python是如何进行内存管理的?
Python内存管理机制
Python内存管理机制主要包括以下三个方面:
- 引用计数机制
- 垃圾回收机制
- 内存池机制
引用计数
举个例子说明引用是什么:
- 1
如上为一个简单的赋值语句,1就是对象,a就是引用,引用a指向对象1。
同理:
- 1
b也是对象1的引用。
通过内置函数id()返回对象的地址。
- 1
- 2
当我们创建多个等于1的引用时,实际上是让所有这些引用指向同一个对象。为了检验两个引用指向同一个对象,我们可以用is关键字。is用于判断两个引用所指向的对象是否相同。
- 1
在Python中,整数和短小的字符,Python都会缓存这些对象,以便重复使用。赋值语句,只是创造了新的引用,而不是对象本身。长的字符串和其它对象可以有多个相同的对象,可以使用赋值语句创建出新的对象。每个对象都有存有指向该对象的引用总数,即引用计数(reference count)。
可以使用sys.getrefcount()获得引用计数,需要注意的是,当使用某个引用作为参数,传递给getrefcount()时,参数实际上创建了一个临时的引用。因此,getrefcount()所得到的结果,会比期望的多1。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
引用计数增加
1.对象被创建:x=4
2.另外的别人被创建:y=x
3.被作为参数传递给函数:foo(x)
4.作为容器对象的一个元素:a=[1, x, ‘33’]引用计数减少
1.一个本地引用离开了它的作用域。比如上面的foo(x)函数结束时,x指向的对象引用减1。
2.对象的别名被显式的销毁:del x ;或者del y
3.对象的一个别名被赋值给其他对象:x=789
4.对象从一个窗口对象中移除:myList.remove(x)
5.窗口对象本身被销毁:del myList,或者窗口对象本身离开了作用域。
垃圾回收
- 引用计数
引用计数也是一种垃圾收集机制,而且也是一种最直观,最简单的垃圾收集技术。当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了。比如某个新建对象,它被分配给某个引用,对象的引用计数变为1。如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。
不过如果出现循环引用的话,引用计数机制就不再起有效的作用了
- 1
- 2
- 3
- 4
- 5
- 6
循环引用可以使一组对象的引用计数不为0,然而这些对象实际上并没有被任何外部对象所引用,它们之间只是相互引用。这意味着不会再有人使用这组对象,应该回收这组对象所占用的内存空间,然后由于相互引用的存在,每一个对象的引用计数都不为0,因此这些对象所占用的内存永远不会被释放。
Python又引入了其他的垃圾收集机制来弥补引用计数的缺陷:“标记-清除“,“分代回收”两种收集技术。
标记清除
如果两个对象的引用计数都为1,但是仅仅存在他们之间的循环引用,那么这两个对象都是需要被回收的,也就是说,它们的引用计数虽然表现为非0,但实际上有效的引用计数为0。所以先将循环引用摘掉,就会得出这两个对象的有效计数。
在实际操作中,并不改动真实的引用计数,而是将集合中对象的引用计数复制一份副本,改动该对象引用的副本。对于副本做任何的改动,都不会影响到对象生命周期的维护。
这个计数副本的唯一作用是寻找root object集合(该集合中的对象是不能被回收的)。当成功寻找到root object集合之后,首先将现在的内存链表一分为二,一条链表中维护root object集合,成为root链表,而另外一条链表中维护剩下的对象,成为unreachable链表。之所以要剖成两个链表,是基于这样的一种考虑:现在的unreachable可能存在被root链表中的对象,直接或间接引用的对象,这些对象是不能被回收的,一旦在标记的过程中,发现这样的对象,就将其从unreachable链表中移到root链表中;当完成标记后,unreachable链表中剩下的所有对象就是名副其实的垃圾对象了,接下来的垃圾回收只需限制在unreachable链表中即可。分代回收
从前面“标记-清除”这样的垃圾收集机制来看,这种垃圾收集机制所带来的额外操作实际上与系统中总的内存块的数量是相关的,当需要回收的内存块越多时,垃圾检测带来的额外操作就越多,而垃圾回收带来的额外操作就越少;反之,当需回收的内存块越少时,垃圾检测就将比垃圾回收带来更少的额外操作。
举个例子来说明:
当某些内存块M经过了3次垃圾收集的清洗之后还存活时,我们就将内存块M划到一个集合A中去,而新分配的内存都划分到集合B中去。当垃圾收集开始工作时,大多数情况都只对集合B进行垃圾回收,而对集合A进行垃圾回收要隔相当长一段时间后才进行,这就使得垃圾收集机制需要处理的内存少了,效率自然就提高了。在这个过程中,集合B中的某些内存块由于存活时间长而会被转移到集合A中,当然,集合A中实际上也存在一些垃圾,这些垃圾的回收会因为这种分代的机制而被延迟。
内存池
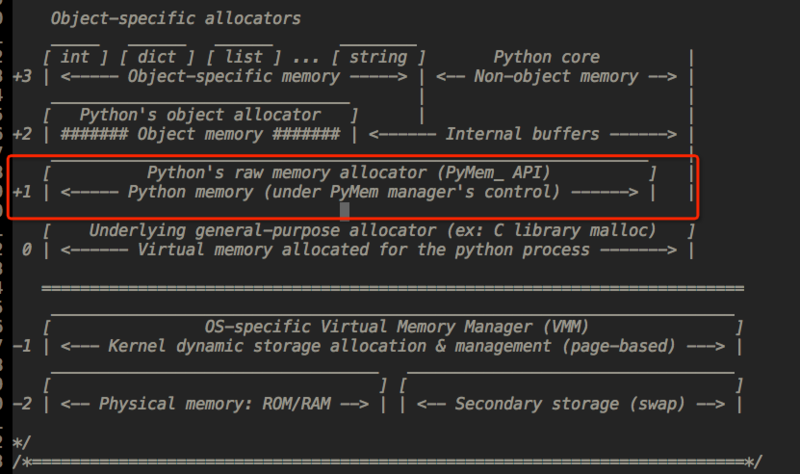
- Python的内存机制呈现金字塔形状,-1,-2层主要有操作系统进行操作;
- 第0层是C中的malloc,free等内存分配和释放函数进行操作;
- 第1层和第2层是内存池,有Python的接口函数PyMem_Malloc函数实现,当对象小于256K时有该层直接分配内存;
- 第3层是最上层,也就是我们对Python对象的直接操作;
Python在运行期间会大量地执行malloc和free的操作,频繁地在用户态和核心态之间进行切换,这将严重影响Python的执行效率。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
Python内部默认的小块内存与大块内存的分界点定在256个字节,当申请的内存小于256字节时,PyObject_Malloc会在内存池中申请内存;当申请的内存大于256字节时,PyObject_Malloc的行为将蜕化为malloc的行为。当然,通过修改Python源代码,我们可以改变这个默认值,从而改变Python的默认内存管理行为。
intro
上面是我结合书中的讲解,把它提到的一些概念用这个图都表达了出来。当然也可以说,我把书中的几张图合成了一张。
其实如果你去看python的源代码,在Objects/obmalloc.c这个文件中,对python是怎么维护内存的有详细的讲解。
概念
arena
这个区域是从堆内存里面直接malloc出来的,每个是256KB。
pool
针对malloc出来的arena,我们会对它进行分割,pool的大小是4K字节。至于为什么是4K字节,书中说这个是因为现在的操作系统大都是以4KB为大小做了内存页的管理单位,把我们的pool的大小也就设为了4KB。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
从上面的代码可以看到,只有对象大小在512字节以内的才会走到我们现在要讨论的这个分配系统,而大于512字节的,则直接走malloc了。
这里的设置跟书中提到的256字节的限制是不同的,可能在不同版本中,这个值得到了修正。
对于usedpool,它里面所维护的都是正在使用的pool,用代码中的话来说
- 在它里面的pool至少有一个block是被分配的
- 在它里面的pool至少有一个block是没有被分配的
那么那些被分配满block的pool去哪里了呢?它没有在这个usedpool中,它们在堆中处于游离状态。
而那些空的pool,则将它们返回给arena的freepools,由arena继续管理。
当arena里面全都是空pool的时候,这个arena就可以被释放掉了,arena的释放是通过free来完成的。
需要特殊说明的是,在上图中,pool左边我特意画了一块空白的空间出来,这个在书中是没有的,因为根据我的理解和读代码所得,每个pool都带有它自己的管理结构pool_header,也就是这个pool的metadata,它的定义我也在图中写出来了。它里面维护着这个pool中的一些信息,以及一些变量用来在这个pool中进行block分配。
block
有了pool之后,我们就可以在pool中划分出我们的block来了,但是我们在使用python过程中,对象的大小千奇百怪,为了内能适应不同的对象大小要求,python内部,采用了类似于malloc管理内存的方法,针对于每一个大小的对象,我们都会有一个pool与它对应。这要就有了上图中右边的这个结构。
这个结构是为了在分配过程中快速找到相对应的pool的一个结构,它可以在O(1)的时间分配所需要的内存。
usedpools
注意右边这个usedpool的全局变量,从概念上来看,它应该保存的是pool_header的前后关系,但是在在代码的实现中,里面实际上只是保存了pool_header里面的nextpool和prevpool的信息。为什么要这么做,在源代码里作者也给出了答案,这个结构需要经常的变动,如果把pool_header的信息全都放进去的话,会有一些空间上的浪费,使得cpu不能一次把整个结构load到cpu cache中去,或者说是cache line中去。为了防止这种情况的发生,加快对这个结构的访问,才做了这个优化。
pool中的freeblock
下面说说在看代码的过程中,我所遇到的一个问题,通过这个问题更深的了解了在pool中,block的分配是如何进行的。
- 1
- 2
- 3
- 4
- 5
在看到代码的时候,经常看到*(block **)bp,从代码的上下文来看,这个就是讲pool->freeblock指向下一个freeblock,但是简单的这个指针操作真的就能完成了嘛?
bp本来就是一个block指针,现在把它强转成block指针的指针,也就是说强转成一个指向block指针数组的的指针(简单这么理解),然后再解引用,相当于取这个数组的第一个元素(一个block的指针),这个就是我们下一个freeblock了?注意这里的block实际上是一个8位整型的别名。这里很是疑惑,于是转过头去看pool初始化的地方的代码。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
在此看到代码注释1的时候,就明白了,初始化的时候,就使用了freeblock的第一个block指针,也就是说每个block的第一个指针大小(在32位机上就是第一个32位,在64位机上就是第一个64位)是用来存放下一个block的内存地址的。注意这里最开始并没有把整个pool都分割完,只是用了最前面两个block,然后freeblock以NULL结尾。那么当我们将要分配第三块block时,会发生什么呢?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这里的pool实际上就上面我说的pool_header,通过它里面nextoffset的协助,我们继续划出了一块block,同时将freeblock的next置为NULL。
这里就得到证实,在分配block的时候,的确是使用了block的第一个32/64位做了连接这个链表的线索。当然如果想进一步证实,可以自己编译一个python的debug版本,调试一下看看,这里我就先不做了。(哎,又偷懒了)
剩下的问题
- 上面只是介绍了分配和释放对象大小小于512字节的情况,但是大于512字节的要怎么维护的呢?
- 比如一个list对象,刚开始的时候是比较小的,但是随着计算的增加,它是有可能超过512字节的,那么大小超过后会怎么处理呢?
转自:https://blog.csdn.net/alertbear/article/details/50808178
https://blog.csdn.net/u011801189/article/details/54848340
python是如何进行内存管理的?的更多相关文章
- <Python基础>python是如何进行内存管理的
.Python 是如何进行内存管理的?答:从三个方面来说,一对象的引用计数机制,二垃圾回收机制,三内存池机制⒈对象的引用计数机制Python 内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用 ...
- python是如何进行内存管理的
Python引入了一个机制:引用计数. python内部使用引用计数,来保持追踪内存中的对象,Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时, ...
- Python是如何进行内存管理
三个方面:一对象的引用计数机制,二垃圾回收机制,三内存池机制 一.对象的引用计数机制 Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数. 引用计数增加的情况: 1,一个对象分 ...
- python面试题之Python是如何进行内存管理的
python内部使用引用计数,来保持追踪内存中的对象,Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它被垃圾回收. ...
- Python深入学习之内存管理
语言的内存管理是语言设计的一个重要方面.它是决定语言性能的重要因素.无论是C语言的手工管理,还是Java的垃圾回收,都成为语言最重要的特征.这里以Python语言为例子,说明一门动态类型的.面向对象的 ...
- 深入Python底层,谈谈内存管理机制
说到内存管理,就先说一下垃圾回收吧.垃圾回收是Python,Java等语言管理内存的一种方式,说的直白些,就是清除无用的垃圾对象.C语言及C++中,需要通过malloc来进行内存的申请,通过free而 ...
- Python 是如何进行内存管理的?python 的程序会内存泄露吗?说说有没有什么方面防止或检测内存泄露?
Python GC主要使用 引用计数 来跟踪和回收垃圾.在引用计数的基础上,通过“标记-清除”解决容器对象可能产生的循环引用问题.通过分代 以空间换时间的方法提高垃圾回收效率 引用计数: 每个对象中都 ...
- Python深入:01内存管理
在Python中,一切都是指针. 一:对象三特性 所有的Python对象都有三个特性:身份,类型和值. 身份:每一个对象都有一个唯一的身份标识,任何对象 ...
- python的内存管理机制
先从较浅的层面来说,Python的内存管理机制可以从三个方面来讲 (1)垃圾回收 (2)引用计数 (3)内存池机制 一.垃圾回收: python不像C++,Java等语言一样,他们可以不用事先声明变量 ...
随机推荐
- [BZOJ4653][NOI2016]区间 贪心+线段树
4653: [Noi2016]区间 Time Limit: 60 Sec Memory Limit: 256 MB Description 在数轴上有 n个闭区间 [l1,r1],[l2,r2],. ...
- 【CodeChef-SPCLN】Cleaning the Space
https://odzkskevi.qnssl.com/7dfb262544887eff6fb35bfb444759d6?v=1502084197 做法是类似于最大割之类的东西,把每个碎片按照按钮拆点 ...
- 导航控制器里边添加UIScrollView (automaticallyAdjustsScrollViewInsets)
导航控制器里边如果添加UIScrollView会导致放大操作异常怪异,此时设置 self.automaticallyAdjustsScrollViewInsets = false
- 洛谷 P1501 [国家集训队]Tree II 解题报告
P1501 [国家集训队]Tree II 题目描述 一棵\(n\)个点的树,每个点的初始权值为\(1\).对于这棵树有\(q\)个操作,每个操作为以下四种操作之一: + u v c:将\(u\)到\( ...
- 十五分钟介绍 Redis数据结构--学习笔记
下面是一个对Redis官方文档<A fifteen minute introduction to Redis data types>一文的翻译,如其题目所言,此文目的在于让一个初学者能通过 ...
- 高性能相关、Scrapy框架
高性能相关 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. import requests def fetch_async(url): ...
- 《javascript高级程序设计(第3版)》-1
javascript有下列三个不同的部分组成: ECMAScript,由ECMA-262定义,提供核心语言功能 文档对象模型(DOM),提供访问和操作网页内容的方法和接口 浏览器对象模型(BOM),提 ...
- 5种网络通信设计模型(也称IO模型)
1.基本概念 同步:同步函数一般指调用函数后,等到函数功能实现再返回,期间一直霸占的CPU,等待期间同一个线程无法执行其他函数 异步:异步函数指调用函数后,不管函数功能是否实现,立马返回:通过回调函数 ...
- cmd编译java程序出现:找不到或无法加载主类的原因以及解决办法 以及 给java的main方法传递args参数
原因: 1.java源程序中没有主类main方法. 2.java源程序中包含有eclipse等IDE工具生成的package包. 解决办法(对应以上的原因): 1.运行含有main的类 2.将java ...
- [DeeplearningAI笔记]序列模型2.9情感分类
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.9 Sentiment classification 情感分类 情感分类任务简单来说是看一段文本,然后分辨这个人是否喜欢 ...