可以同时从两端来添加.删除元素,因此Deque的实现类 ...
随机推荐
- Kibana(elasticsearch操作工具)的安装
在安装完es集群的基础上 1.创建文件夹并赋权 # 使用root进行操作 mkdir -p /export/data/kibana mkdir -p /export/logs/kibana # 赋权给 ...
- Spring学习笔记(四)--MVC概述
一. 飞机 最近马来西亚航空370号班机事故闹得沸沸扬扬,情节整的扑朔迷离,连我在钻研springMVC平和的心情都间接的受到了影响.正当我在想这个MVC的处理过程可以怎样得到更好的理解呢?灰机,灰机 ...
- 每个内存大小:sudo dmidecode -t memory |grep -A16 "Memory Device$" |grep "Size:"
CPU: 型号:grep "model name" /proc/cpuinfo |awk -F ':' '{print $NF}' 数量:lscpu |grep "CPU ...
- Opencv Convex Hull (凸包)
#include <iostream>#include <opencv2/opencv.hpp> using namespace std;using namespace cv; ...
- 详解Python垃圾回收机制
http://www.qytang.com/cn/list/28/417.htmhttp://www.qytang.com/cn/list/28/416.htmhttp://ww 引用计数 Pytho ...
- Python爬虫实战三之实现山东大学无线网络掉线自动重连
综述 最近山大软件园校区QLSC_STU无线网掉线掉的厉害,连上之后平均十分钟左右掉线一次,很是让人心烦,还能不能愉快地上自习了?能忍吗?反正我是不能忍了,嗯,自己动手,丰衣足食!写个程序解决掉它! ...
- Photo4
Story: 我手捧玫瑰,一个人,走在桥上.桥下是波澜壮阔的大海,一不小心,我就有失足的危险.海鸟的低鸣在我耳际盘旋着,浪汹涌,仿佛要把我吞噬掉.你也许奇怪,为何我一人手捧玫瑰走在桥上.只因,女骑从来 ...
- 在IE9中检查up6.2配置
1.按F12,打开调试模式 2.打开脚本选项卡 说明:在脚本选项卡中可看到IE加载的脚本信息是否正确.因为IE有缓存,导致脚本有时不是最新的. 3.打开脚本,up6.js 4. ...
- 编写高质量代码改善C#程序的157个建议——建议75:警惕线程不会立即启动
建议75:警惕线程不会立即启动 现代的大多数操作系统都不是一个实时的操作系统,Windows系统也是如此.所以,不能奢望我们的线程能够立即启动.Windows内部会实现特殊的算法以进行线程之间的调度, ...
- sql五大类中的 DTL 数据事务语言
DTL,数据事务语言 事务的定义:就是指一组相关的SQL操作,我们所有的操作都是事务中的. 注意:在数据库中,执行业务的基本单位是[事务],不是以某一条SQL. 数据库在默认情况下,事务是都打开 ...