RDD缓存学习
首先实现rdd缓存
准备了500M的数据 10份,每份 100万条,存在hdfs 中通过sc.textFile方法读取
val rdd1 = sc.textFile("hdfs://mini1:9000/spark/input/visitlog").cache
在启动spark集群模式时分配内存2g,第一次分配1g 只缓存了40% 当数据需要的内存大于实际的内存时spark会尽力的缓存
然后调用cache方法
rdd1.count
第二次调用rdd的count方法就显示出差距了
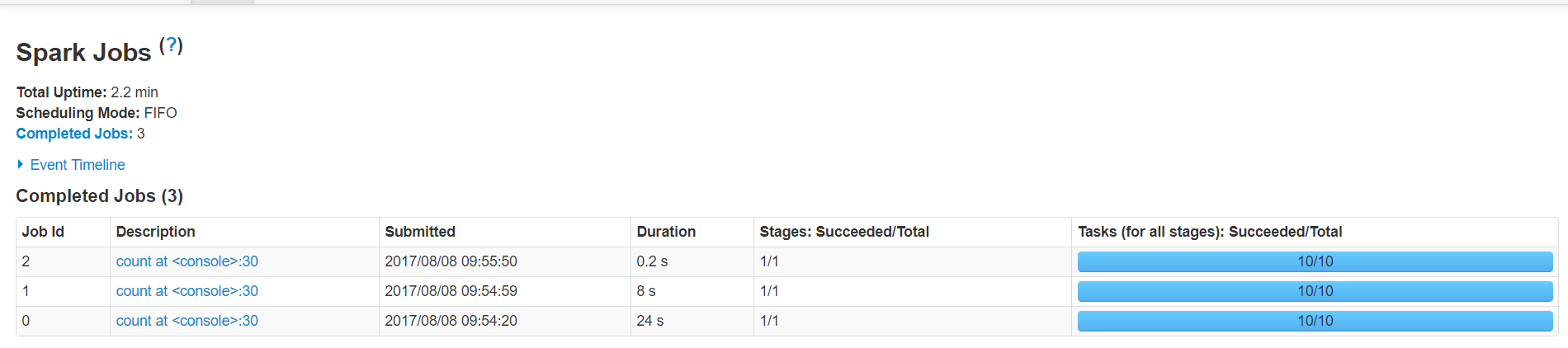
默认缓存策略是memory_only
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
其他的缓存策略
object StorageLevel {
//不缓存
val NONE = new StorageLevel(false, false, false, false)
//只往磁盘中缓存
val DISK_ONLY = new StorageLevel(true, false, false, false)
//磁盘中缓存两份
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, )
//放在内存中
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
//内存中保存两份,多个机器报存
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, )
//报存一份到内存,并且把数据序列化,序列化之后数据占用内存变小,
//但是序列化时需要消耗时间,时间换空间
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
//
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, )
//内存和磁盘都保存
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, )
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
//内存和磁盘都保存 序列化两份
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, )
val OFF_HEAP = new StorageLevel(false, false, true, false)
RDD缓存学习的更多相关文章
- spring boot guava cache 缓存学习
http://blog.csdn.net/hy245120020/article/details/78065676 ****************************************** ...
- TimesTen 应用层数据库缓存学习:4. 仅仅读缓存
在运行本文样例前.首先先运行TimesTen 应用层数据库缓存学习:2. 环境准备中的操作. Read-only Cache Group的概念 仅仅读缓存组例如以下图: 仅仅读缓存组(Read-Onl ...
- RDD缓存
RDD的缓存 Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存数据集.当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他 ...
- Spark RDD设计学习笔记
本文档是学习RDD经典论文<Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster ...
- Android缓存学习入门
本文主要包括以下内容 利用LruCache实现内存缓存 利用DiskLruCache实现磁盘缓存 LruCache与DiskLruCache结合实例 利用了缓存机制的瀑布流实例 内存缓存的实现 pub ...
- memcache/redis 缓存学习笔记
0.redis和memcache的区别 a.redis可以存储除了string之外的对象,如list,hash等 b.服务器宕机以后,redis会把内存的数据持久化到磁盘上,而memcache则不会 ...
- RDD缓存策略
Spark支持将数据集放置在集群的缓存中,以便于数据重用. Spark缓存策略对应的类: class StorageLevel private( private var useDisk_ : Bool ...
- C# 缓存学习第一天
缓存应用目的:缓存主要是为了提高数据的读取速度.因为服务器和应用客户端之间存在着流量的瓶颈,所以读取大容量数据时,使用缓存来直接为客户端服务,可以减少客户端与服务器端的数据交互,从而大大提高程序的性能 ...
- CPU缓存学习及C6678缓存使用总结(知识归纳)
作者注: 1.本篇博客内容是本人在学习cpu缓存原理时进行的学习总结,参考了多处相关资源(书籍,视频,知乎回答等),参考出处标注在内容最后. 2.由于本篇内容的编辑工作在印象笔记完成,输出的PDF文件 ...
随机推荐
- Hadoop-2.2.0中文文档—— 从Hadoop 1.x 迁移至 Hadoop 2.x
简单介绍 本文档对从 Apache Hadoop 1.x 迁移他们的Apache Hadoop MapReduce 应用到 Apache Hadoop 2.x 的用户提供了一些信息. 在 Apache ...
- JavaScript中字符串的match与replace方法
1.match方法 match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配. match()方法的返回值为:存放匹配结果的数组. 2.replace方法 replace() 方 ...
- $.post以后就取不到$(this)节点解决方法【转】
在作用域开头最好把以后要用的this指针存起来 a.click(function(){ var $this=$(this); $.get("/a").always( $this.v ...
- Autofac3 在MVC4中的运用原理
这是一种新的开发模式,注入开发模式,或者叫它IOC模式,说起IOC你可以这样去理解它,它为你的某个实现流出一个注入点,你生产的对象,可以根据你之前的配置进行组合. IOC全称是Inversion o ...
- 【故障处理141119】一次数据库不繁忙时一条sql语句2个运行计划导致业务超时的故障处理
1,故障描写叙述: 一条select有两个运行计划.在sqlplus中运行选择好的运行计划.仅仅要40毫秒.而在程序中运行选择了差的运行计划,要1分23秒左右,导致前台业务超时报错. 2.故障解决: ...
- ubuntu——printk()函数总结,关于日志文件
我们在使用printk()函数中使用日志级别为的是使编程人员在编程过程中自定义地进行信息的输出,更加容易地掌握系统当前的状况. 对程序的调试起到了很重要的作用. (下文中的日志级别和控制台日志控制级别 ...
- 基于Ant Design UI框架的React项目
概述 这款基于React开发的UI框架,界面非常简洁美观,在这篇文章中我主要为大家介绍一下如何用Ant开始搭建React项目 详细 代码下载:http://www.demodashi.com/demo ...
- Linux中内存挂载到目录下
[日期:2012-11-14] /dev/shm是linux下的一块共享内存结构.默认大小是真实内存的一半.它用来存储进程间通讯时的一些共享数据结构.在物理内存足够时,会在内存中进行数据交换,如果 ...
- 网页字体生成工具fontello firefox下无效,未跨域,研究两天得出解决办法
fontello是一个非常好的web font生成工具,但是在使用过程中发现生成的字体在firefox下死活渲染不出来,只有chrome可以正常渲染,字体文件和页面在同域下. 试过各种办法,最后发现一 ...
- MySQL主从不一致情形与解决方法
参考:https://blog.csdn.net/hardworking0323/article/details/81046408 https://blog.csdn.net/lijingkuan/a ...