01布尔模型&倒排索引
原文链接: http://www.cnblogs.com/jacklu/p/8379726.html
博士一年级选了这门课 SEEM 5680 Text Mining Models and Applications,记下来以便以后查阅。
1. 信息检索的布尔模型
用0和1表示某个词是否出现在文档中。如下图例子,要回答“Brutus AND Caesar but NOT Calpurnia”,我们需要对词的向量做布尔运算,即110100 AND 110111 AND 101111=100100 对应的文档是Antony and Cleopatra和Hamlet

然而这种方法随着数据的增大是非常耗费空间的。比如我们有100万个文档,每个文档平均有1000字,总共有50万个不同的词语,那么矩阵将是500 000 x 1 000 000。这个矩阵是稀疏的,1的个数一般不会超过1亿个。
2. 倒排索引
倒排索引是为了解决上述布尔模型的问题。具体来说,每个词用链表顺序存储文档编号。如下图所示:
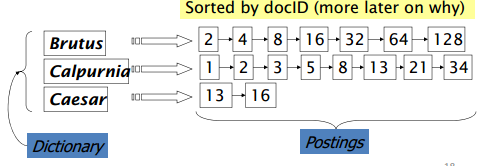
建立索引的核心是将词按字母顺序排列,合并重复词,但是要记录词频。
3. 倒排索引模型中对查询语句(AND)的处理
1、求Brutus AND Calpurnia,即求两个链表的交集。

算法思路是如果文档号不同就移动较小的指针,伪代码 INTERSECTION(p1, p2):
answer<-()
while p1 != NIL and p2 != NIL
do if docID(p1) = docID(p2)
then ADD(answer, docID(p1))
p1 <-next(p1)
p2 <-next(p2)
else if docID(p1) < docID(p2)
p1 <-next(p1)
else p2<-next(p2)
return answer
思考题,有两个词项A,B,其文档编号链表长度分别为3和5,那么对A,B求交集,最少的访问次数和最多的访问次数分别是多少?各举一个例子
最少访问次数是4,比如A:1-2-3,B:3-4-5-6-7;最多访问次数是8,比如A:1-7-8, B:3-4-5-7-9
2、思考题:求Brutus OR Calpurnia,即求两个链表的并集。伪代码 UNION(p1,p2):
answer<-()
while p1 != NIL and p2 != NIL
do if docID(p1) = docID(p2)
then ADD(answer, docID(p1))
p1 <-next(p1)
p2 <-next(p2)
else if docID(p1) < docID(p2)
then ADD(answer, docID(p1))
p1<-next(p1)
else ADD(answer, docID(p2))
p2<-next(p2)
return answer
3、思考题:求Brutus AND NOT Calpurnia。伪代码 INTERSECTION(p1,p2, AND NOT):
answer<-()
while p1 != NIL and p2 != NIL
do if docID(p1) = docID(p2)
p1 <-next(p1)
p2 <-next(p2)
else if docID(p1) < docID(p2)
then ADD(answer, docID(p1))
p1<-next(p1)
else p2<-next(p2) if p1 != NIL and P2 = NIL
then ADD(answer, docID(p1))
p1<-next(p1)
return answer
参考资料:http://www1.se.cuhk.edu.hk/~seem5680/
01布尔模型&倒排索引的更多相关文章
- Dubble 01 架构模型&start project
Dubbo 01 架构模型 传统架构 All in One 测试麻烦,微小修改 全都得重新测 单体架构也称之为单体系统或者是单体应用.就是一种把系统中所有的功能.模块耦合在一个应用中的架构方式.其优点 ...
- 【再探backbone 01】模型-Model
前言 点保存时候不注意发出来了,有需要的朋友将就看吧,还在更新...... 几个月前学习了一下backbone,这段时间也用了下,感觉之前对backbone的学习很是基础,前几天有个园友问我如何将路由 ...
- (01)odoo模型中调用窗体动作
*模型代码 addons/stock/stock.py ---------------- #移库单执行移库动作(弹出详细框) @api.cr_uid_ids_context def ...
- 文本信息检索——布尔模型和TF-IDF模型
文本信息检索--布尔模型和TF-IDF模型 1. 布尔模型 如要检索"布尔检索"或"概率检索"但不包括"向量检索"方面的文档,其相应的查 ...
- 原创:史上对BM25模型最全面最深刻的解读以及lucene排序深入讲解
垂直搜索结果的优化包括对搜索结果的控制和排序优化两方面,其中排序又是重中之重.本文将全面深入探讨垂直搜索的排序模型的演化过程,最后推导出BM25模型的排序.然后将演示如何修改lucene的排序源代码, ...
- 推荐排序---Learning to Rank:从 pointwise 和 pairwise 到 listwise,经典模型与优缺点
转载:https://blog.csdn.net/lipengcn/article/details/80373744 Ranking 是信息检索领域的基本问题,也是搜索引擎背后的重要组成模块. 本文将 ...
- 数据分析之客户价值模型(RFM)技术总结
作者 | leo 管理学中有一个重要概念那就是客户关系管理(CRM),它核心目的就是为了提高企业的核心竞争力,通过提高企业与客户间的交互,优化客户管理方式,从而实现吸引新客户.保留老客户以及将已有客户 ...
- 概率检索模型及BM25
概率排序原理 以往的向量空间模型是将query和文档使用向量表示然后计算其内容相似性来进行相关性估计的,而概率检索模型是一种直接对用户需求进行相关性的建模方法,一个query进来,将所有的文档分为两类 ...
- 学习笔记TF049:TensorFlow 模型存储加载、队列线程、加载数据、自定义操作
生成检查点文件(chekpoint file),扩展名.ckpt,tf.train.Saver对象调用Saver.save()生成.包含权重和其他程序定义变量,不包含图结构.另一程序使用,需要重新创建 ...
随机推荐
- IIS部署时未能加载程序集"System.Web.Http.WebHost"解决方法
问题如下 服务器没有安装MVC,下载以下dll覆盖到bin目录下,即可免安装运行程序. 下载地址:https://pan.baidu.com/s/1mhCo5mS
- 【前端学习笔记】arguments相关
arguments转数组: (function() { console.log(arguments instanceof Array); // --> false console.log(Obj ...
- bzoj2013[CEOI2010] A huge tower
题意 有N(2<=N<=620000)快砖,要搭一个N层的塔,要求:如果砖A恰好在砖B上面,那么A不能比B的长度+D要长.问有几种方法,输出 答案 mod 1000000009的值 分析 ...
- linux服务之NTP时间服务器
1. NTP简介 NTP(Network Time Protocol,网络时间协议)是用来使网络中的各个计算机时间同步的一种协议.它的用途是把计算机的时钟同步到世界协调时UTC,其精度在局域网内可达0 ...
- 升级系统后maxvim不能用,重新下载编译个
1. 获取macvim源代码git clone https://github.com/b4winckler/macvim.git 2 配置及编译 编译选项 ./configure --with-fea ...
- Codeforces 585.D Lizard Era: Beginning
D. Lizard Era: Beginning time limit per test 2 seconds memory limit per test 256 megabytes input sta ...
- ubuntu如何杀死进程
一.得到所有进程 先用命令查询出所有进程 ps -ef 二.杀死进程 我们使用ps -ef命令之后,就会得到一些列进程信息,有进程pid什么的,如果你要杀死莫个进程的话,直接使用命令 kill ...
- windows下libcurl与zlib和ssl共同编译
下载了curl 7.37,在project里有各个版本VS对应的项目文件,我们选择合适的打开即可以编译,根据不同的项目配置输出想要的库,比如可以切换多种SSL库,dll/lib,debug/relea ...
- codeblocks 设置代码自动补全
熟悉使用一些开发类IDE的朋友对代码自动补全一定印象深刻,如Visual studio,eclipse等,我们在程序中定义的那一个个超长的变量函数名只需打出几个字母就可自动补全,但是在codebloc ...
- Centos7系统环境下Solr之Java实战(二)制定中文分析器、配置业务域
制定中文分析器 1.把IKAnalyzer2012FF_u1.jar添加到solr工程的lib目录下 2.把扩展词典.配置文件放到solr工程的WEB-INF/classes目录下. 配置一个Fiel ...